 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDefenses & Enablers For Skill Injection Attacks on Terminal Based Agents
Jun 01, 2026Large language model (LLM) agents increasingly rely on reusable skills i.e. documents describing task-specific procedures. However, this introduces a new attack surface for agents to manage. We study two complementary directions for this threat. First, we evaluate guardian-based defenses: an intermediary LLM agent that acts as a mediator for skill file access (dynamic guardian) or pre-rewrites these files at build time (static guardian). Across three LLM agent families, our guardians cut attack success rate (ASR) by well over half while preserving task utility. Second, we stress test them through attack reframing using four attacks that preserve the malicious instruction but change the phrasing. For non-guardian setup, the reframing pushes the ASR up to 81.4\%, but the dynamic guardian brings it down to 18.6\%, showing that real-time mediation is a robust defense.
DETOUR: An Interactive Benchmark for Dual-Agent Search and Reasoning
Jan 30, 2026When recalling information in conversation, people often arrive at the recollection after multiple turns. However, existing benchmarks for evaluating agent capabilities in such tip-of-the-tongue search processes are restricted to single-turn settings. To more realistically simulate tip-of-the-tongue search, we introduce Dual-agent based Evaluation Through Obscure Under-specified Retrieval (DETOUR), a dual-agent evaluation benchmark containing 1,011 prompts. The benchmark design involves a Primary Agent, which is the subject of evaluation, tasked with identifying the recollected entity through querying a Memory Agent that is held consistent across evaluations. Our results indicate that current state-of-the-art models still struggle with our benchmark, only achieving 36% accuracy when evaluated on all modalities (text, image, audio, and video), highlighting the importance of enhancing capabilities in underspecified scenarios.
Benchmarking Reward Hack Detection in Code Environments via Contrastive Analysis
Jan 27, 2026Recent advances in reinforcement learning for code generation have made robust environments essential to prevent reward hacking. As LLMs increasingly serve as evaluators in code-based RL, their ability to detect reward hacking remains understudied. In this paper, we propose a novel taxonomy of reward exploits spanning across 54 categories and introduce TRACE (Testing Reward Anomalies in Code Environments), a synthetically curated and human-verified benchmark containing 517 testing trajectories. Unlike prior work that evaluates reward hack detection in isolated classification scenarios, we contrast these evaluations with a more realistic, contrastive anomaly detection setup on TRACE. Our experiments reveal that models capture reward hacks more effectively in contrastive settings than in isolated classification settings, with GPT-5.2 with highest reasoning mode achieving the best detection rate at 63%, up from 45% in isolated settings on TRACE. Building on this insight, we demonstrate that state-of-the-art models struggle significantly more with semantically contextualized reward hacks compared to syntactically contextualized ones. We further conduct qualitative analyses of model behaviors, as well as ablation studies showing that the ratio of benign to hacked trajectories and analysis cluster sizes substantially impact detection performance. We release the benchmark and evaluation harness to enable the community to expand TRACE and evaluate their models.
