 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDebiasing Large Language Models toward Social Factors in Online Behavior Analytics through Prompt Knowledge Tuning
Mar 28, 2026Attribution theory explains how individuals interpret and attribute others' behavior in a social context by employing personal (dispositional) and impersonal (situational) causality. Large Language Models (LLMs), trained on human-generated corpora, may implicitly mimic this social attribution process in social contexts. However, the extent to which LLMs utilize these causal attributions in their reasoning remains underexplored. Although using reasoning paradigms, such as Chain-of-Thought (CoT), has shown promising results in various tasks, ignoring social attribution in reasoning could lead to biased responses by LLMs in social contexts. In this study, we investigate the impact of incorporating a user's goal as knowledge to infer dispositional causality and message context to infer situational causality on LLM performance. To this end, we introduce a scalable method to mitigate such biases by enriching the instruction prompts for LLMs with two prompt aids using social-attribution knowledge, based on the context and goal of a social media message. This method improves the model performance while reducing the social-attribution bias of the LLM in the reasoning on zero-shot classification tasks for behavior analytics applications. We empirically show the benefits of our method across two tasks-intent detection and theme detection on social media in the disaster domain-when considering the variability of disaster types and multiple languages of social media. Our experiments highlight the biases of three open-source LLMs: Llama3, Mistral, and Gemma, toward social attribution, and show the effectiveness of our mitigation strategies.
TRAIL: Trace Reasoning and Agentic Issue Localization
May 13, 2025



The increasing adoption of agentic workflows across diverse domains brings a critical need to scalably and systematically evaluate the complex traces these systems generate. Current evaluation methods depend on manual, domain-specific human analysis of lengthy workflow traces - an approach that does not scale with the growing complexity and volume of agentic outputs. Error analysis in these settings is further complicated by the interplay of external tool outputs and language model reasoning, making it more challenging than traditional software debugging. In this work, we (1) articulate the need for robust and dynamic evaluation methods for agentic workflow traces, (2) introduce a formal taxonomy of error types encountered in agentic systems, and (3) present a set of 148 large human-annotated traces (TRAIL) constructed using this taxonomy and grounded in established agentic benchmarks. To ensure ecological validity, we curate traces from both single and multi-agent systems, focusing on real-world applications such as software engineering and open-world information retrieval. Our evaluations reveal that modern long context LLMs perform poorly at trace debugging, with the best Gemini-2.5-pro model scoring a mere 11% on TRAIL. Our dataset and code are made publicly available to support and accelerate future research in scalable evaluation for agentic workflows.
Representation Deficiency in Masked Language Modeling
Feb 04, 2023



Masked Language Modeling (MLM) has been one of the most prominent approaches for pretraining bidirectional text encoders due to its simplicity and effectiveness. One notable concern about MLM is that the special $\texttt{[MASK]}$ symbol causes a discrepancy between pretraining data and downstream data as it is present only in pretraining but not in fine-tuning. In this work, we offer a new perspective on the consequence of such a discrepancy: We demonstrate empirically and theoretically that MLM pretraining allocates some model dimensions exclusively for representing $\texttt{[MASK]}$ tokens, resulting in a representation deficiency for real tokens and limiting the pretrained model's expressiveness when it is adapted to downstream data without $\texttt{[MASK]}$ tokens. Motivated by the identified issue, we propose MAE-LM, which pretrains the Masked Autoencoder architecture with MLM where $\texttt{[MASK]}$ tokens are excluded from the encoder. Empirically, we show that MAE-LM improves the utilization of model dimensions for real token representations, and MAE-LM consistently outperforms MLM-pretrained models across different pretraining settings and model sizes when fine-tuned on the GLUE and SQuAD benchmarks.
Cross-Lingual Text Classification of Transliterated Hindi and Malayalam
Aug 31, 2021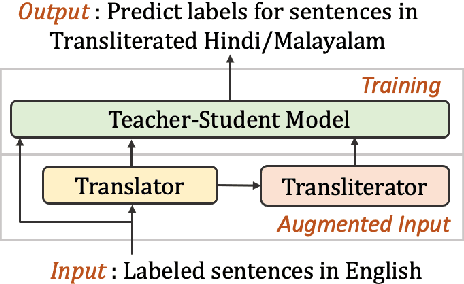
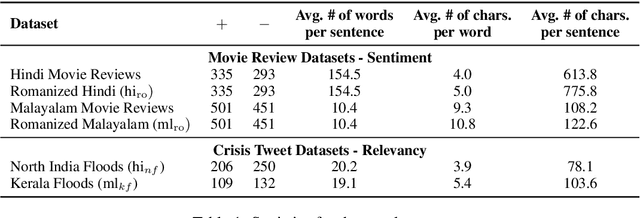

