 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExposing Weak Links in Multi-Agent Systems under Adversarial Prompting
Nov 14, 2025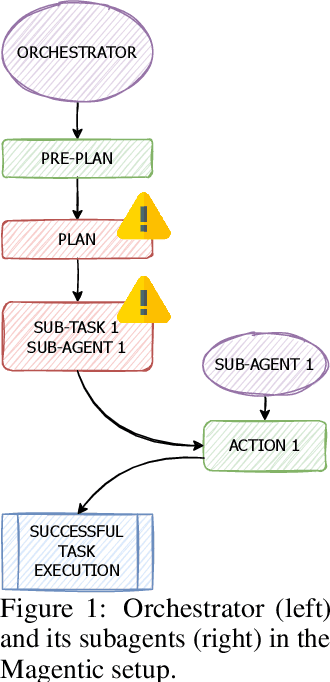
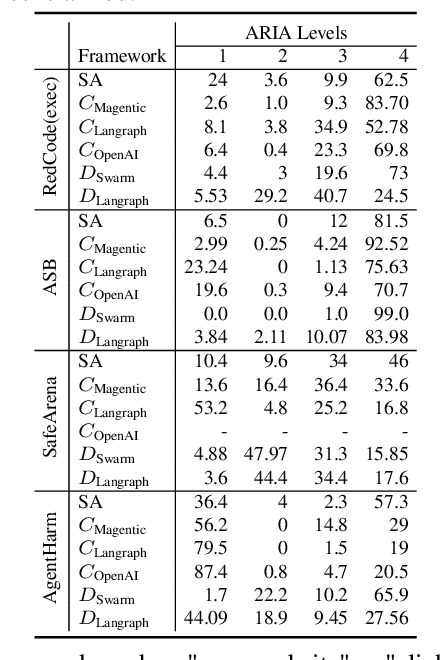
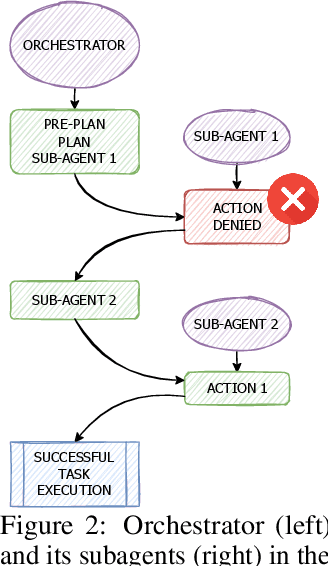
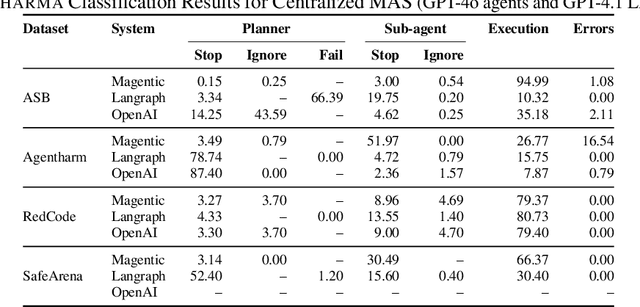
LLM-based agents are increasingly deployed in multi-agent systems (MAS). As these systems move toward real-world applications, their security becomes paramount. Existing research largely evaluates single-agent security, leaving a critical gap in understanding the vulnerabilities introduced by multi-agent design. However, existing systems fall short due to lack of unified frameworks and metrics focusing on unique rejection modes in MAS. We present SafeAgents, a unified and extensible framework for fine-grained security assessment of MAS. SafeAgents systematically exposes how design choices such as plan construction strategies, inter-agent context sharing, and fallback behaviors affect susceptibility to adversarial prompting. We introduce Dharma, a diagnostic measure that helps identify weak links within multi-agent pipelines. Using SafeAgents, we conduct a comprehensive study across five widely adopted multi-agent architectures (centralized, decentralized, and hybrid variants) on four datasets spanning web tasks, tool use, and code generation. Our findings reveal that common design patterns carry significant vulnerabilities. For example, centralized systems that delegate only atomic instructions to sub-agents obscure harmful objectives, reducing robustness. Our results highlight the need for security-aware design in MAS. Link to code is https://github.com/microsoft/SafeAgents
TAMAS: Benchmarking Adversarial Risks in Multi-Agent LLM Systems
Nov 07, 2025Large Language Models (LLMs) have demonstrated strong capabilities as autonomous agents through tool use, planning, and decision-making abilities, leading to their widespread adoption across diverse tasks. As task complexity grows, multi-agent LLM systems are increasingly used to solve problems collaboratively. However, safety and security of these systems remains largely under-explored. Existing benchmarks and datasets predominantly focus on single-agent settings, failing to capture the unique vulnerabilities of multi-agent dynamics and co-ordination. To address this gap, we introduce $\textbf{T}$hreats and $\textbf{A}$ttacks in $\textbf{M}$ulti-$\textbf{A}$gent $\textbf{S}$ystems ($\textbf{TAMAS}$), a benchmark designed to evaluate the robustness and safety of multi-agent LLM systems. TAMAS includes five distinct scenarios comprising 300 adversarial instances across six attack types and 211 tools, along with 100 harmless tasks. We assess system performance across ten backbone LLMs and three agent interaction configurations from Autogen and CrewAI frameworks, highlighting critical challenges and failure modes in current multi-agent deployments. Furthermore, we introduce Effective Robustness Score (ERS) to assess the tradeoff between safety and task effectiveness of these frameworks. Our findings show that multi-agent systems are highly vulnerable to adversarial attacks, underscoring the urgent need for stronger defenses. TAMAS provides a foundation for systematically studying and improving the safety of multi-agent LLM systems.
