 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Conversational TTS with Cascaded Prompting and ICL-Based Online Reinforcement Learning
Apr 09, 2026Conversational AI has made significant progress, yet generating expressive and controllable text-to-speech (TTS) remains challenging. Specifically, controlling fine-grained voice styles and emotions is notoriously difficult and typically requires massive amounts of heavily annotated training data. To overcome this data bottleneck, we present a scalable, data-efficient cascaded framework that pairs textual style tokens with human-curated, high-quality audio prompts. This approach enables single-shot adaptation to fine-grained speaking styles and character voices. In the context of TTS, this audio prompting acts as In-Context Learning (ICL), guiding the model's prosody and timbre without requiring massive parameter updates or large-scale retraining. To further enhance generation quality and mitigate hallucinations, we introduce a novel ICL-based online reinforcement learning (RL) strategy. This strategy directly optimizes the autoregressive prosody model using subjective aesthetic rewards while being constrained by Connectionist Temporal Classification (CTC) alignment to preserve intelligibility. Comprehensive human perception evaluations demonstrate significant improvements in both the naturalness and expressivity of the synthesized speech, establishing the efficacy of our ICL-based online RL approach.
Aligning Paralinguistic Understanding and Generation in Speech LLMs via Multi-Task Reinforcement Learning
Mar 16, 2026Speech large language models (LLMs) observe paralinguistic cues such as prosody, emotion, and non-verbal sounds--crucial for intent understanding. However, leveraging these cues faces challenges: limited training data, annotation difficulty, and models exploiting lexical shortcuts over paralinguistic signals. We propose multi-task reinforcement learning (RL) with chain-of-thought prompting that elicits explicit affective reasoning. To address data scarcity, we introduce a paralinguistics-aware speech LLM (PALLM) that jointly optimizes sentiment classification from audio and paralinguistics-aware response generation via a two-stage pipeline. Experiments demonstrate that our approach improves paralinguistics understanding over both supervised baselines and strong proprietary models (Gemini-2.5-Pro, GPT-4o-audio) by 8-12% on Expresso, IEMOCAP, and RAVDESS. The results show that modeling paralinguistic reasoning with multi-task RL is crucial for building emotionally intelligent speech LLMs.
Universal Semantic Disentangled Privacy-preserving Speech Representation Learning
May 19, 2025