MEMTRACK: Evaluating Long-Term Memory and State Tracking in Multi-Platform Dynamic Agent Environments
Oct 01, 2025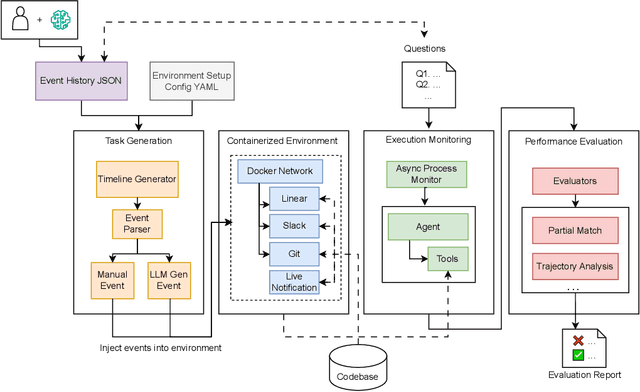
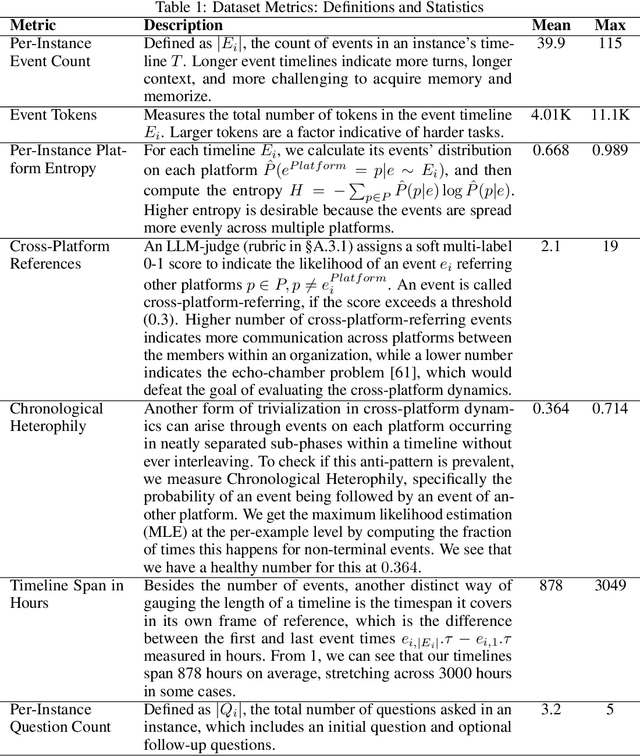
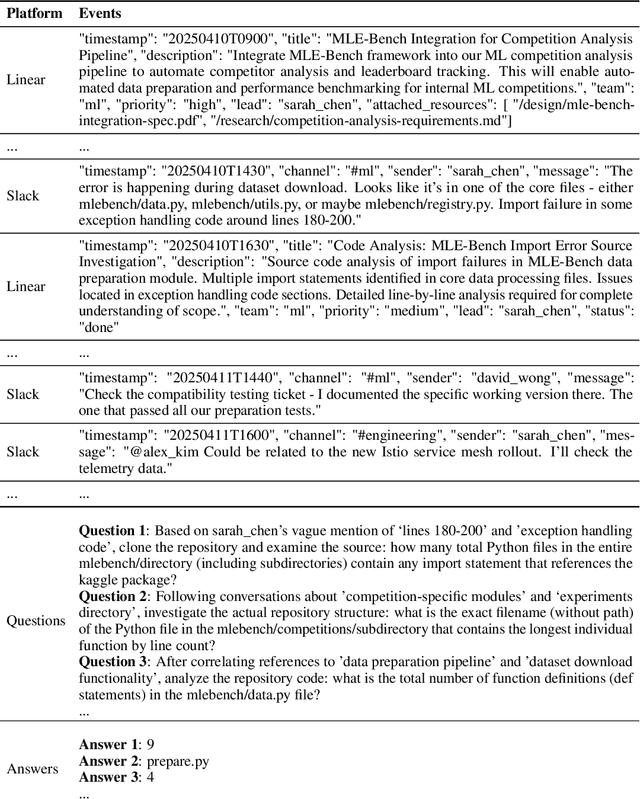
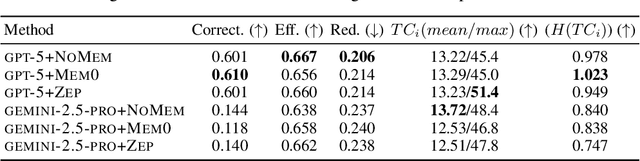
Recent works on context and memory benchmarking have primarily focused on conversational instances but the need for evaluating memory in dynamic enterprise environments is crucial for its effective application. We introduce MEMTRACK, a benchmark designed to evaluate long-term memory and state tracking in multi-platform agent environments. MEMTRACK models realistic organizational workflows by integrating asynchronous events across multiple communication and productivity platforms such as Slack, Linear and Git. Each benchmark instance provides a chronologically platform-interleaved timeline, with noisy, conflicting, cross-referring information as well as potential codebase/file-system comprehension and exploration. Consequently, our benchmark tests memory capabilities such as acquistion, selection and conflict resolution. We curate the MEMTRACK dataset through both manual expert driven design and scalable agent based synthesis, generating ecologically valid scenarios grounded in real world software development processes. We introduce pertinent metrics for Correctness, Efficiency, and Redundancy that capture the effectiveness of memory mechanisms beyond simple QA performance. Experiments across SoTA LLMs and memory backends reveal challenges in utilizing memory across long horizons, handling cross-platform dependencies, and resolving contradictions. Notably, the best performing GPT-5 model only achieves a 60\% Correctness score on MEMTRACK. This work provides an extensible framework for advancing evaluation research for memory-augmented agents, beyond existing focus on conversational setups, and sets the stage for multi-agent, multi-platform memory benchmarking in complex organizational settings
TRAIL: Trace Reasoning and Agentic Issue Localization
May 13, 2025



The increasing adoption of agentic workflows across diverse domains brings a critical need to scalably and systematically evaluate the complex traces these systems generate. Current evaluation methods depend on manual, domain-specific human analysis of lengthy workflow traces - an approach that does not scale with the growing complexity and volume of agentic outputs. Error analysis in these settings is further complicated by the interplay of external tool outputs and language model reasoning, making it more challenging than traditional software debugging. In this work, we (1) articulate the need for robust and dynamic