 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeORIS: Online Active Learning Using Reinforcement Learning-based Inclusive Sampling for Robust Streaming Analytics System
Nov 27, 2024



Effective labeled data collection plays a critical role in developing and fine-tuning robust streaming analytics systems. However, continuously labeling documents to filter relevant information poses significant challenges like limited labeling budget or lack of high-quality labels. There is a need for efficient human-in-the-loop machine learning (HITL-ML) design to improve streaming analytics systems. One particular HITL- ML approach is online active learning, which involves iteratively selecting a small set of the most informative documents for labeling to enhance the ML model performance. The performance of such algorithms can get affected due to human errors in labeling. To address these challenges, we propose ORIS, a method to perform Online active learning using Reinforcement learning-based Inclusive Sampling of documents for labeling. ORIS aims to create a novel Deep Q-Network-based strategy to sample incoming documents that minimize human errors in labeling and enhance the ML model performance. We evaluate the ORIS method on emotion recognition tasks, and it outperforms traditional baselines in terms of both human labeling performance and the ML model performance.
PROCTER: PROnunciation-aware ConTextual adaptER for personalized speech recognition in neural transducers
Mar 30, 2023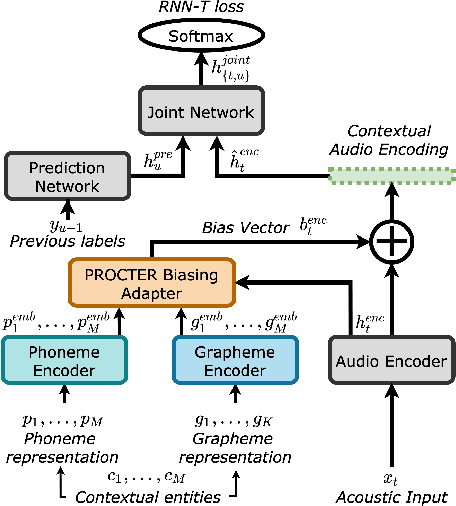
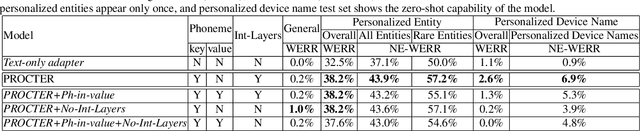

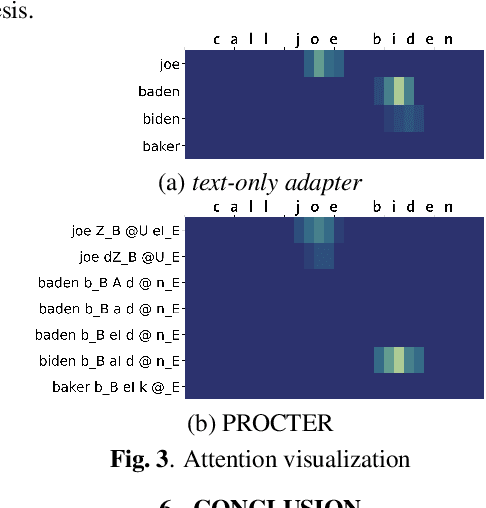
End-to-End (E2E) automatic speech recognition (ASR) systems used in voice assistants often have difficulties recognizing infrequent words personalized to the user, such as names and places. Rare words often have non-trivial pronunciations, and in such cases, human knowledge in the form of a pronunciation lexicon can be useful. We propose a PROnunCiation-aware conTextual adaptER (PROCTER) that dynamically injects lexicon knowledge into an RNN-T model by adding a phonemic embedding along with a textual embedding. The experimental results show that the proposed PROCTER architecture outperforms the baseline RNN-T model by improving the word error rate (WER) by 44% and 57% when measured on personalized entities and personalized rare entities, respectively, while increasing the model size (number of trainable parameters) by only 1%. Furthermore, when evaluated in a zero-shot setting to recognize personalized device names, we observe 7% WER improvement with PROCTER, as compared to only 1% WER improvement with text-only contextual attention
Modeling Human Annotation Errors to Design Bias-Aware Systems for Social Stream Processing
Jul 16, 2019
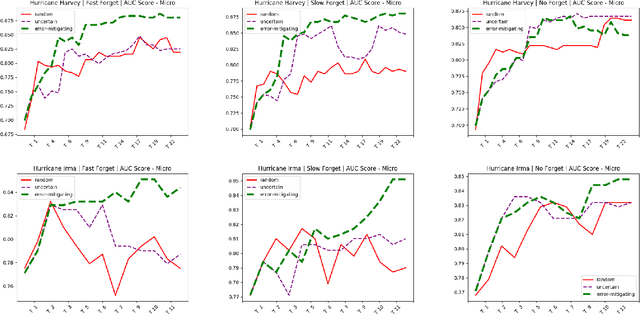
High-quality human annotations are necessary to create effective machine learning systems for social media. Low-quality human annotations indirectly contribute to the creation of inaccurate or biased learning systems. We show that human annotation quality is dependent on the ordering of instances shown to annotators (referred as 'annotation schedule'), and can be improved by local changes in the instance ordering provided to the annotators, yielding a more accurate annotation of the data stream for efficient real-time social media analytics. We propose an error-mitigating active learning algorithm that is robust with respect to some cases of human errors when deciding an annotation schedule. We validate the human error model and evaluate the proposed algorithm against strong baselines by experimenting on classification tasks of relevant social media posts during crises. According to these experiments, considering the order in which data instances are presented to human annotators leads to both an increase in accuracy for machine learning and awareness toward some potential biases in human learning that may affect the automated classifier.