 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Named Entity Transcription with Contextual LLM-based Revision
Jun 12, 2025With recent advances in modeling and the increasing amount of supervised training data, automatic speech recognition (ASR) systems have achieved remarkable performance on general speech. However, the word error rate (WER) of state-of-the-art ASR remains high for named entities. Since named entities are often the most critical keywords, misrecognizing them can affect all downstream applications, especially when the ASR system functions as the front end of a complex system. In this paper, we introduce a large language model (LLM) revision mechanism to revise incorrect named entities in ASR predictions by leveraging the LLM's reasoning ability as well as local context (e.g., lecture notes) containing a set of correct named entities. Finally, we introduce the NER-MIT-OpenCourseWare dataset, containing 45 hours of data from MIT courses for development and testing. On this dataset, our proposed technique achieves up to 30\% relative WER reduction for named entities.
Multi-modal Speech Transformer Decoders: When Do Multiple Modalities Improve Accuracy?
Sep 13, 2024Decoder-only discrete-token language models have recently achieved significant success in automatic speech recognition. However, systematic analyses of how different modalities impact performance in specific scenarios remain limited. In this paper, we investigate the effects of multiple modalities on recognition accuracy on both synthetic and real-world datasets. Our experiments suggest that: (1) Integrating more modalities can increase accuracy; in particular, our paper is, to our best knowledge, the first to show the benefit of combining audio, image context, and lip information; (2) Images as a supplementary modality for speech recognition provide the greatest benefit at moderate noise levels, moreover, they exhibit a different trend compared to inherently synchronized modalities like lip movements; (3) Performance improves on both synthetic and real-world datasets when the most relevant visual information is filtered as a preprocessing step.
Discrete Multimodal Transformers with a Pretrained Large Language Model for Mixed-Supervision Speech Processing
Jun 04, 2024Recent work on discrete speech tokenization has paved the way for models that can seamlessly perform multiple tasks across modalities, e.g., speech recognition, text to speech, speech to speech translation. Moreover, large language models (LLMs) pretrained from vast text corpora contain rich linguistic information that can improve accuracy in a variety of tasks. In this paper, we present a decoder-only Discrete Multimodal Language Model (DMLM), which can be flexibly applied to multiple tasks (ASR, T2S, S2TT, etc.) and modalities (text, speech, vision). We explore several critical aspects of discrete multi-modal models, including the loss function, weight initialization, mixed training supervision, and codebook. Our results show that DMLM benefits significantly, across multiple tasks and datasets, from a combination of supervised and unsupervised training. Moreover, for ASR, it benefits from initializing DMLM from a pretrained LLM, and from a codebook derived from Whisper activations.
Two-pass Endpoint Detection for Speech Recognition
Jan 17, 2024Endpoint (EP) detection is a key component of far-field speech recognition systems that assist the user through voice commands. The endpoint detector has to trade-off between accuracy and latency, since waiting longer reduces the cases of users being cut-off early. We propose a novel two-pass solution for endpointing, where the utterance endpoint detected from a first pass endpointer is verified by a 2nd-pass model termed EP Arbitrator. Our method improves the trade-off between early cut-offs and latency over a baseline endpointer, as tested on datasets including voice-assistant transactional queries, conversational speech, and the public SLURP corpus. We demonstrate that our method shows improvements regardless of the first-pass EP model used.