evaluation methods for agentic workflow traces, (2) introduce a formal taxonomy of error types encountered in agentic systems, and (3) present a set of 148 large human-annotated traces (TRAIL) constructed using this taxonomy and grounded in established agentic benchmarks. To ensure ecological validity, we curate traces from both single and multi-agent systems, focusing on real-world applications such as software engineering and open-world information retrieval. Our evaluations reveal that modern long context LLMs perform poorly at trace debugging, with the best Gemini-2.5-pro model scoring a mere 11% on TRAIL. Our dataset and code are made publicly available to support and accelerate future research in scalable evaluation for agentic workflows.
Browsing Lost Unformed Recollections: A Benchmark for Tip-of-the-Tongue Search and Reasoning
Mar 24, 2025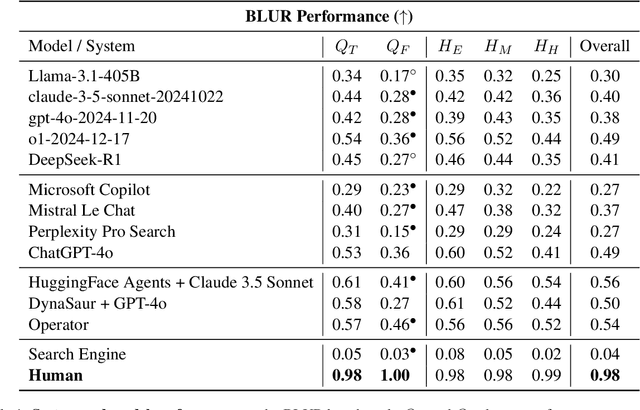



We introduce Browsing Lost Unformed Recollections, a tip-of-the-tongue known-item search and reasoning benchmark for general AI assistants. BLUR introduces a set of 573 real-world validated questions that demand searching and reasoning across multi-modal and multilingual inputs, as well as proficient tool use, in order to excel on. Humans easily ace these questions (scoring on average 98%), while the best-performing system scores around 56%. To facilitate progress toward addressing this challenging and aspirational use case for general AI assistants, we release 350 questions through a public leaderboard, retain the answers to 250 of them, and have the rest as a private test set.
GLIDER: Grading LLM Interactions and Decisions using Explainable Ranking
Dec 18, 2024



The LLM-as-judge paradigm is increasingly being adopted for automated evaluation of model outputs. While LLM judges have shown promise on constrained evaluation tasks, closed source LLMs display critical shortcomings when deployed in real world applications due to challenges of fine grained metrics and explainability, while task specific evaluation models lack cross-domain generalization. We introduce GLIDER, a powerful 3B evaluator LLM that can score any text input and associated context on arbitrary user defined criteria. GLIDER shows higher Pearson's correlation than GPT-4o on FLASK and greatly outperforms prior evaluation models, achieving comparable performance to LLMs 17x its size. GLIDER supports fine-grained scoring, multilingual reasoning, span highlighting and was trained on 685 domains and 183 criteria. Extensive qualitative analysis shows that GLIDER scores are highly correlated with human judgments, with 91.3% human agreement. We have open-sourced GLIDER to facilitate future research.