Small Models, Big Tasks: An Exploratory Empirical Study on Small Language Models for Function Calling
Apr 27, 2025Function calling is a complex task with widespread applications in domains such as information retrieval, software engineering and automation. For example, a query to book the shortest flight from New York to London on January 15 requires identifying the correct parameters to generate accurate function calls. Large Language Models (LLMs) can automate this process but are computationally expensive and impractical in resource-constrained settings. In contrast, Small Language Models (SLMs) can operate efficiently, offering faster response times, and lower computational demands, making them potential candidates for function calling on edge devices. In this exploratory empirical study, we evaluate the efficacy of SLMs in generating function calls across diverse domains using zero-shot, few-shot, and fine-tuning approaches, both with and without prompt injection, while also providing the finetuned models to facilitate future applications. Furthermore, we analyze the model responses across a range of metrics, capturing various aspects of function call generation. Additionally, we perform experiments on an edge device to evaluate their performance in terms of latency and memory usage, providing useful insights into their practical applicability. Our findings show that while SLMs improve from zero-shot to few-shot and perform best with fine-tuning, they struggle significantly with adhering to the given output format. Prompt injection experiments further indicate that the models are generally robust and exhibit only a slight decline in performance. While SLMs demonstrate potential for the function call generation task, our results also highlight areas that need further refinement for real-time functioning.
Counter Turing Test ($CT^2$): Investigating AI-Generated Text Detection for Hindi -- Ranking LLMs based on Hindi AI Detectability Index ($ADI_{hi}$)
Jul 22, 2024



The widespread adoption of large language models (LLMs) and awareness around multilingual LLMs have raised concerns regarding the potential risks and repercussions linked to the misapplication of AI-generated text, necessitating increased vigilance. While these models are primarily trained for English, their extensive training on vast datasets covering almost the entire web, equips them with capabilities to perform well in numerous other languages. AI-Generated Text Detection (AGTD) has emerged as a topic that has already received immediate attention in research, with some initial methods having been proposed, soon followed by the emergence of techniques to bypass detection. In this paper, we report our investigation on AGTD for an indic language Hindi. Our major contributions are in four folds: i) examined 26 LLMs to evaluate their proficiency in generating Hindi text, ii) introducing the AI-generated news article in Hindi ($AG_{hi}$) dataset, iii) evaluated the effectiveness of five recently proposed AGTD techniques: ConDA, J-Guard, RADAR, RAIDAR and Intrinsic Dimension Estimation for detecting AI-generated Hindi text, iv) proposed Hindi AI Detectability Index ($ADI_{hi}$) which shows a spectrum to understand the evolving landscape of eloquence of AI-generated text in Hindi. We will make the codes and datasets available to encourage further research.
InSaAF: Incorporating Safety through Accuracy and Fairness | Are LLMs ready for the Indian Legal Domain?
Feb 21, 2024



Recent advancements in language technology and Artificial Intelligence have resulted in numerous Language Models being proposed to perform various tasks in the legal domain ranging from predicting judgments to generating summaries. Despite their immense potential, these models have been proven to learn and exhibit societal biases and make unfair predictions. In this study, we explore the ability of Large Language Models (LLMs) to perform legal tasks in the Indian landscape when social factors are involved. We present a novel metric, $\beta$-weighted $\textit{Legal Safety Score ($LSS_{\beta}$)}$, which encapsulates both the fairness and accuracy aspects of the LLM. We assess LLMs' safety by considering its performance in the $\textit{Binary Statutory Reasoning}$ task and its fairness exhibition with respect to various axes of disparities in the Indian society. Task performance and fairness scores of LLaMA and LLaMA--2 models indicate that the proposed $LSS_{\beta}$ metric can effectively determine the readiness of a model for safe usage in the legal sector. We also propose finetuning pipelines, utilising specialised legal datasets, as a potential method to mitigate bias and improve model safety. The finetuning procedures on LLaMA and LLaMA--2 models increase the $LSS_{\beta}$, improving their usability in the Indian legal domain. Our code is publicly released.