 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDebiasing Large Language Models toward Social Factors in Online Behavior Analytics through Prompt Knowledge Tuning
Mar 28, 2026Attribution theory explains how individuals interpret and attribute others' behavior in a social context by employing personal (dispositional) and impersonal (situational) causality. Large Language Models (LLMs), trained on human-generated corpora, may implicitly mimic this social attribution process in social contexts. However, the extent to which LLMs utilize these causal attributions in their reasoning remains underexplored. Although using reasoning paradigms, such as Chain-of-Thought (CoT), has shown promising results in various tasks, ignoring social attribution in reasoning could lead to biased responses by LLMs in social contexts. In this study, we investigate the impact of incorporating a user's goal as knowledge to infer dispositional causality and message context to infer situational causality on LLM performance. To this end, we introduce a scalable method to mitigate such biases by enriching the instruction prompts for LLMs with two prompt aids using social-attribution knowledge, based on the context and goal of a social media message. This method improves the model performance while reducing the social-attribution bias of the LLM in the reasoning on zero-shot classification tasks for behavior analytics applications. We empirically show the benefits of our method across two tasks-intent detection and theme detection on social media in the disaster domain-when considering the variability of disaster types and multiple languages of social media. Our experiments highlight the biases of three open-source LLMs: Llama3, Mistral, and Gemma, toward social attribution, and show the effectiveness of our mitigation strategies.
Knowledge-guided Continual Learning for Behavioral Analytics Systems
Oct 25, 2025User behavior on online platforms is evolving, reflecting real-world changes in how people post, whether it's helpful messages or hate speech. Models that learn to capture this content can experience a decrease in performance over time due to data drift, which can lead to ineffective behavioral analytics systems. However, fine-tuning such a model over time with new data can be detrimental due to catastrophic forgetting. Replay-based approaches in continual learning offer a simple yet efficient method to update such models, minimizing forgetting by maintaining a buffer of important training instances from past learned tasks. However, the main limitation of this approach is the fixed size of the buffer. External knowledge bases can be utilized to overcome this limitation through data augmentation. We propose a novel augmentation-based approach to incorporate external knowledge in the replay-based continual learning framework. We evaluate several strategies with three datasets from prior studies related to deviant behavior classification to assess the integration of external knowledge in continual learning and demonstrate that augmentation helps outperform baseline replay-based approaches.
Exposing LLM Vulnerabilities: Adversarial Scam Detection and Performance
Dec 01, 2024



Can we trust Large Language Models (LLMs) to accurately predict scam? This paper investigates the vulnerabilities of LLMs when facing adversarial scam messages for the task of scam detection. We addressed this issue by creating a comprehensive dataset with fine-grained labels of scam messages, including both original and adversarial scam messages. The dataset extended traditional binary classes for the scam detection task into more nuanced scam types. Our analysis showed how adversarial examples took advantage of vulnerabilities of a LLM, leading to high misclassification rate. We evaluated the performance of LLMs on these adversarial scam messages and proposed strategies to improve their robustness.
ORIS: Online Active Learning Using Reinforcement Learning-based Inclusive Sampling for Robust Streaming Analytics System
Nov 27, 2024



Effective labeled data collection plays a critical role in developing and fine-tuning robust streaming analytics systems. However, continuously labeling documents to filter relevant information poses significant challenges like limited labeling budget or lack of high-quality labels. There is a need for efficient human-in-the-loop machine learning (HITL-ML) design to improve streaming analytics systems. One particular HITL- ML approach is online active learning, which involves iteratively selecting a small set of the most informative documents for labeling to enhance the ML model performance. The performance of such algorithms can get affected due to human errors in labeling. To address these challenges, we propose ORIS, a method to perform Online active learning using Reinforcement learning-based Inclusive Sampling of documents for labeling. ORIS aims to create a novel Deep Q-Network-based strategy to sample incoming documents that minimize human errors in labeling and enhance the ML model performance. We evaluate the ORIS method on emotion recognition tasks, and it outperforms traditional baselines in terms of both human labeling performance and the ML model performance.