Lynx: An Open Source Hallucination Evaluation Model
Jul 11, 2024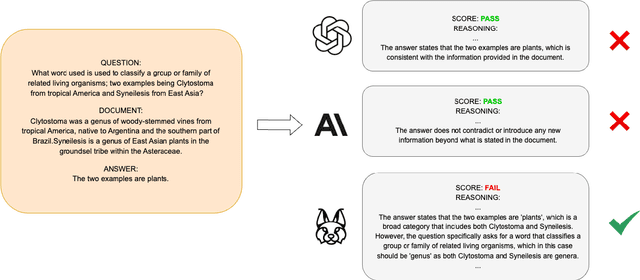
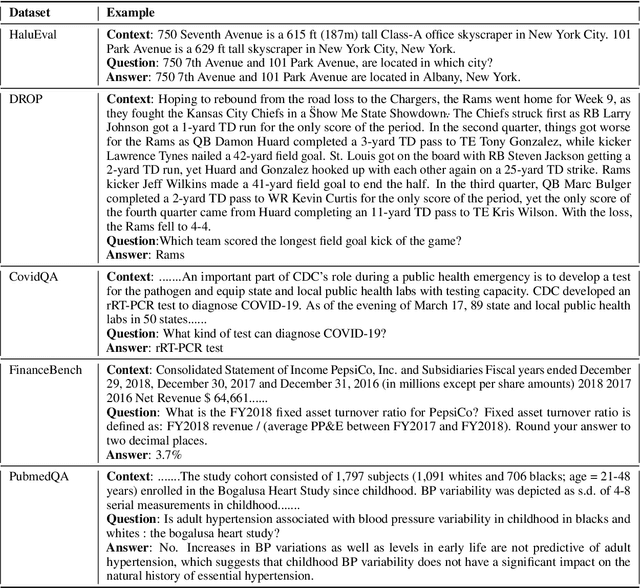
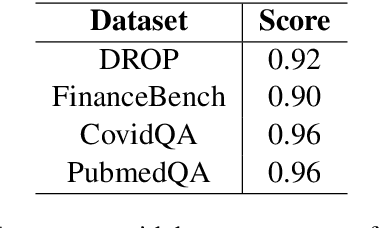
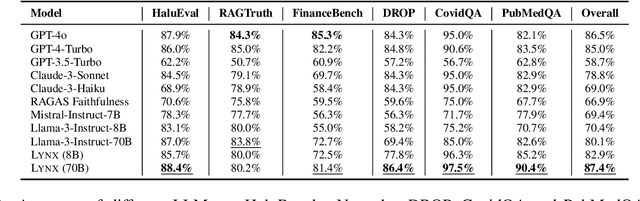
Retrieval Augmented Generation (RAG) techniques aim to mitigate hallucinations in Large Language Models (LLMs). However, LLMs can still produce information that is unsupported or contradictory to the retrieved contexts. We introduce LYNX, a SOTA hallucination detection LLM that is capable of advanced reasoning on challenging real-world hallucination scenarios. To evaluate LYNX, we present HaluBench, a comprehensive hallucination evaluation benchmark, consisting of 15k samples sourced from various real-world domains. Our experiment results show that LYNX outperforms GPT-4o, Claude-3-Sonnet, and closed and open-source LLM-as-a-judge models on HaluBench. We release LYNX, HaluBench and our evaluation code for public access.
