 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInSaAF: Incorporating Safety through Accuracy and Fairness | Are LLMs ready for the Indian Legal Domain?
Feb 21, 2024



Recent advancements in language technology and Artificial Intelligence have resulted in numerous Language Models being proposed to perform various tasks in the legal domain ranging from predicting judgments to generating summaries. Despite their immense potential, these models have been proven to learn and exhibit societal biases and make unfair predictions. In this study, we explore the ability of Large Language Models (LLMs) to perform legal tasks in the Indian landscape when social factors are involved. We present a novel metric, $\beta$-weighted $\textit{Legal Safety Score ($LSS_{\beta}$)}$, which encapsulates both the fairness and accuracy aspects of the LLM. We assess LLMs' safety by considering its performance in the $\textit{Binary Statutory Reasoning}$ task and its fairness exhibition with respect to various axes of disparities in the Indian society. Task performance and fairness scores of LLaMA and LLaMA--2 models indicate that the proposed $LSS_{\beta}$ metric can effectively determine the readiness of a model for safe usage in the legal sector. We also propose finetuning pipelines, utilising specialised legal datasets, as a potential method to mitigate bias and improve model safety. The finetuning procedures on LLaMA and LLaMA--2 models increase the $LSS_{\beta}$, improving their usability in the Indian legal domain. Our code is publicly released.
Key-phrase boosted unsupervised summary generation for FinTech organization
Oct 16, 2023



With the recent advances in social media, the use of NLP techniques in social media data analysis has become an emerging research direction. Business organizations can particularly benefit from such an analysis of social media discourse, providing an external perspective on consumer behavior. Some of the NLP applications such as intent detection, sentiment classification, text summarization can help FinTech organizations to utilize the social media language data to find useful external insights and can be further utilized for downstream NLP tasks. Particularly, a summary which highlights the intents and sentiments of the users can be very useful for these organizations to get an external perspective. This external perspective can help organizations to better manage their products, offers, promotional campaigns, etc. However, certain challenges, such as a lack of labeled domain-specific datasets impede further exploration of these tasks in the FinTech domain. To overcome these challenges, we design an unsupervised phrase-based summary generation from social media data, using 'Action-Object' pairs (intent phrases). We evaluated the proposed method with other key-phrase based summary generation methods in the direction of contextual information of various Reddit discussion threads, available in the different summaries. We introduce certain "Context Metrics" such as the number of Unique words, Action-Object pairs, and Noun chunks to evaluate the contextual information retrieved from the source text in these phrase-based summaries. We demonstrate that our methods significantly outperform the baseline on these metrics, thus providing a qualitative and quantitative measure of their efficacy. Proposed framework has been leveraged as a web utility portal hosted within Amex.
Are Models Trained on Indian Legal Data Fair?
Mar 14, 2023



Recent advances and applications of language technology and artificial intelligence have enabled much success across multiple domains like law, medical and mental health. AI-based Language Models, like Judgement Prediction, have recently been proposed for the legal sector. However, these models are strife with encoded social biases picked up from the training data. While bias and fairness have been studied across NLP, most studies primarily locate themselves within a Western context. In this work, we present an initial investigation of fairness from the Indian perspective in the legal domain. We highlight the propagation of learnt algorithmic biases in the bail prediction task for models trained on Hindi legal documents. We evaluate the fairness gap using demographic parity and show that a decision tree model trained for the bail prediction task has an overall fairness disparity of 0.237 between input features associated with Hindus and Muslims. Additionally, we highlight the need for further research and studies in the avenues of fairness/bias in applying AI in the legal sector with a specific focus on the Indian context.
