 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiversity-Based Generalization for Neural Unsupervised Text Classification under Domain Shift
Paper and Code
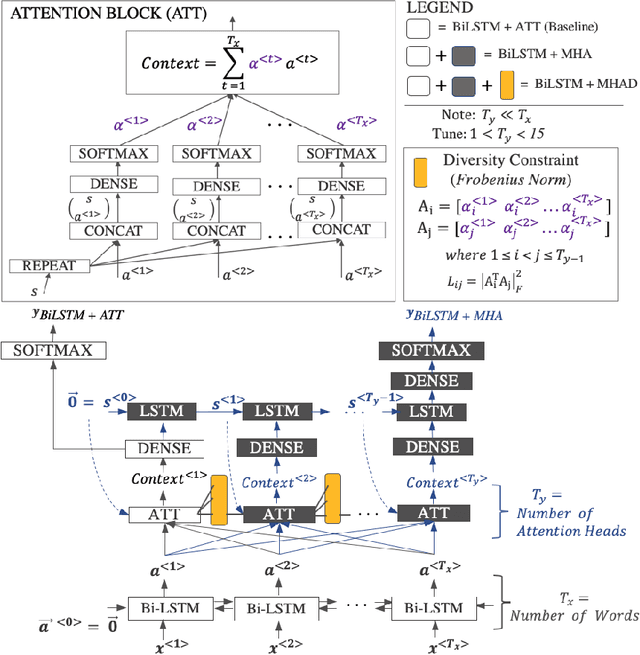
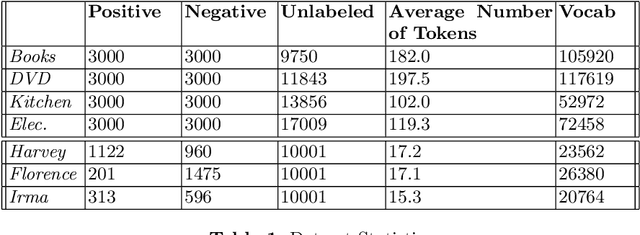
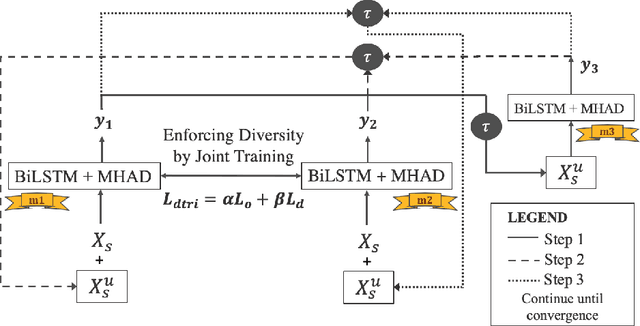

Domain adaptation approaches seek to learn from a source domain and generalize it to an unseen target domain. At present, the state-of-the-art domain adaptation approaches for subjective text classification problems are semi-supervised; and use unlabeled target data along with labeled source data. In this paper, we propose a novel method for domain adaptation of single-task text classification problems based on a simple but effective idea of diversity-based generalization that does not require unlabeled target data. Diversity plays the role of promoting the model to better generalize and be indiscriminate towards domain shift by forcing the model not to rely on same features for prediction. We apply this concept on the most explainable component of neural networks, the attention layer. To generate sufficient diversity, we create a multi-head attention model and infuse a diversity constraint between the attention heads such that each head will learn differently. We further expand upon our model by tri-training and designing a procedure with an additional diversity constraint between the attention heads of the tri-trained classifiers. Extensive evaluation using the standard benchmark dataset of Amazon reviews and a newly constructed dataset of Crisis events shows that our fully unsupervised method matches with the competing semi-supervised baselines. Our results demonstrate that machine learning architectures that ensure sufficient diversity can generalize better; encouraging future research to design ubiquitously usable learning models without using unlabeled target data.