 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
GLIDER: Grading LLM Interactions and Decisions using Explainable Ranking
Dec 18, 2024



The LLM-as-judge paradigm is increasingly being adopted for automated evaluation of model outputs. While LLM judges have shown promise on constrained evaluation tasks, closed source LLMs display critical shortcomings when deployed in real world applications due to challenges of fine grained metrics and explainability, while task specific evaluation models lack cross-domain generalization. We introduce GLIDER, a powerful 3B evaluator LLM that can score any text input and associated context on arbitrary user defined criteria. GLIDER shows higher Pearson's correlation than GPT-4o on FLASK and greatly outperforms prior evaluation models, achieving comparable performance to LLMs 17x its size. GLIDER supports fine-grained scoring, multilingual reasoning, span highlighting and was trained on 685 domains and 183 criteria. Extensive qualitative analysis shows that GLIDER scores are highly correlated with human judgments, with 91.3% human agreement. We have open-sourced GLIDER to facilitate future research.
INCLUDE: Evaluating Multilingual Language Understanding with Regional Knowledge
Nov 29, 2024



The performance differential of large language models (LLM) between languages hinders their effective deployment in many regions, inhibiting the potential economic and societal value of generative AI tools in many communities. However, the development of functional LLMs in many languages (\ie, multilingual LLMs) is bottlenecked by the lack of high-quality evaluation resources in languages other than English. Moreover, current practices in multilingual benchmark construction often translate English resources, ignoring the regional and cultural knowledge of the environments in which multilingual systems would be used. In this work, we construct an evaluation suite of 197,243 QA pairs from local exam sources to measure the capabilities of multilingual LLMs in a variety of regional contexts. Our novel resource, INCLUDE, is a comprehensive knowledge- and reasoning-centric benchmark across 44 written languages that evaluates multilingual LLMs for performance in the actual language environments where they would be deployed.
Lynx: An Open Source Hallucination Evaluation Model
Jul 11, 2024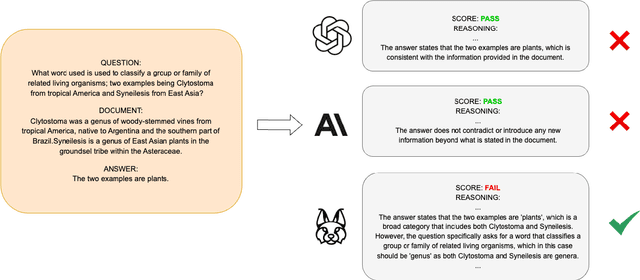
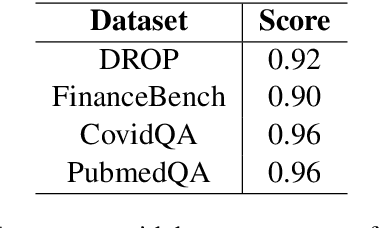
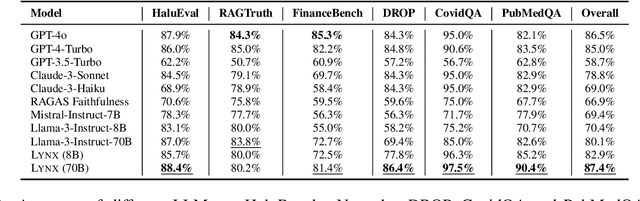
Retrieval Augmented Generation (RAG) techniques aim to mitigate hallucinations in Large Language Models (LLMs). However, LLMs can still produce information that is unsupported or contradictory to the retrieved contexts. We introduce LYNX, a SOTA hallucination detection LLM that is capable of advanced reasoning on challenging real-world hallucination scenarios. To evaluate LYNX, we present HaluBench, a comprehensive hallucination evaluation benchmark, consisting of 15k samples sourced from various real-world domains. Our experiment results show that LYNX outperforms GPT-4o, Claude-3-Sonnet, and closed and open-source LLM-as-a-judge models on HaluBench. We release LYNX, HaluBench and our evaluation code for public access.
Leveraging Multimodal Behavioral Analytics for Automated Job Interview Performance Assessment and Feedback
Jun 16, 2020
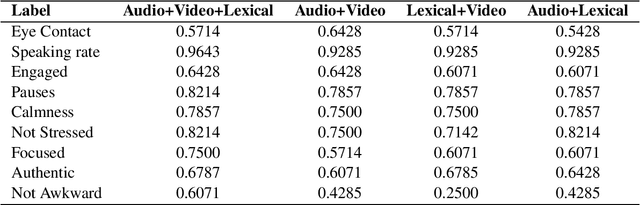
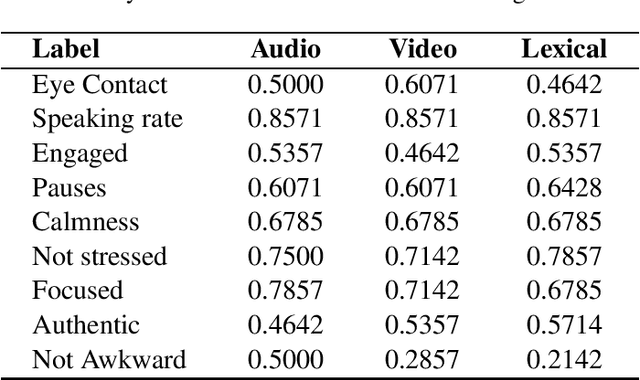

Behavioral cues play a significant part in human communication and cognitive perception. In most professional domains, employee recruitment policies are framed such that both professional skills and personality traits are adequately assessed. Hiring interviews are structured to evaluate expansively a potential employee's suitability for the position - their professional qualifications, interpersonal skills, ability to perform in critical and stressful situations, in the presence of time and resource constraints, etc. Therefore, candidates need to be aware of their positive and negative attributes and be mindful of behavioral cues that might have adverse effects on their success. We propose a multimodal analytical framework that analyzes the candidate in an interview scenario and provides feedback for predefined labels such as engagement, speaking rate, eye contact, etc. We perform a comprehensive analysis that includes the interviewee's facial expressions, speech, and prosodic information, using the video, audio, and text transcripts obtained from the recorded interview. We use these multimodal data sources to construct a composite representation, which is used for training machine learning classifiers to predict the class labels. Such analysis is then used to provide constructive feedback to the interviewee for their behavioral cues and body language. Experimental validation showed that the proposed methodology achieved promising results.