 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLExT: Towards Evaluating Trustworthiness of Natural Language Explanations
Apr 08, 2025



As Large Language Models (LLMs) become increasingly integrated into high-stakes domains, there have been several approaches proposed toward generating natural language explanations. These explanations are crucial for enhancing the interpretability of a model, especially in sensitive domains like healthcare, where transparency and reliability are key. In light of such explanations being generated by LLMs and its known concerns, there is a growing need for robust evaluation frameworks to assess model-generated explanations. Natural Language Generation metrics like BLEU and ROUGE capture syntactic and semantic accuracies but overlook other crucial aspects such as factual accuracy, consistency, and faithfulness. To address this gap, we propose a general framework for quantifying trustworthiness of natural language explanations, balancing Plausibility and Faithfulness, to derive a comprehensive Language Explanation Trustworthiness Score (LExT) (The code and set up to reproduce our experiments are publicly available at https://github.com/cerai-iitm/LExT). Applying our domain-agnostic framework to the healthcare domain using public medical datasets, we evaluate six models, including domain-specific and general-purpose models. Our findings demonstrate significant differences in their ability to generate trustworthy explanations. On comparing these explanations, we make interesting observations such as inconsistencies in Faithfulness demonstrated by general-purpose models and their tendency to outperform domain-specific fine-tuned models. This work further highlights the importance of using a tailored evaluation framework to assess natural language explanations in sensitive fields, providing a foundation for improving the trustworthiness and transparency of language models in healthcare and beyond.
InSaAF: Incorporating Safety through Accuracy and Fairness | Are LLMs ready for the Indian Legal Domain?
Feb 21, 2024



Recent advancements in language technology and Artificial Intelligence have resulted in numerous Language Models being proposed to perform various tasks in the legal domain ranging from predicting judgments to generating summaries. Despite their immense potential, these models have been proven to learn and exhibit societal biases and make unfair predictions. In this study, we explore the ability of Large Language Models (LLMs) to perform legal tasks in the Indian landscape when social factors are involved. We present a novel metric, $\beta$-weighted $\textit{Legal Safety Score ($LSS_{\beta}$)}$, which encapsulates both the fairness and accuracy aspects of the LLM. We assess LLMs' safety by considering its performance in the $\textit{Binary Statutory Reasoning}$ task and its fairness exhibition with respect to various axes of disparities in the Indian society. Task performance and fairness scores of LLaMA and LLaMA--2 models indicate that the proposed $LSS_{\beta}$ metric can effectively determine the readiness of a model for safe usage in the legal sector. We also propose finetuning pipelines, utilising specialised legal datasets, as a potential method to mitigate bias and improve model safety. The finetuning procedures on LLaMA and LLaMA--2 models increase the $LSS_{\beta}$, improving their usability in the Indian legal domain. Our code is publicly released.
LineConGraphs: Line Conversation Graphs for Effective Emotion Recognition using Graph Neural Networks
Dec 04, 2023Emotion Recognition in Conversations (ERC) is a critical aspect of affective computing, and it has many practical applications in healthcare, education, chatbots, and social media platforms. Earlier approaches for ERC analysis involved modeling both speaker and long-term contextual information using graph neural network architectures. However, it is ideal to deploy speaker-independent models for real-world applications. Additionally, long context windows can potentially create confusion in recognizing the emotion of an utterance in a conversation. To overcome these limitations, we propose novel line conversation graph convolutional network (LineConGCN) and graph attention (LineConGAT) models for ERC analysis. These models are speaker-independent and built using a graph construction strategy for conversations -- line conversation graphs (LineConGraphs). The conversational context in LineConGraphs is short-term -- limited to one previous and future utterance, and speaker information is not part of the graph. We evaluate the performance of our proposed models on two benchmark datasets, IEMOCAP and MELD, and show that our LineConGAT model outperforms the state-of-the-art methods with an F1-score of 64.58% and 76.50%. Moreover, we demonstrate that embedding sentiment shift information into line conversation graphs further enhances the ERC performance in the case of GCN models.
Are Models Trained on Indian Legal Data Fair?
Mar 14, 2023



Recent advances and applications of language technology and artificial intelligence have enabled much success across multiple domains like law, medical and mental health. AI-based Language Models, like Judgement Prediction, have recently been proposed for the legal sector. However, these models are strife with encoded social biases picked up from the training data. While bias and fairness have been studied across NLP, most studies primarily locate themselves within a Western context. In this work, we present an initial investigation of fairness from the Indian perspective in the legal domain. We highlight the propagation of learnt algorithmic biases in the bail prediction task for models trained on Hindi legal documents. We evaluate the fairness gap using demographic parity and show that a decision tree model trained for the bail prediction task has an overall fairness disparity of 0.237 between input features associated with Hindus and Muslims. Additionally, we highlight the need for further research and studies in the avenues of fairness/bias in applying AI in the legal sector with a specific focus on the Indian context.
Hybrid Text Feature Modeling for Disease Group Prediction using Unstructured Physician Notes
Nov 26, 2019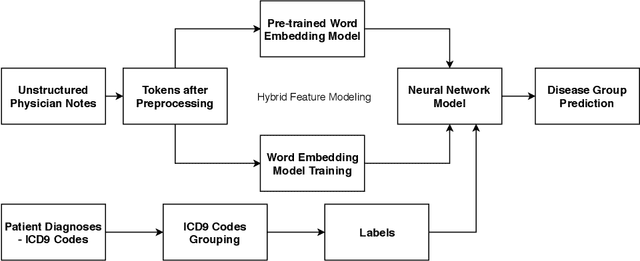



Existing Clinical Decision Support Systems (CDSSs) largely depend on the availability of structured patient data and Electronic Health Records (EHRs) to aid caregivers. However, in case of hospitals in developing countries, structured patient data formats are not widely adopted, where medical professionals still rely on clinical notes in the form of unstructured text. Such unstructured clinical notes recorded by medical personnel can also be a potential source of rich patient-specific information which can be leveraged to build CDSSs, even for hospitals in developing countries. If such unstructured clinical text can be used, the manual and time-consuming process of EHR generation will no longer be required, with huge person-hours and cost savings. In this paper, we propose a generic ICD9 disease group prediction CDSS built on unstructured physician notes modeled using hybrid word embeddings. These word embeddings are used to train a deep neural network for effectively predicting ICD9 disease groups. Experimental evaluation showed that the proposed approach outperformed the state-of-the-art disease group prediction model built on structured EHRs by 15% in terms of AUROC and 40% in terms of AUPRC, thus proving our hypothesis and eliminating dependency on availability of structured patient data.