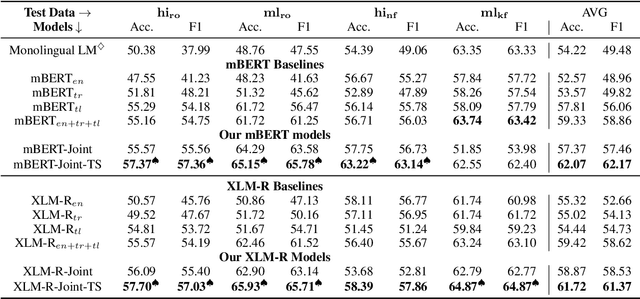
Transliteration is very common on social media, but transliterated text is not adequately handled by modern neural models for various NLP tasks. In this work, we combine data augmentation approaches with a Teacher-Student training scheme to address this issue in a cross-lingual transfer setting for fine-tuning state-of-the-art pre-trained multilingual language models such as mBERT and XLM-R. We evaluate our method on transliterated Hindi and Malayalam, also introducing new datasets for benchmarking on real-world scenarios: one on sentiment classification in transliterated Malayalam, and another on crisis tweet classification in transliterated Hindi and Malayalam (related to the 2013 North India and 2018 Kerala floods). Our method yielded an average improvement of +5.6% on mBERT and +4.7% on XLM-R in F1 scores over their strong baselines.
Multilingual Code-Switching for Zero-Shot Cross-Lingual Intent Prediction and Slot Filling
Mar 16, 2021

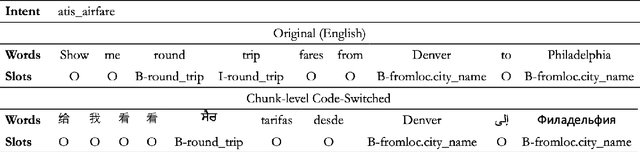
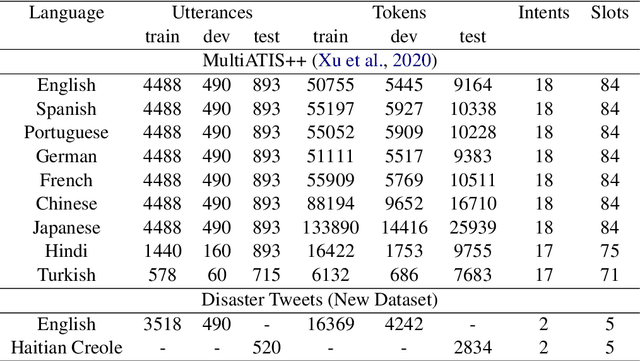
Predicting user intent and detecting the corresponding slots from text are two key problems in Natural Language Understanding (NLU). In the context of zero-shot learning, this task is typically approached by either using representations from pre-trained multilingual transformers such as mBERT, or by machine translating the source data into the known target language and then fine-tuning. Our work focuses on a particular scenario where the target language is unknown during training. To this goal, we propose a novel method to augment the monolingual source data using multilingual code-switching via random translations to enhance a transformer's language neutrality when fine-tuning it for a downstream task. This method also helps discover novel insights on how code-switching with different language families around the world impact the performance on the target language. Experiments on the benchmark dataset of MultiATIS++ yielded an average improvement of +4.2% in accuracy for intent task and +1.8% in F1 for slot task using our method over the state-of-the-art across 8 different languages. Furthermore, we present an application of our method for crisis informatics using a new human-annotated tweet dataset of slot filling in English and Haitian Creole, collected during Haiti earthquake disaster.
Common-Knowledge Concept Recognition for SEVA
Mar 26, 2020