Designing Decision Support Systems for Emergency Response: Challenges and Opportunities
Mar 13, 2022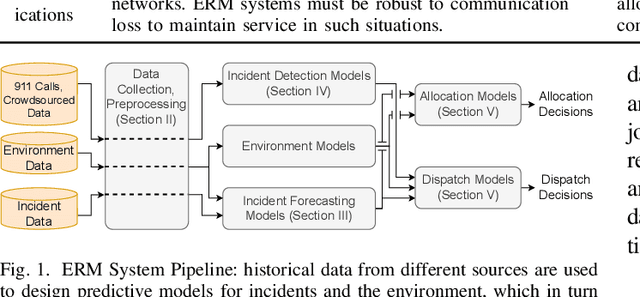
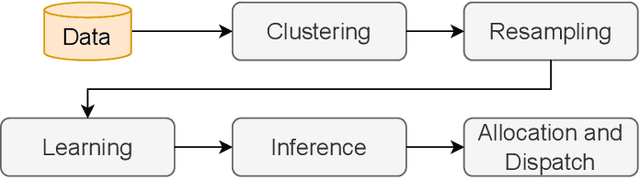
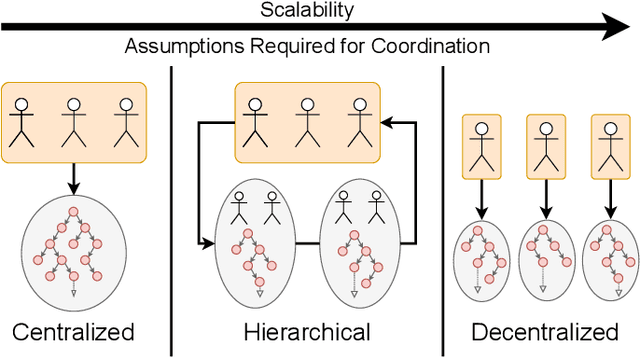
Designing effective emergency response management (ERM) systems to respond to incidents such as road accidents is a major problem faced by communities. In addition to responding to frequent incidents each day (about 240 million emergency medical services calls and over 5 million road accidents in the US each year), these systems also support response during natural hazards. Recently, there has been a consistent interest in building decision support and optimization tools that can help emergency responders provide more efficient and effective response. This includes a number of principled subsystems that implement early incident detection, incident likelihood forecasting and strategic resource allocation and dispatch policies. In this paper, we highlight the key challenges and provide an overview of the approach developed by our team in collaboration with our community partners.
Practitioner-Centric Approach for Early Incident Detection Using Crowdsourced Data for Emergency Services
Dec 03, 2021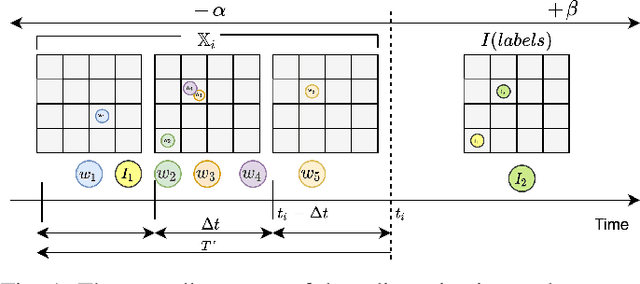
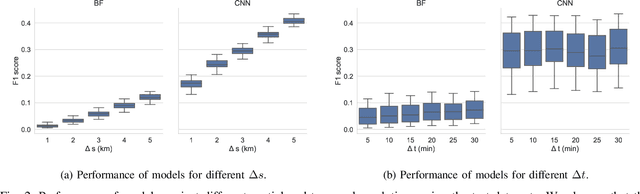
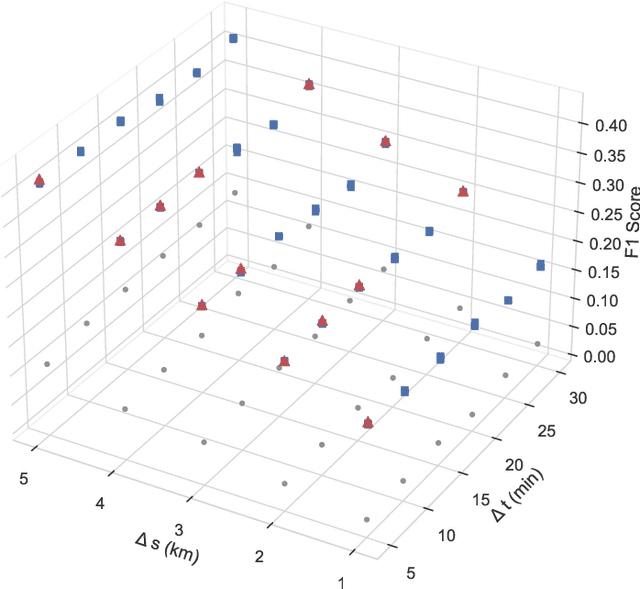
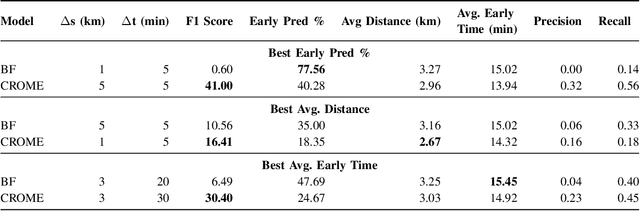
Emergency response is highly dependent on the time of incident reporting. Unfortunately, the traditional approach to receiving incident reports (e.g., calling 911 in the USA) has time delays. Crowdsourcing platforms such as Waze provide an opportunity for early identification of incidents. However, detecting incidents from crowdsourced data streams is difficult due to the challenges of noise and uncertainty associated with such data. Further, simply optimizing over detection accuracy can compromise spatial-temporal localization of the inference, thereby making such approaches infeasible for real-world deployment. This paper presents a novel problem formulation and solution approach for practitioner-centered incident detection using