IndicXTREME: A Multi-Task Benchmark For Evaluating Indic Languages
Dec 13, 2022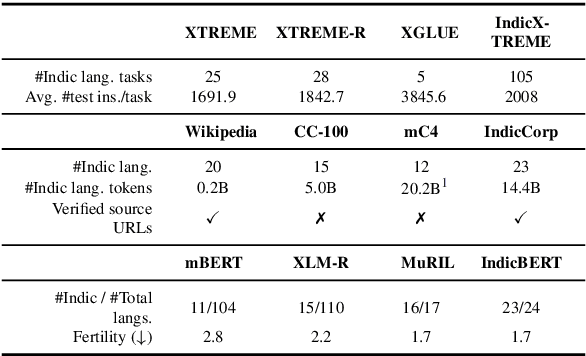
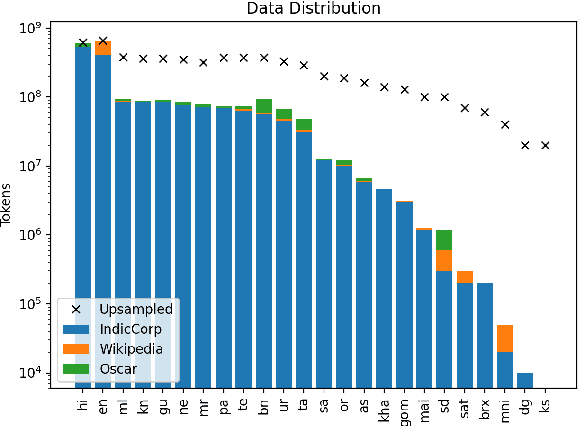
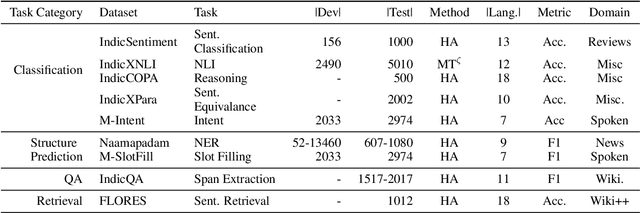
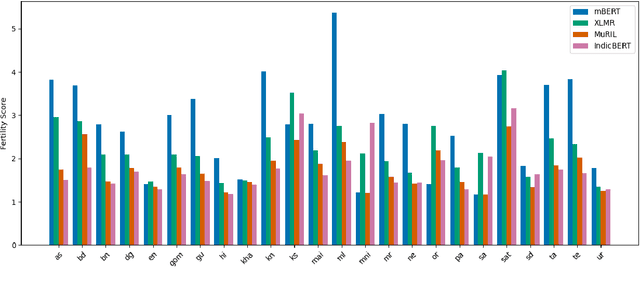
In this work, we introduce IndicXTREME, a benchmark consisting of nine diverse tasks covering 18 languages from the Indic sub-continent belonging to four different families. Across languages and tasks, IndicXTREME contains a total of 103 evaluation sets, of which 51 are new contributions to the literature. To maintain high quality, we only use human annotators to curate or translate our datasets. To the best of our knowledge, this is the first effort toward creating a standard benchmark for Indic languages that aims to test the zero-shot capabilities of pretrained language models. We also release IndicCorp v2, an updated and much larger version of IndicCorp that contains 20.9 billion tokens in 24 languages. We pretrain IndicBERT v2 on IndicCorp v2 and evaluate it on IndicXTREME to show that it outperforms existing multilingual language models such as XLM-R and MuRIL.