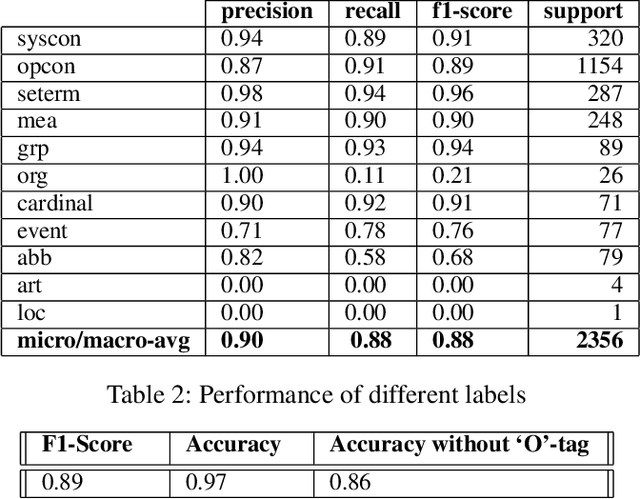

We build a common-knowledge concept recognition system for a Systems Engineer's Virtual Assistant (SEVA) which can be used for downstream tasks such as relation extraction, knowledge graph construction, and question-answering. The problem is formulated as a token classification task similar to named entity extraction. With the help of a domain expert and text processing methods, we construct a dataset annotated at the word-level by carefully defining a labelling scheme to train a sequence model to recognize systems engineering concepts. We use a pre-trained language model and fine-tune it with the labeled dataset of concepts. In addition, we also create some essential datasets for information such as abbreviations and definitions from the systems engineering domain. Finally, we construct a simple knowledge graph using these extracted concepts along with some hyponym relations.
Unsupervised and Interpretable Domain Adaptation to Rapidly Filter Social Web Data for Emergency Services
Mar 04, 2020
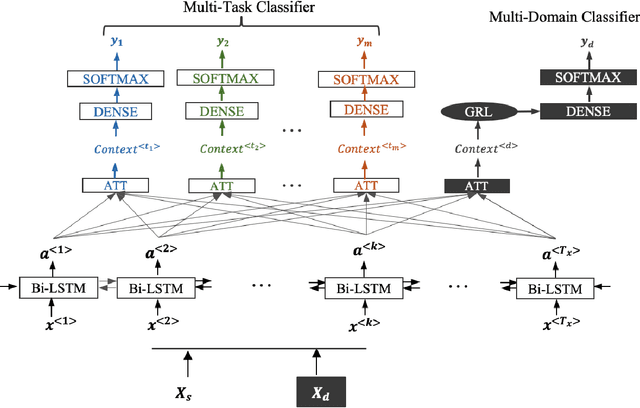