crowdsourced data by using emergency response management as a case-study. The proposed approach CROME (Crowdsourced Multi-objective Event Detection) quantifies the relationship between the performance metrics of incident classification (e.g., F1 score) and the requirements of model practitioners (e.g., 1 km. radius for incident detection). First, we show how crowdsourced reports, ground-truth historical data, and other relevant determinants such as traffic and weather can be used together in a Convolutional Neural Network (CNN) architecture for early detection of emergency incidents. Then, we use a Pareto optimization-based approach to optimize the output of the CNN in tandem with practitioner-centric parameters to balance detection accuracy and spatial-temporal localization. Finally, we demonstrate the applicability of this approach using crowdsourced data from Waze and traffic accident reports from Nashville, TN, USA. Our experiments demonstrate that the proposed approach outperforms existing approaches in incident detection while simultaneously optimizing the needs for real-world deployment and usability.
Cross-Lingual Text Classification of Transliterated Hindi and Malayalam
Aug 31, 2021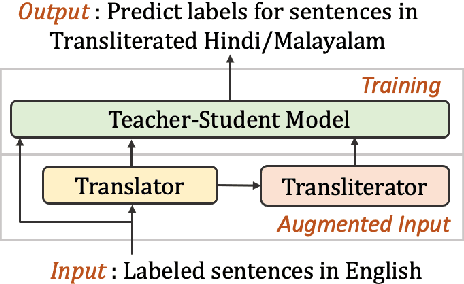

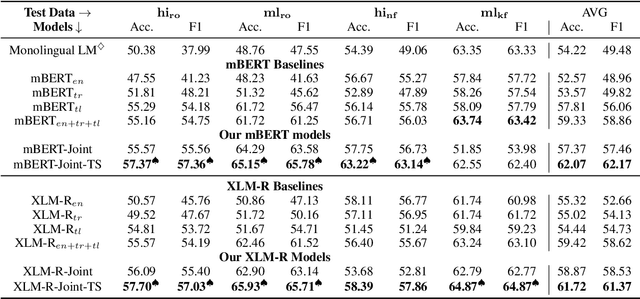
Transliteration is very common on social media, but transliterated text is not adequately handled by modern neural models for various NLP tasks. In this work, we combine data augmentation approaches with a Teacher-Student training scheme to address this issue in a cross-lingual transfer setting for fine-tuning state-of-the-art pre-trained multilingual language models such as mBERT and XLM-R. We evaluate our method on transliterated Hindi and Malayalam, also introducing new datasets for benchmarking on real-world scenarios: one on sentiment classification in transliterated Malayalam, and another on crisis tweet classification in transliterated Hindi and Malayalam (related to the 2013 North India and 2018 Kerala floods). Our method yielded an average improvement of +5.6% on mBERT and +4.7% on XLM-R in F1 scores over their strong baselines.