A survey in Adversarial Defences and Robustness in NLP
Apr 12, 2022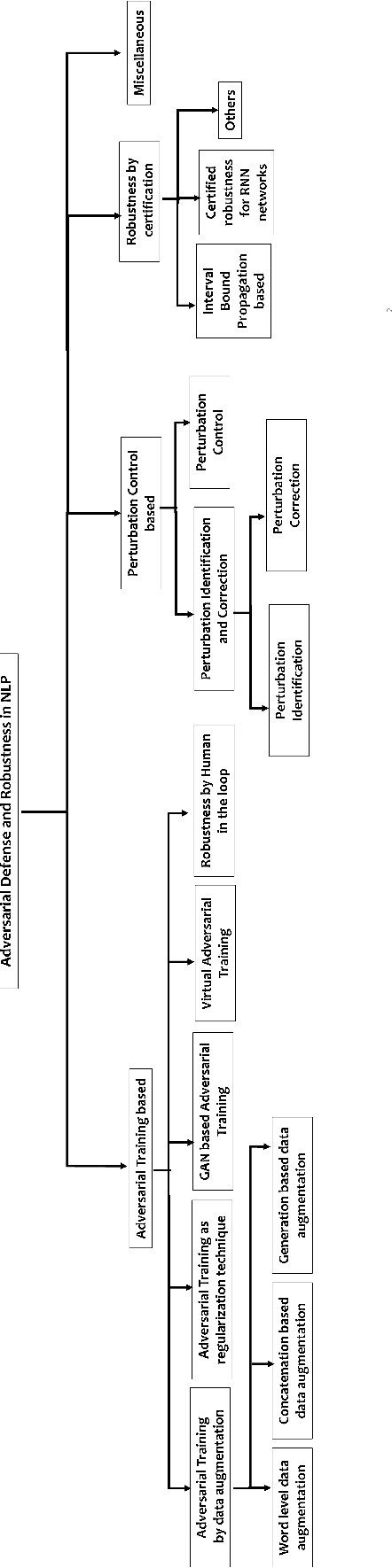
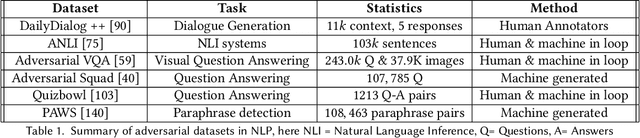
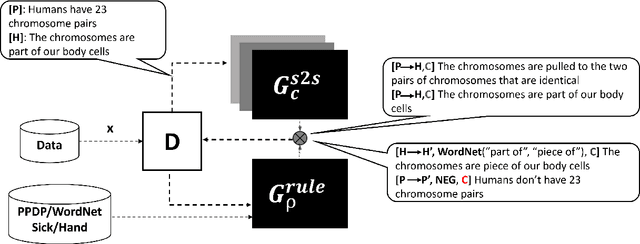

In recent years, it has been seen that deep neural networks are lacking robustness and are likely to break in case of adversarial perturbations in input data. Strong adversarial attacks are proposed by various authors for computer vision and Natural Language Processing (NLP). As a counter-effort, several defense mechanisms are also proposed to save these networks from failing. In contrast with image data, generating adversarial attacks and defending these models is not easy in NLP because of the discrete nature of the text data. However, numerous methods for adversarial defense are proposed of late, for different NLP tasks such as text classification, named entity recognition, natural language inferencing, etc. These methods are not just used for defending neural networks from adversarial attacks, but also used as a regularization mechanism during training, saving the model from overfitting. The proposed survey is an attempt to review different methods proposed for adversarial defenses in NLP in the recent past by proposing a novel taxonomy. This survey also highlights the fragility of the advanced deep neural networks in NLP and the challenges in defending them.