Adaptive Endpointing with Deep Contextual Multi-armed Bandits
Mar 23, 2023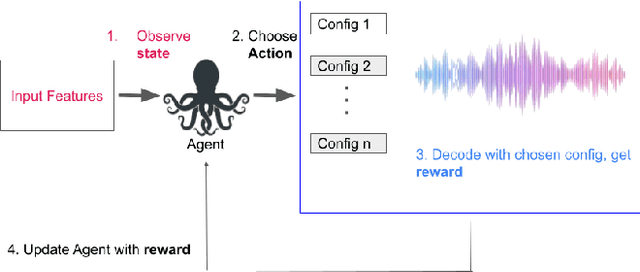

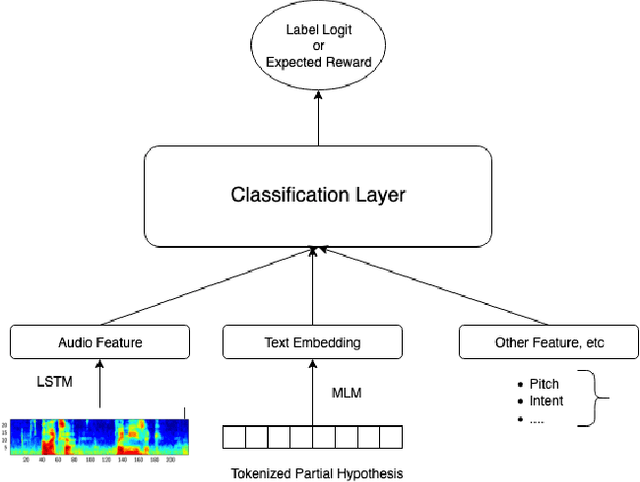
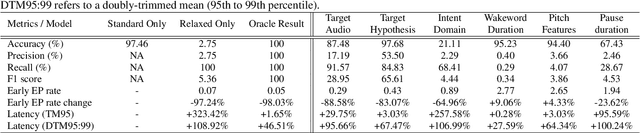
Current endpointing (EP) solutions learn in a supervised framework, which does not allow the model to incorporate feedback and improve in an online setting. Also, it is a common practice to utilize costly grid-search to find the best configuration for an endpointing model. In this paper, we aim to provide a solution for adaptive endpointing by proposing an efficient method for choosing an optimal endpointing configuration given utterance-level audio features in an online setting, while avoiding hyperparameter grid-search. Our method does not require ground truth labels, and only uses online learning from reward signals without requiring annotated labels. Specifically, we propose a deep contextual multi-armed bandit-based approach, which combines the representational power of neural networks with the action exploration behavior of Thompson modeling algorithms. We compare our approach to several baselines, and show that our deep bandit models also succeed in reducing early cutoff errors while maintaining low latency.
Reducing Geographic Disparities in Automatic Speech Recognition via Elastic Weight Consolidation
Jul 16, 2022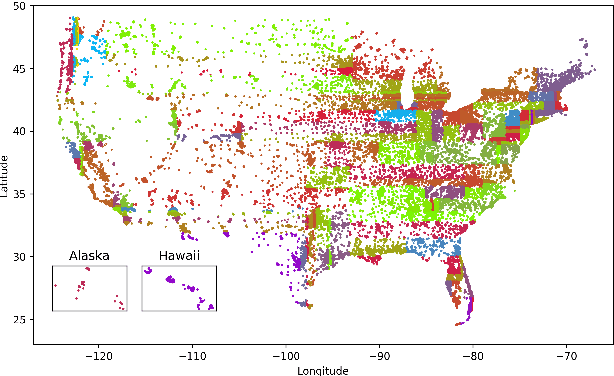

We present an approach to reduce the performance disparity between geographic regions without degrading performance on the overall user population for ASR. A popular approach is to fine-tune the model with data from regions where the ASR model has a higher word error rate (WER). However, when the ASR model is adapted to get better performance on these high-WER regions, its parameters wander from the previous optimal values, which can lead to worse performance in other regions. In our proposed method, we utilize the elastic weight consolidation (EWC) regularization loss to identify directions in parameters space along which the ASR weights can vary to improve for high-error regions, while still maintaining performance on the speaker population overall. Our results demonstrate that EWC can reduce the word error rate (WER) in the region with highest WER by 3.2% relative while reducing the overall WER by 1.3% relative. We also evaluate the role of language and acoustic models in ASR fairness and propose a clustering algorithm to identify WER disparities based on geographic region.
ImportantAug: a data augmentation agent for speech
Dec 14, 2021



We introduce ImportantAug, a technique to augment training data for speech classification and recognition models by adding noise to unimportant regions of the speech and not to important regions. Importance is predicted for each utterance by a data augmentation agent that is trained to maximize the amount of noise it adds while minimizing its impact on recognition performance. The effectiveness of our method is illustrated on version two of the Google Speech Commands (GSC) dataset. On the standard GSC test set, it achieves a 23.3% relative error rate reduction compared to conventional noise augmentation which applies noise to speech without regard to where it might be most effective. It also provides a 25.4% error rate reduction compared to a baseline without data augmentation. Additionally, the proposed ImportantAug outperforms the conventional noise augmentation and the baseline on two test sets with additional noise added.