Multilingual Code-Switching for Zero-Shot Cross-Lingual Intent Prediction and Slot Filling
Mar 16, 2021

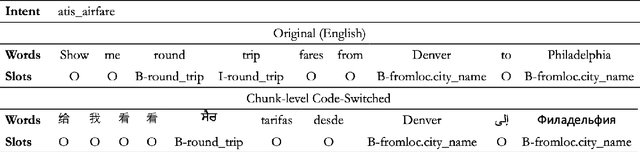
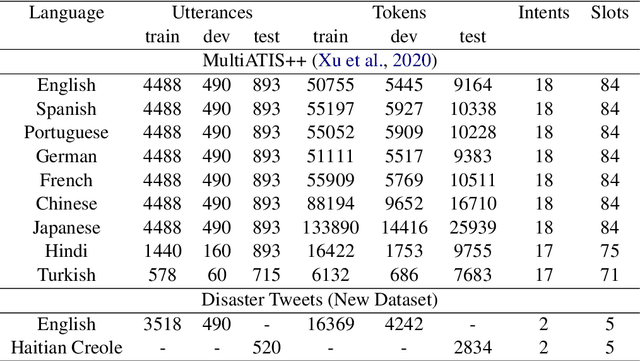
Predicting user intent and detecting the corresponding slots from text are two key problems in Natural Language Understanding (NLU). In the context of zero-shot learning, this task is typically approached by either using representations from pre-trained multilingual transformers such as mBERT, or by machine translating the source data into the known target language and then fine-tuning. Our work focuses on a particular scenario where the target language is unknown during training. To this goal, we propose a novel method to augment the monolingual source data using multilingual code-switching via random translations to enhance a transformer's language neutrality when fine-tuning it for a downstream task. This method also helps discover novel insights on how code-switching with different language families around the world impact the performance on the target language. Experiments on the benchmark dataset of MultiATIS++ yielded an average improvement of +4.2% in accuracy for intent task and +1.8% in F1 for slot task using our method over the state-of-the-art across 8 different languages. Furthermore, we present an application of our method for crisis informatics using a new human-annotated tweet dataset of slot filling in English and Haitian Creole, collected during Haiti earthquake disaster.
Emergency Incident Detection from Crowdsourced Waze Data using Bayesian Information Fusion
Nov 10, 2020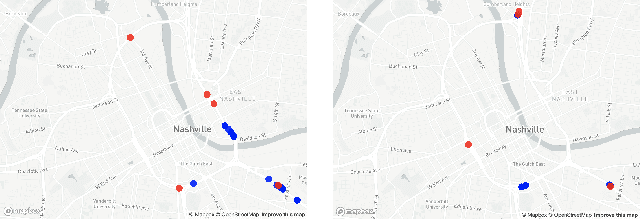
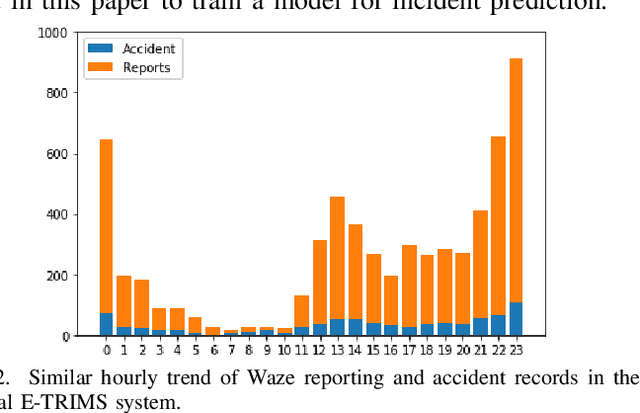
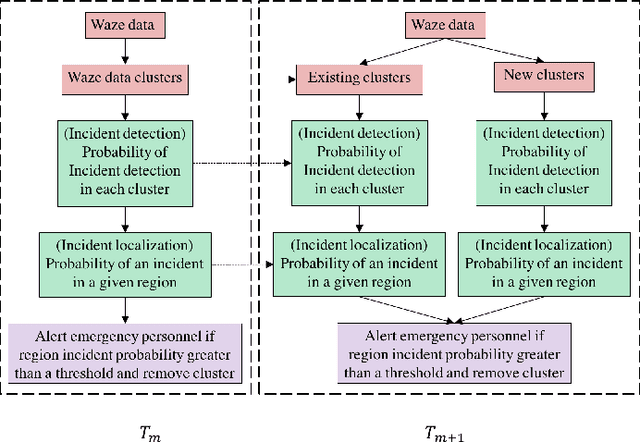
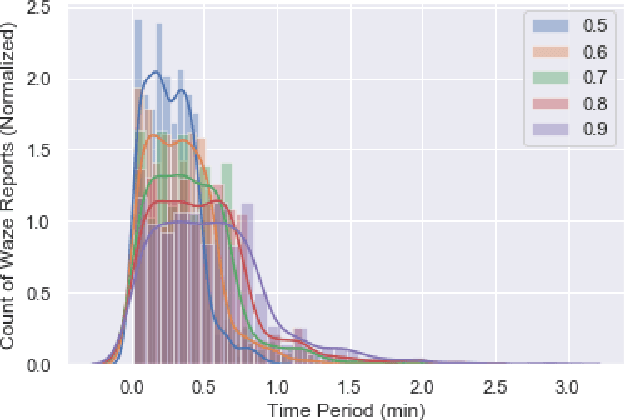
The number of emergencies have increased over the years with the growth in urbanization. This pattern has overwhelmed the emergency services with limited resources and demands the optimization of response processes. It is partly due to traditional `reactive' approach of emergency services to collect data about incidents, where a source initiates a call to the emergency number (e.g., 911 in