Knowledge driven Description Synthesis for Floor Plan Interpretation
Mar 15, 2021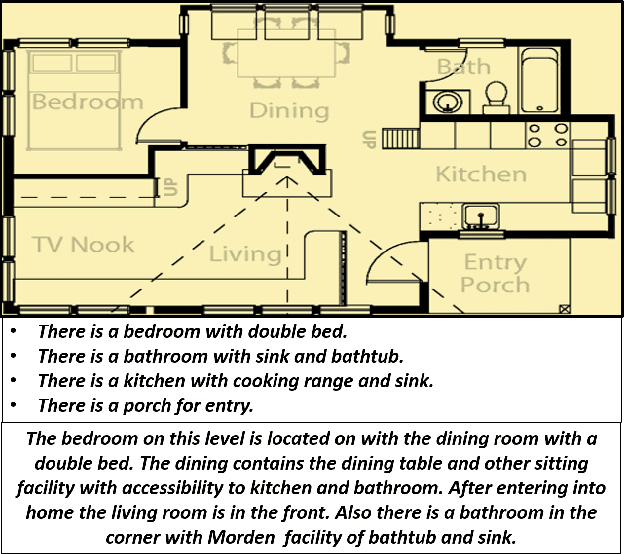
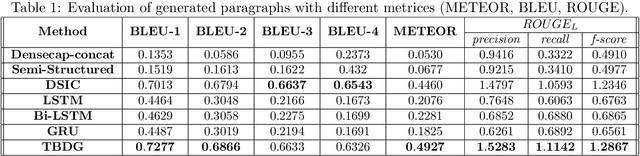
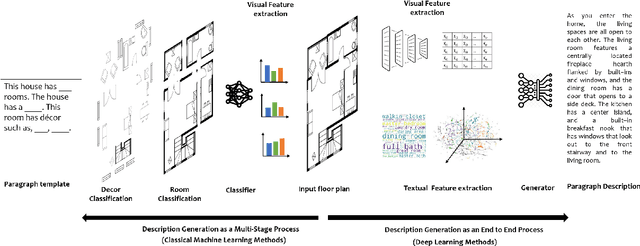
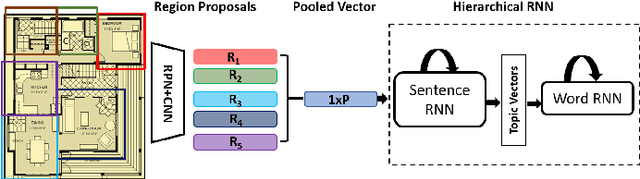
Image captioning is a widely known problem in the area of AI. Caption generation from floor plan images has applications in indoor path planning, real estate, and providing architectural solutions. Several methods have been explored in literature for generating captions or semi-structured descriptions from floor plan images. Since only the caption is insufficient to capture fine-grained details, researchers also proposed descriptive paragraphs from images. However, these descriptions have a rigid structure and lack flexibility, making it difficult to use them in real-time scenarios. This paper offers two models, Description Synthesis from Image Cue (DSIC) and Transformer Based Description Generation (TBDG), for the floor plan image to text generation to fill the gaps in existing methods. These two models take advantage of modern deep neural networks for visual feature extraction and text generation. The difference between both models is in the way they take input from the floor plan image. The DSIC model takes only visual features automatically extracted by a deep neural network, while the TBDG model learns textual captions extracted from input floor plan images with paragraphs. The specific keywords generated in TBDG and understanding them with paragraphs make it more robust in a general floor plan image. Experiments were carried out on a large-scale publicly available dataset and compared with state-of-the-art techniques to show the proposed model's superiority.
GRIHA: Synthesizing 2-Dimensional Building Layouts from Images Captured using a Smart Phone
Mar 15, 2021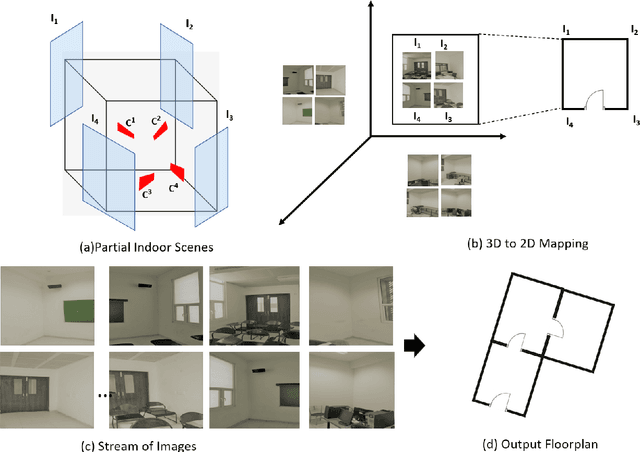



Reconstructing an indoor scene and generating a layout/floor plan in 3D or 2D is a widely known problem. Quite a few algorithms have been proposed in the literature recently. However, most existing methods either use RGB-D images, thus requiring a depth camera, or depending on panoramic photos, assuming that there is little to no occlusion in the rooms. In this work, we proposed GRIHA (Generating Room Interior of a House using ARCore), a framework for generating a layout using an RGB image captured using a simple mobile phone camera. We take advantage of Simultaneous Localization and Mapping (SLAM) to assess the 3D transformations required for layout generation. SLAM technology is built-in in recent mobile libraries such as ARCore by Google. Hence, the proposed method is fast and efficient. It gives the user freedom to generate layout by merely taking a few conventional photos, rather than relying on specialized depth hardware or occlusion-free panoramic images. We have compared GRIHA with other existing methods and obtained superior results. Also, the system is tested on multiple hardware platforms to test the dependency and efficiency.