Unsupervised Speech Enhancement with speech recognition embedding and disentanglement losses
Nov 16, 2021
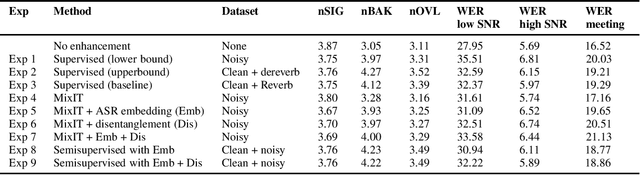
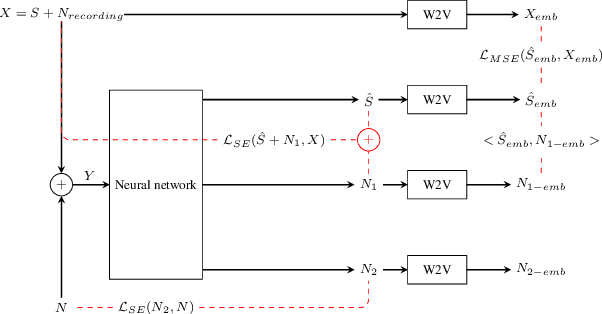
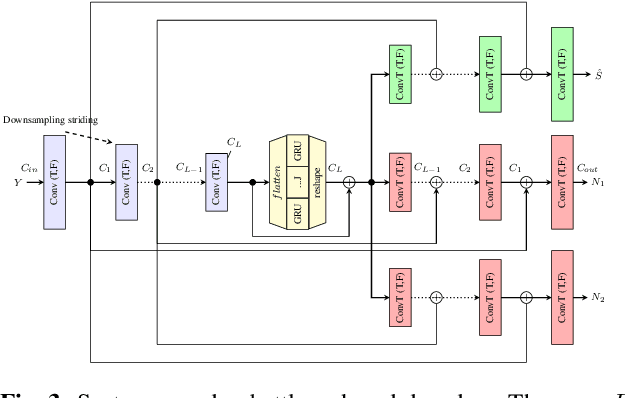
Speech enhancement has recently achieved great success with various deep learning methods. However, most conventional speech enhancement systems are trained with supervised methods that impose two significant challenges. First, a majority of training datasets for speech enhancement systems are synthetic. When mixing clean speech and noisy corpora to create the synthetic datasets, domain mismatches occur between synthetic and real-world recordings of noisy speech or audio. Second, there is a trade-off between increasing speech enhancement performance and degrading speech recognition (ASR) performance. Thus, we propose an unsupervised loss function to tackle those two problems. Our function is developed by extending the MixIT loss function with speech recognition embedding and disentanglement loss. Our results show that the proposed function effectively improves the speech enhancement performance compared to a baseline trained in a supervised way on the noisy VoxCeleb dataset. While fully unsupervised training is unable to exceed the corresponding baseline, with joint super- and unsupervised training, the system is able to achieve similar speech quality and better ASR performance than the best supervised baseline.