U.S.), delaying and limiting the potentially optimal response. Crowdsourcing platforms such as Waze provides an opportunity to develop a rapid, `proactive' approach to collect data about incidents through crowd-generated observational reports. However, the reliability of reporting sources and spatio-temporal uncertainty of the reported incidents challenge the design of such a proactive approach. Thus, this paper presents a novel method for emergency incident detection using noisy crowdsourced Waze data. We propose a principled computational framework based on Bayesian theory to model the uncertainty in the reliability of crowd-generated reports and their integration across space and time to detect incidents. Extensive experiments using data collected from Waze and the official reported incidents in Nashville, Tenessee in the U.S. show our method can outperform strong baselines for both F1-score and AUC. The application of this work provides an extensible framework to incorporate different noisy data sources for proactive incident detection to improve and optimize emergency response operations in our communities.
Common-Knowledge Concept Recognition for SEVA
Mar 26, 2020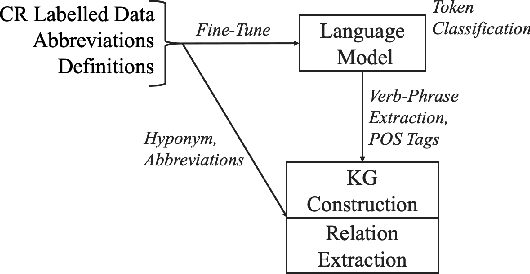

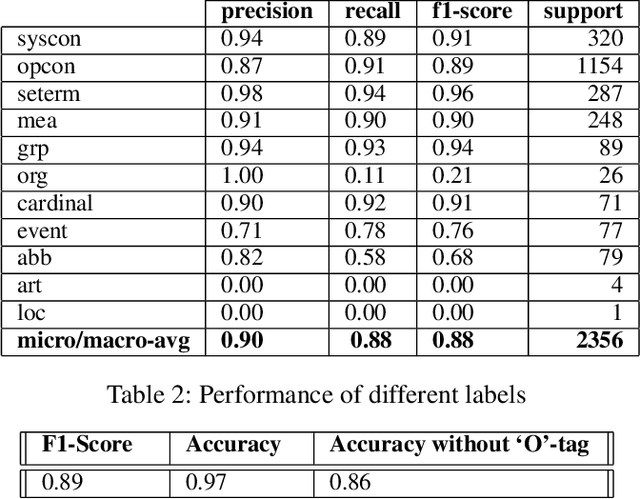

We build a common-knowledge concept recognition system for a Systems Engineer's Virtual Assistant (SEVA) which can be used for downstream tasks such as relation extraction, knowledge graph construction, and question-answering. The problem is formulated as a token classification task similar to named entity extraction. With the help of a domain expert and text processing methods, we construct a dataset annotated at the word-level by carefully defining a labelling scheme to train a sequence model to recognize systems engineering concepts. We use a pre-trained language model and fine-tune it with the labeled dataset of concepts. In addition, we also create some essential datasets for information such as abbreviations and definitions from the systems engineering domain. Finally, we construct a simple knowledge graph using these extracted concepts along with some hyponym relations.