 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Clinical Diagnosis Performance with Automated X-ray Scan Quality Enhancement Algorithms
Jan 17, 2022In clinical diagnosis, diagnostic images that are obtained from the scanning devices serve as preliminary evidence for further investigation in the process of delivering quality healthcare. However, often the medical image may contain fault artifacts, introduced due to noise, blur and faulty equipment. The reason for this may be the low-quality or older scanning devices, the test environment or technicians lack of training etc; however, the net result is that the process of fast and reliable diagnosis is hampered. Resolving these issues automatically can have a significant positive impact in a hospital clinical workflow, where often, there is no other way but to work with faulty/older equipment or inadequately qualified radiology technicians. In this paper, automated image quality improvement approaches for adapted and benchmarked for the task of medical image super-resolution. During experimental evaluation on standard open datasets, the observations showed that certain algorithms perform better and show significant improvement in the diagnostic quality of medical scans, thereby enabling better visualization for human diagnostic purposes.
* Presented and Accepted in International Conference on Advances in Systems, Control and Computing (AISCC-2020) at Malaviya National Institute of Technology, Jaipur, India, February 27-28, 2020
A Bag of Visual Words Model for Medical Image Retrieval
Jul 18, 2020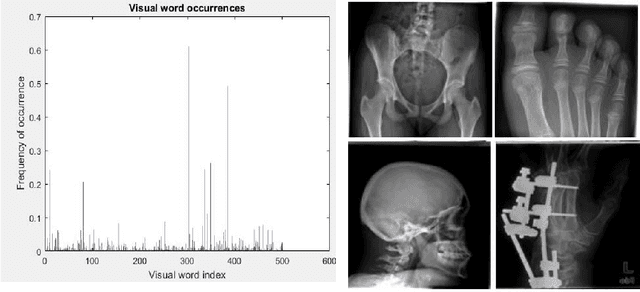
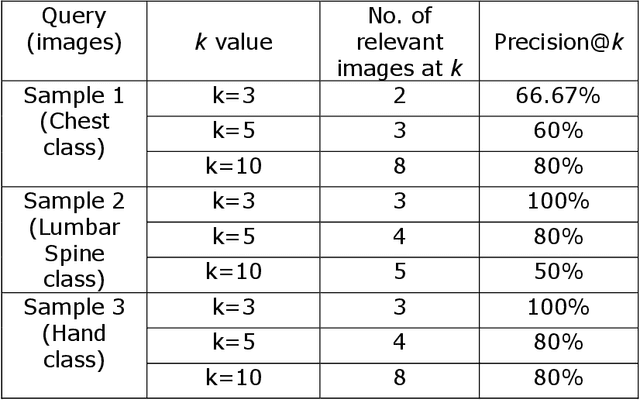
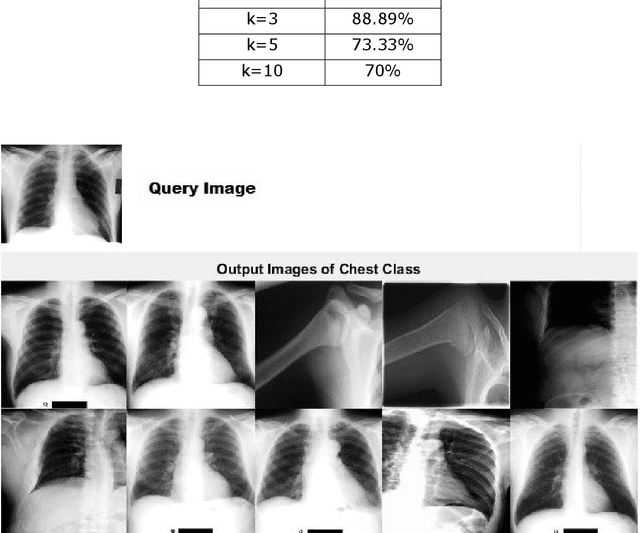
Medical Image Retrieval is a challenging field in Visual information retrieval, due to the multi-dimensional and multi-modal context of the underlying content. Traditional models often fail to take the intrinsic characteristics of data into consideration, and have thus achieved limited accuracy when applied to medical images. The Bag of Visual Words (BoVW) is a technique that can be used to effectively represent intrinsic image features in vector space, so that applications like image classification and similar-image search can be optimized. In this paper, we present a MedIR approach based on the BoVW model for content-based medical image retrieval. As medical images as multi-dimensional, they exhibit underlying cluster and manifold information which enhances semantic relevance and allows for label uniformity. Hence, the BoVW features extracted for each image are used to train a supervised machine learning classifier based on positive and negative training images, for extending content based image retrieval. During experimental validation, the proposed model performed very well, achieving a Mean Average Precision of 88.89% during top-3 image retrieval experiments.
Leveraging Multimodal Behavioral Analytics for Automated Job Interview Performance Assessment and Feedback
Jun 16, 2020
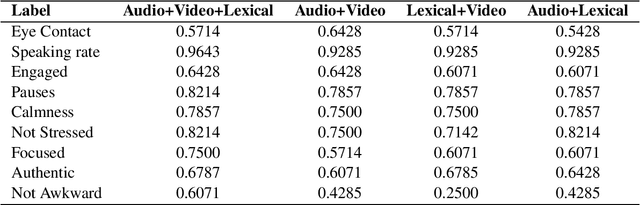
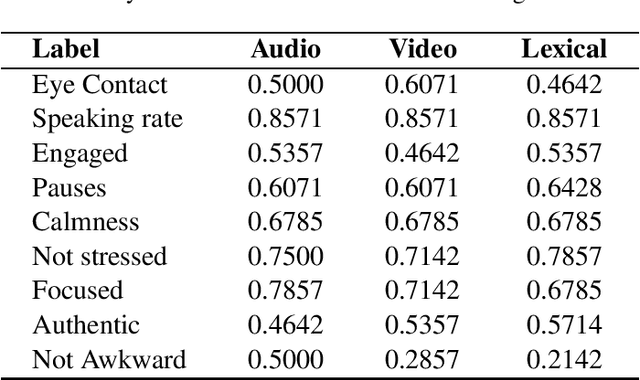