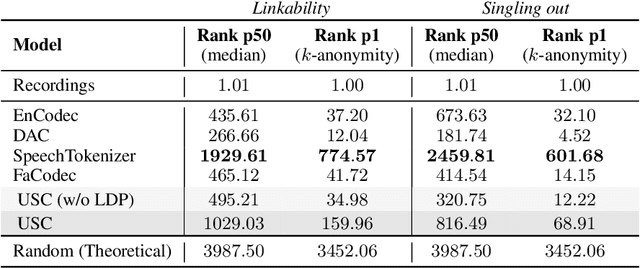
The use of audio recordings of human speech to train LLMs poses privacy concerns due to these models' potential to generate outputs that closely resemble artifacts in the training data. In this study, we propose a speaker privacy-preserving representation learning method through the Universal Speech Codec (USC), a computationally efficient encoder-decoder model that disentangles speech into: $\textit{(i)}$ privacy-preserving semantically rich representations, capturing content and speech paralinguistics, and $\textit{(ii)}$ residual acoustic and speaker representations that enables high-fidelity reconstruction. Extensive evaluations presented show that USC's semantic representation preserves content, prosody, and sentiment, while removing potentially identifiable speaker attributes. Combining both representations, USC achieves state-of-the-art speech reconstruction. Additionally, we introduce an evaluation methodology for measuring privacy-preserving properties, aligning with perceptual tests. We compare USC against other codecs in the literature and demonstrate its effectiveness on privacy-preserving representation learning, illustrating the trade-offs of speaker anonymization, paralinguistics retention and content preservation in the learned semantic representations. Audio samples are shared in $\href{https://www.amazon.science/usc-samples}{https://www.amazon.science/usc-samples}$.
CA-SSLR: Condition-Aware Self-Supervised Learning Representation for Generalized Speech Processing
Dec 05, 2024We introduce Condition-Aware Self-Supervised Learning Representation (CA-SSLR), a generalist conditioning model broadly applicable to various speech-processing tasks. Compared to standard fine-tuning methods that optimize for downstream models, CA-SSLR integrates language and speaker embeddings from earlier layers, making the SSL model aware of the current language and speaker context. This approach reduces the reliance on input audio features while preserving the integrity of the base SSLR. CA-SSLR improves the model's capabilities and demonstrates its generality on unseen tasks with minimal task-specific tuning. Our method employs linear modulation to dynamically adjust internal representations, enabling fine-grained adaptability without significantly altering the original model behavior. Experiments show that CA-SSLR reduces the number of trainable parameters, mitigates overfitting, and excels in under-resourced and unseen tasks. Specifically, CA-SSLR achieves a 10% relative reduction in LID errors, a 37% improvement in ASR CER on the ML-SUPERB benchmark, and a 27% decrease in SV EER on VoxCeleb-1, demonstrating its effectiveness.
Speech Recognition Rescoring with Large Speech-Text Foundation Models
Sep 25, 2024Large language models (LLM) have demonstrated the ability to understand human language by leveraging large amount of text data. Automatic speech recognition (ASR) systems are often limited by available transcribed speech data and benefit from a second pass rescoring using LLM. Recently multi-modal large language models, particularly speech and text foundational models have demonstrated strong spoken language understanding. Speech-Text foundational models leverage large amounts of unlabelled and labelled data both in speech and text modalities to model human language. In this work, we propose novel techniques to use multi-modal LLM for ASR rescoring. We also explore discriminative training to further improve the foundational model rescoring performance. We demonstrate cross-modal knowledge transfer in speech-text LLM can benefit rescoring. Our experiments demonstrate up-to 20% relative improvements over Whisper large ASR and up-to 15% relative improvements over text-only LLM.
An Efficient Self-Learning Framework For Interactive Spoken Dialog Systems
Sep 16, 2024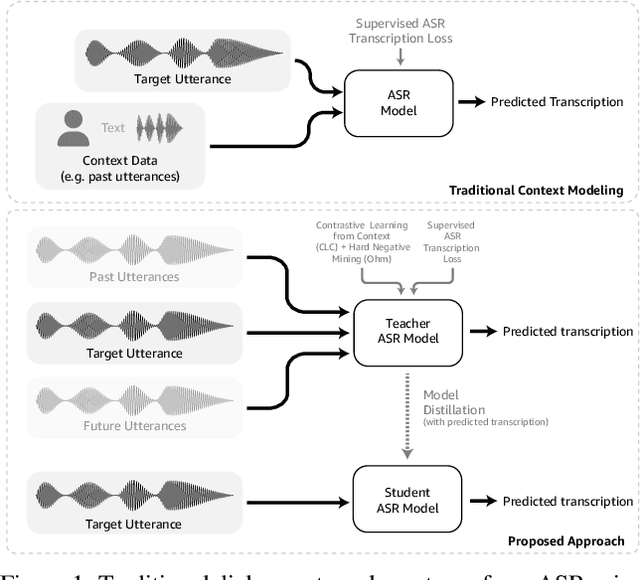

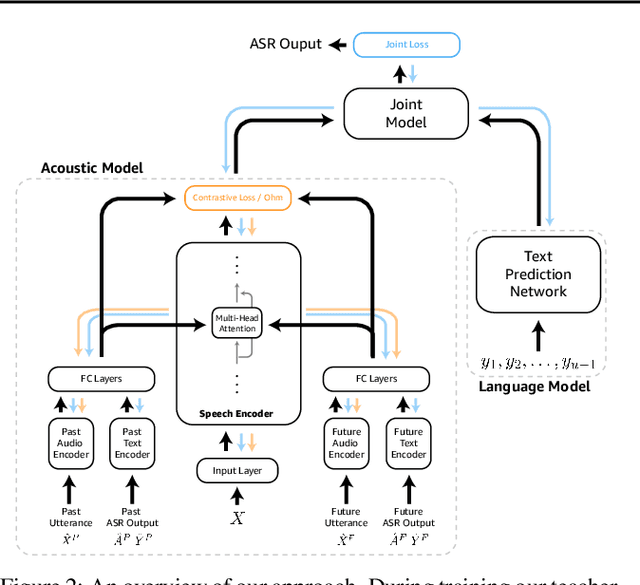
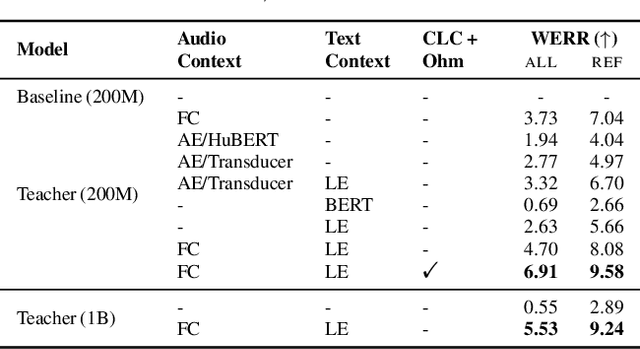
Dialog systems, such as voice assistants, are expected to engage with users in complex, evolving conversations. Unfortunately, traditional automatic speech recognition (ASR) systems deployed in such applications are usually trained to recognize each turn independently and lack the ability to adapt to the conversational context or incorporate user feedback. In this work, we introduce a general framework for ASR in dialog systems that can go beyond learning from single-turn utterances and learn over time how to adapt to both explicit supervision and implicit user feedback present in multi-turn conversations. We accomplish that by leveraging advances in student-teacher learning and context-aware dialog processing, and designing contrastive self-supervision approaches with Ohm, a new online hard-negative mining approach. We show that leveraging our new framework compared to traditional training leads to relative WER reductions of close to 10% in real-world dialog systems, and up to 26% on public synthetic data.
Multi-Modal Retrieval For Large Language Model Based Speech Recognition
Jun 13, 2024