Combining Spatial Clustering with LSTM Speech Models for Multichannel Speech Enhancement
Dec 02, 2020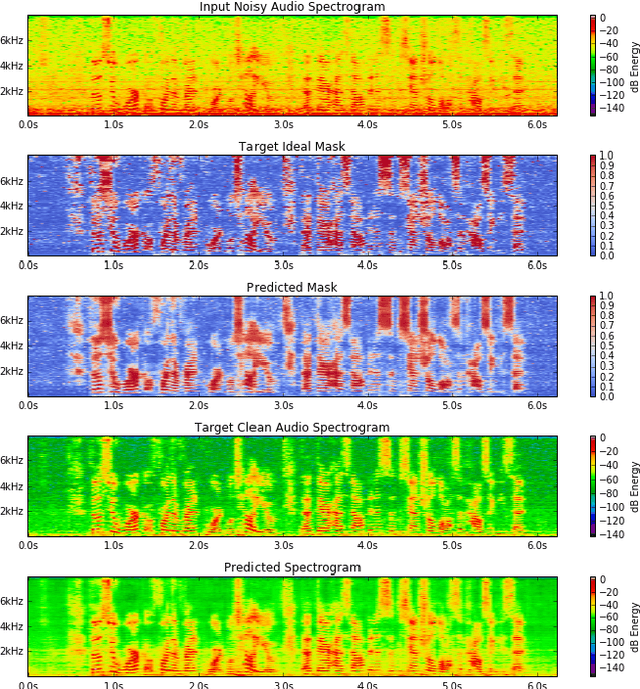
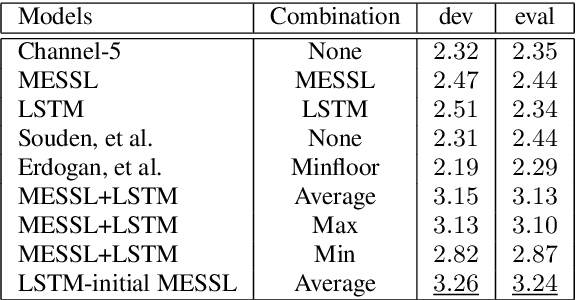
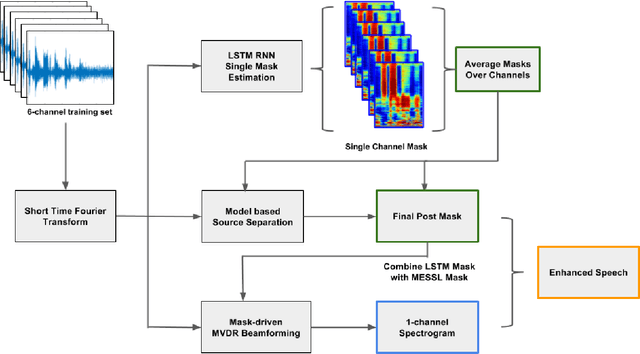
Recurrent neural networks using the LSTM architecture can achieve significant single-channel noise reduction. It is not obvious, however, how to apply them to multi-channel inputs in a way that can generalize to new microphone configurations. In contrast, spatial clustering techniques can achieve such generalization, but lack a strong signal model. This paper combines the two approaches to attain both the spatial separation performance and generality of multichannel spatial clustering and the signal modeling performance of multiple parallel single-channel LSTM speech enhancers. The system is compared to several baselines on the CHiME3 dataset in terms of speech quality predicted by the PESQ algorithm and word error rate of a recognizer trained on mis-matched conditions, in order to focus on generalization. Our experiments show that by combining the LSTM models with the spatial clustering, we reduce word error rate by 4.6\% absolute (17.2\% relative) on the development set and 11.2\% absolute (25.5\% relative) on test set compared with spatial clustering system, and reduce by 10.75\% (32.72\% relative) on development set and 6.12\% absolute (15.76\% relative) on test data compared with LSTM model.