Behavioral cues play a significant part in human communication and cognitive perception. In most professional domains, employee recruitment policies are framed such that both professional skills and personality traits are adequately assessed. Hiring interviews are structured to evaluate expansively a potential employee's suitability for the position - their professional qualifications, interpersonal skills, ability to perform in critical and stressful situations, in the presence of time and resource constraints, etc. Therefore, candidates need to be aware of their positive and negative attributes and be mindful of behavioral cues that might have adverse effects on their success. We propose a multimodal analytical framework that analyzes the candidate in an interview scenario and provides feedback for predefined labels such as engagement, speaking rate, eye contact, etc. We perform a comprehensive analysis that includes the interviewee's facial expressions, speech, and prosodic information, using the video, audio, and text transcripts obtained from the recorded interview. We use these multimodal data sources to construct a composite representation, which is used for training machine learning classifiers to predict the class labels. Such analysis is then used to provide constructive feedback to the interviewee for their behavioral cues and body language. Experimental validation showed that the proposed methodology achieved promising results.
Hybrid Text Feature Modeling for Disease Group Prediction using Unstructured Physician Notes
Nov 26, 2019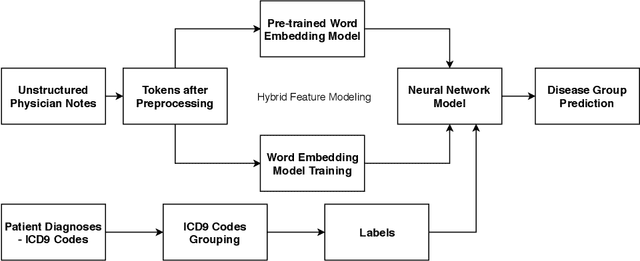



Existing Clinical Decision Support Systems (CDSSs) largely depend on the availability of structured patient data and Electronic Health Records (EHRs) to aid caregivers. However, in case of hospitals in developing countries, structured patient data formats are not widely adopted, where medical professionals still rely on clinical notes in the form of unstructured text. Such unstructured clinical notes recorded by medical personnel can also be a potential source of rich patient-specific information which can be leveraged to build CDSSs, even for hospitals in developing countries. If such unstructured clinical text can be used, the manual and time-consuming process of EHR generation will no longer be required, with huge person-hours and cost savings. In this paper, we propose a generic ICD9 disease group prediction CDSS built on unstructured physician notes modeled using hybrid word embeddings. These word embeddings are used to train a deep neural network for effectively predicting ICD9 disease groups. Experimental evaluation showed that the proposed approach outperformed the state-of-the-art disease group prediction model built on structured EHRs by 15% in terms of AUROC and 40% in terms of AUPRC, thus proving our hypothesis and eliminating dependency on availability of structured patient data.
Proximal Policy Optimization for Improved Convergence in IRGAN
Oct 01, 2019


IRGAN is an information retrieval (IR) modeling approach that uses a theoretical minimax game between a generative and a discriminative model to iteratively optimize both of them, hence unifying the generative and discriminative approaches. Despite significant performance improvements in several information retrieval tasks, IRGAN training is an unstable process, and the solution varies largely with the random parameter initialization. In this work, we present an improved training objective based on proximal policy optimization objective and Gumbel-Softmax based sampling for the generator. We also propose a modified training algorithm which takes a single gradient update on both the generator as well as discriminator for each iteration step. We present empirical evidence of the improved convergence of the proposed model over the original IRGAN and a comparison on three different IR tasks on benchmark datasets is also discussed, emphasizing the proposed model's superior performance.