During the onset of a disaster event, filtering relevant information from the social web data is challenging due to its sparse availability and practical limitations in labeling datasets of an ongoing crisis. In this paper, we show that unsupervised domain adaptation through multi-task learning can be a useful framework to leverage data from past crisis events, as well as exploit additional web resources for training efficient information filtering models during an ongoing crisis. We present a novel method to classify relevant tweets during an ongoing crisis without seeing any new examples, using the publicly available dataset of TREC incident streams that provides labeled tweets with 4 relevant classes across 10 different crisis events. Additionally, our method addresses a crucial but missing component from current research in web science for crisis data filtering models: interpretability. Specifically, we first identify a standard single-task attention-based neural network architecture and then construct a customized multi-task architecture for the crisis domain: Multi-Task Domain Adversarial Attention Network. This model consists of dedicated attention layers for each task and a domain classifier for gradient reversal. Evaluation of domain adaptation for crisis events is performed by choosing a target event as the test set and training on the rest. Our results show that the multi-task model outperformed its single-task counterpart and also, training with additional web-resources showed further performance boost. Furthermore, we show that the attention layer can be used as a guide to explain the model predictions by showcasing the words in a tweet that are deemed important in the classification process. Our research aims to pave the way towards a fully unsupervised and interpretable domain adaptation of low-resource crisis web data to aid emergency responders quickly and effectively.
Diversity-Based Generalization for Neural Unsupervised Text Classification under Domain Shift
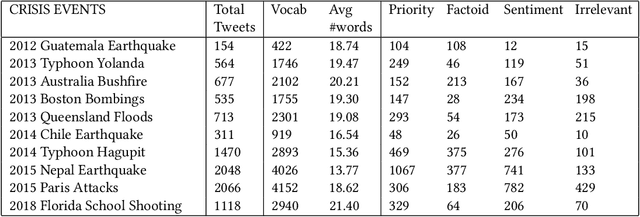
Feb 25, 2020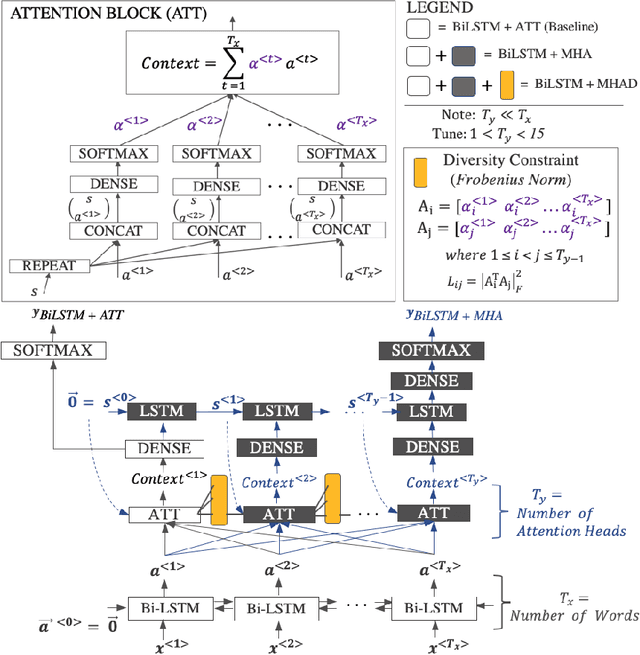
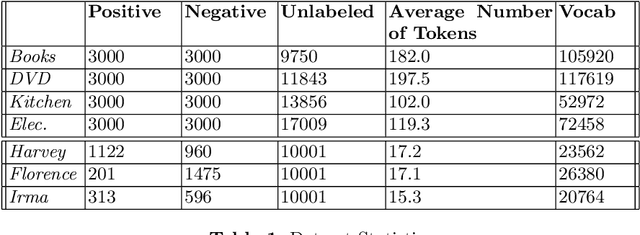
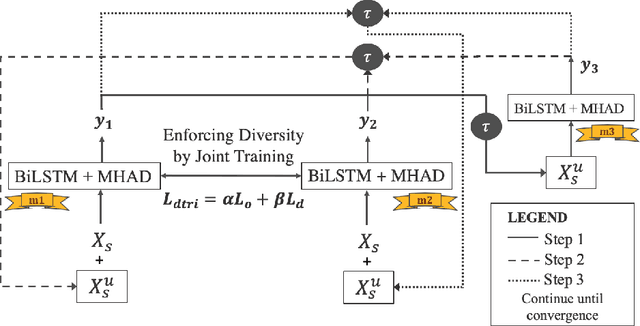

Domain adaptation approaches seek to learn from a source domain and generalize it to an unseen target domain. At present, the state-of-the-art domain adaptation approaches for subjective text classification problems are semi-supervised; and use unlabeled target data along with labeled source data. In this paper, we propose a novel method for domain adaptation of single-task text classification problems based on a simple but effective idea of diversity-based generalization that does not require unlabeled target data. Diversity plays the role of promoting the model to better generalize and be indiscriminate towards domain shift by forcing the model not to rely on same features for prediction. We apply this concept on the most explainable component of neural networks, the attention layer. To generate sufficient diversity, we create a multi-head attention model and infuse a diversity constraint between the attention heads such that each head will learn differently. We further expand upon our model by tri-training and designing a procedure with an additional diversity constraint between the attention heads of the tri-trained classifiers. Extensive evaluation using the standard benchmark dataset of Amazon reviews and a newly constructed dataset of Crisis events shows that our fully unsupervised method matches with the competing semi-supervised baselines. Our results demonstrate that machine learning architectures that ensure sufficient diversity can generalize better; encouraging future research to design ubiquitously usable learning models without using unlabeled target data.