Improved MVDR Beamforming Using LSTM Speech Models to Clean Spatial Clustering Masks
Dec 02, 2020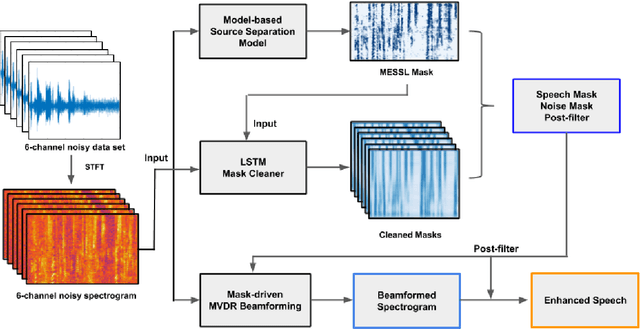
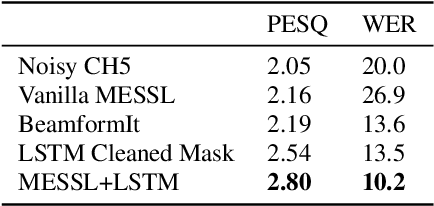
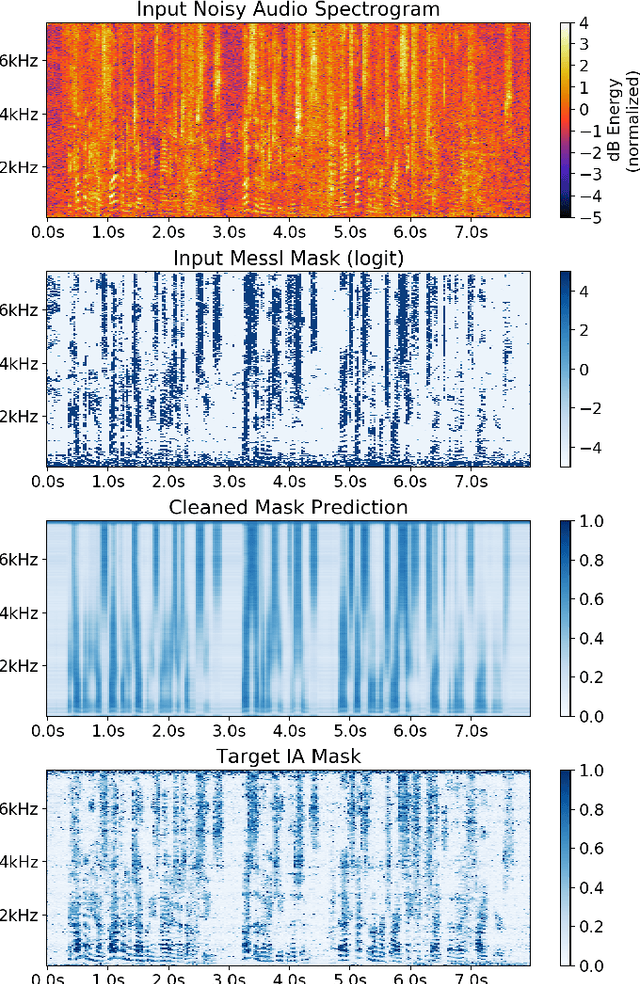
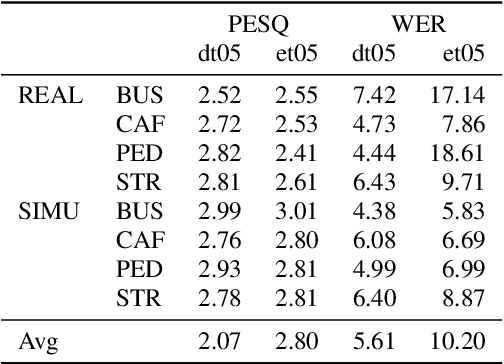
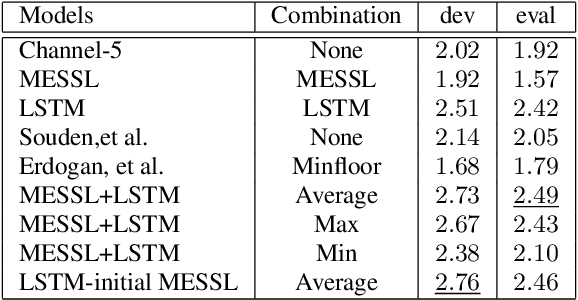
Spatial clustering techniques can achieve significant multi-channel noise reduction across relatively arbitrary microphone configurations, but have difficulty incorporating a detailed speech/noise model. In contrast, LSTM neural networks have successfully been trained to recognize speech from noise on single-channel inputs, but have difficulty taking full advantage of the information in multi-channel recordings. This paper integrates these two approaches, training LSTM speech models to clean the masks generated by the Model-based EM Source Separation and Localization (MESSL) spatial clustering method. By doing so, it attains both the spatial separation performance and generality of multi-channel spatial clustering and the signal modeling performance of multiple parallel single-channel LSTM speech enhancers. Our experiments show that when our system is applied to the CHiME-3 dataset of noisy tablet recordings, it increases speech quality as measured by the Perceptual Evaluation of Speech Quality (PESQ) algorithm and reduces the word error rate of the baseline CHiME-3 speech recognizer, as compared to the default BeamformIt beamformer.