Retrieval is a widely adopted approach for improving language models leveraging external information. As the field moves towards multi-modal large language models, it is important to extend the pure text based methods to incorporate other modalities in retrieval as well for applications across the wide spectrum of machine learning tasks and data types. In this work, we propose multi-modal retrieval with two approaches: kNN-LM and cross-attention techniques. We demonstrate the effectiveness of our retrieval approaches empirically by applying them to automatic speech recognition tasks with access to external information. Under this setting, we show that speech-based multi-modal retrieval outperforms text based retrieval, and yields up to 50 % improvement in word error rate over the multi-modal language model baseline. Furthermore, we achieve state-of-the-art recognition results on the Spoken-Squad question answering dataset.
Two-pass Endpoint Detection for Speech Recognition
Jan 17, 2024Endpoint (EP) detection is a key component of far-field speech recognition systems that assist the user through voice commands. The endpoint detector has to trade-off between accuracy and latency, since waiting longer reduces the cases of users being cut-off early. We propose a novel two-pass solution for endpointing, where the utterance endpoint detected from a first pass endpointer is verified by a 2nd-pass model termed EP Arbitrator. Our method improves the trade-off between early cut-offs and latency over a baseline endpointer, as tested on datasets including voice-assistant transactional queries, conversational speech, and the public SLURP corpus. We demonstrate that our method shows improvements regardless of the first-pass EP model used.
Towards ASR Robust Spoken Language Understanding Through In-Context Learning With Word Confusion Networks
Jan 05, 2024



In the realm of spoken language understanding (SLU), numerous natural language understanding (NLU) methodologies have been adapted by supplying large language models (LLMs) with transcribed speech instead of conventional written text. In real-world scenarios, prior to input into an LLM, an automated speech recognition (ASR) system generates an output transcript hypothesis, where inherent errors can degrade subsequent SLU tasks. Here we introduce a method that utilizes the ASR system's lattice output instead of relying solely on the top hypothesis, aiming to encapsulate speech ambiguities and enhance SLU outcomes. Our in-context learning experiments, covering spoken question answering and intent classification, underline the LLM's resilience to noisy speech transcripts with the help of word confusion networks from lattices, bridging the SLU performance gap between using the top ASR hypothesis and an oracle upper bound. Additionally, we delve into the LLM's robustness to varying ASR performance conditions and scrutinize the aspects of in-context learning which prove the most influential.
Task Oriented Dialogue as a Catalyst for Self-Supervised Automatic Speech Recognition
Jan 04, 2024



While word error rates of automatic speech recognition (ASR) systems have consistently fallen, natural language understanding (NLU) applications built on top of ASR systems still attribute significant numbers of failures to low-quality speech recognition results. Existing assistant systems collect large numbers of these unsuccessful interactions, but these systems usually fail to learn from these interactions, even in an offline fashion. In this work, we introduce CLC: Contrastive Learning for Conversations, a family of methods for contrastive fine-tuning of models in a self-supervised fashion, making use of easily detectable artifacts in unsuccessful conversations with assistants. We demonstrate that our CLC family of approaches can improve the performance of ASR models on OD3, a new public large-scale semi-synthetic meta-dataset of audio task-oriented dialogues, by up to 19.2%. These gains transfer to real-world systems as well, where we show that CLC can help to improve performance by up to 6.7% over baselines. We make OD3 publicly available at https://github.com/amazon-science/amazon-od3 .