Automatic Rendering of Building Floor Plan Images from Textual Descriptions in English
Nov 29, 2018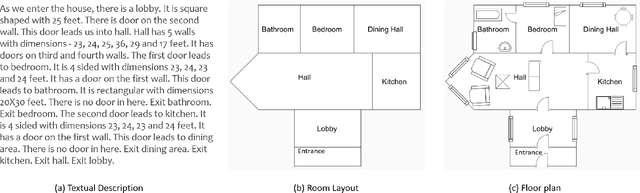
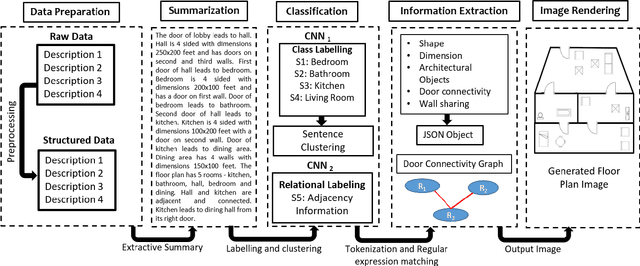
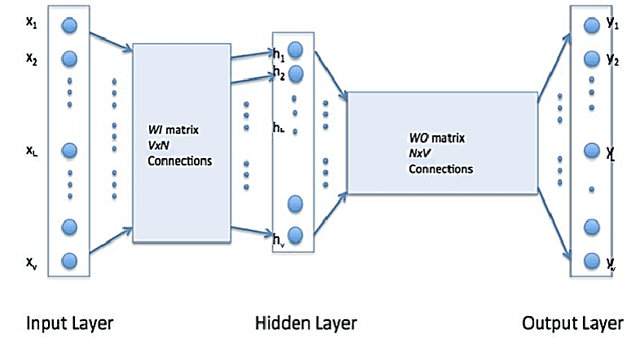
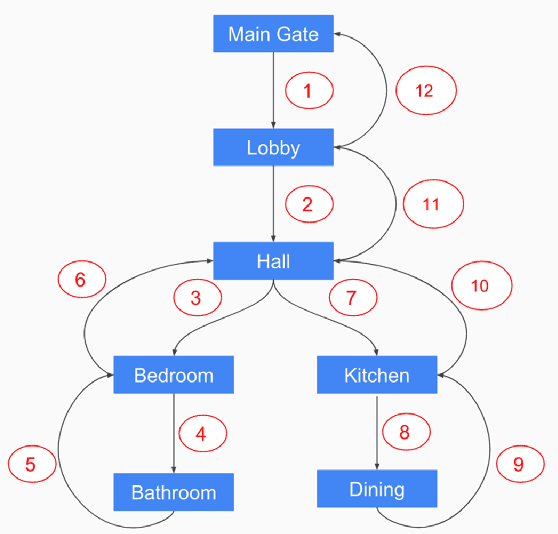
Human beings understand natural language description and could able to imagine a corresponding visual for the same. For example, given a description of the interior of a house, we could imagine its structure and arrangements of furniture. Automatic synthesis of real-world images from text descriptions has been explored in the computer vision community. However, there is no such attempt in the area of document images, like floor plans. Floor plan synthesis from sketches, as well as data-driven models, were proposed earlier. Ours is the first attempt to render building floor plan images from textual description automatically. Here, the input is a natural language description of the internal structure and furniture arrangements within a house, and the output is the 2D floor plan image of the same. We have experimented on publicly available benchmark floor plan datasets. We were able to render realistic synthesized floor plan images from the description written in English.