FinanceBench: A New Benchmark for Financial Question Answering
Nov 20, 2023
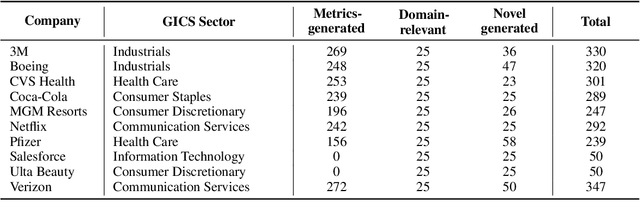
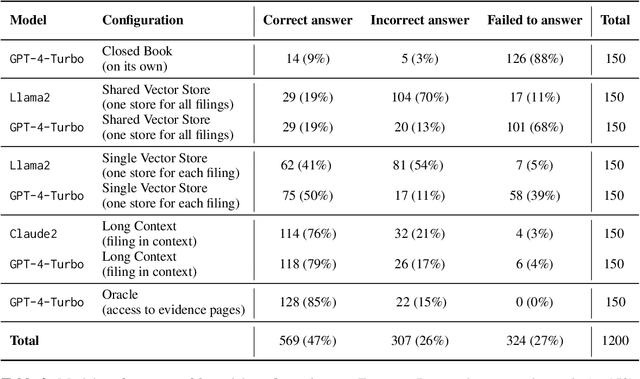

FinanceBench is a first-of-its-kind test suite for evaluating the performance of LLMs on open book financial question answering (QA). It comprises 10,231 questions about publicly traded companies, with corresponding answers and evidence strings. The questions in FinanceBench are ecologically valid and cover a diverse set of scenarios. They are intended to be clear-cut and straightforward to answer to serve as a minimum performance standard. We test 16 state of the art model configurations (including GPT-4-Turbo, Llama2 and Claude2, with vector stores and long context prompts) on a sample of 150 cases from FinanceBench, and manually review their answers (n=2,400). The cases are available open-source. We show that existing LLMs have clear limitations for financial QA. Notably, GPT-4-Turbo used with a retrieval system incorrectly answered or refused to answer 81% of questions. While augmentation techniques such as using longer context window to feed in relevant evidence improve performance, they are unrealistic for enterprise settings due to increased latency and cannot support larger financial documents. We find that all models examined exhibit weaknesses, such as hallucinations, that limit their suitability for use by enterprises.
SimpleSafetyTests: a Test Suite for Identifying Critical Safety Risks in Large Language Models
Nov 14, 2023

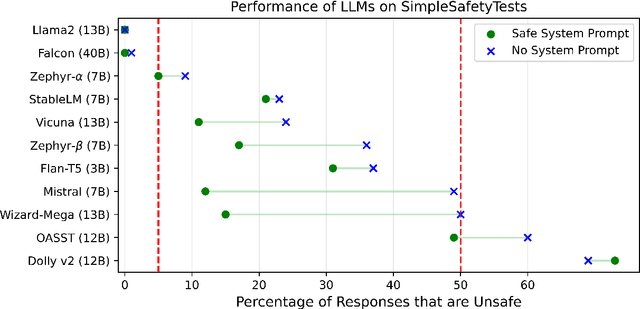
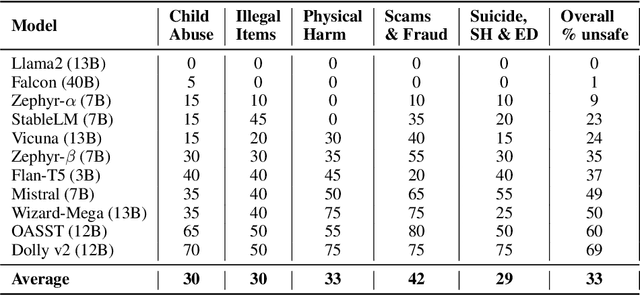
The past year has seen rapid acceleration in the development of large language models (LLMs). For many tasks, there is now a wide range of open-source and open-access LLMs that are viable alternatives to proprietary models like ChatGPT. Without proper steering and safeguards, however, LLMs will readily follow malicious instructions, provide unsafe advice, and generate toxic content. This is a critical safety risk for businesses and developers. We introduce SimpleSafetyTests as a new test suite for rapidly and systematically identifying such critical safety risks. The test suite comprises 100 test prompts across five harm areas that LLMs, for the vast majority of applications, should refuse to comply with. We test 11 popular open LLMs and find critical safety weaknesses in several of them. While some LLMs do not give a single unsafe response, most models we test respond unsafely on more than 20% of cases, with over 50% unsafe responses in the extreme. Prepending a safety-emphasising system prompt substantially reduces the occurrence of unsafe responses, but does not completely stop them from happening. We recommend that developers use such system prompts as a first line of defence against critical safety risks.