SUGAMAN: Describing Floor Plans for Visually Impaired by Annotation Learning and Proximity based Grammar
Nov 14, 2018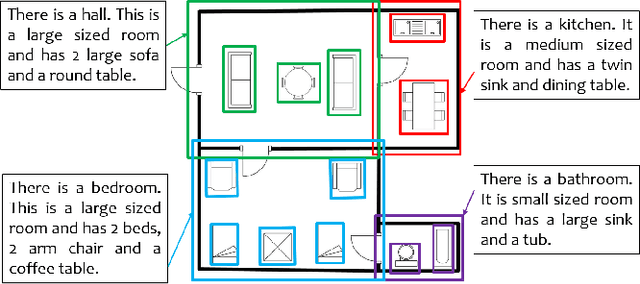
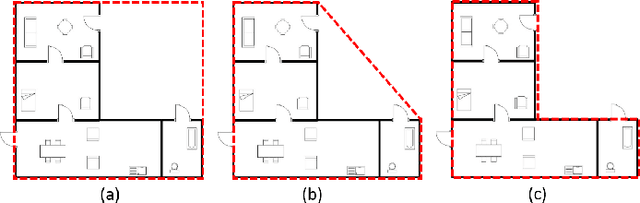
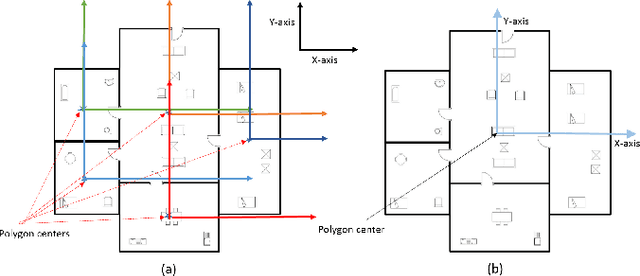
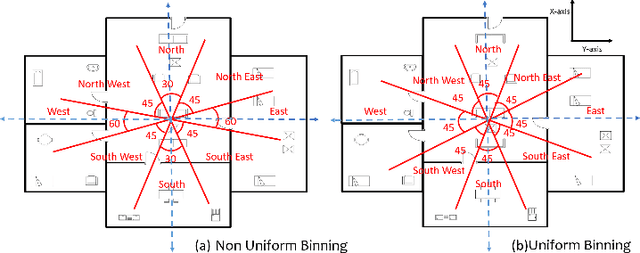
In this paper, we propose SUGAMAN (Supervised and Unified framework using Grammar and Annotation Model for Access and Navigation). SUGAMAN is a Hindi word meaning "easy passage from one place to another". SUGAMAN synthesizes textual description from a given floor plan image for the visually impaired. A visually impaired person can navigate in an indoor environment using the textual description generated by SUGAMAN. With the help of a text reader software, the target user can understand the rooms within the building and arrangement of furniture to navigate. SUGAMAN is the first framework for describing a floor plan and giving direction for obstacle-free movement within a building. We learn $5$ classes of room categories from $1355$ room image samples under a supervised learning paradigm. These learned annotations are fed into a description synthesis framework to yield a holistic description of a floor plan image. We demonstrate the performance of various supervised classifiers on room learning. We also provide a comparative analysis of system generated and human written descriptions. SUGAMAN gives state of the art performance on challenging, real-world floor plan images. This work can be applied to areas like understanding floor plans of historical monuments, stability analysis of buildings, and retrieval.