 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnatomy of Industrial Scale Multilingual ASR
Apr 16, 2024
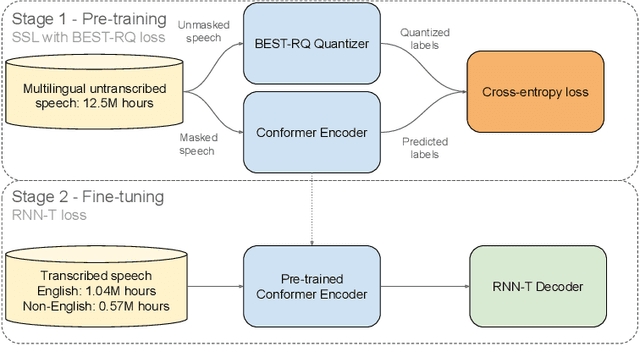


This paper describes AssemblyAI's industrial-scale automatic speech recognition (ASR) system, designed to meet the requirements of large-scale, multilingual ASR serving various application needs. Our system leverages a diverse training dataset comprising unsupervised (12.5M hours), supervised (188k hours), and pseudo-labeled (1.6M hours) data across four languages. We provide a detailed description of our model architecture, consisting of a full-context 600M-parameter Conformer encoder pre-trained with BEST-RQ and an RNN-T decoder fine-tuned jointly with the encoder. Our extensive evaluation demonstrates competitive word error rates (WERs) against larger and more computationally expensive models, such as Whisper large and Canary-1B. Furthermore, our architectural choices yield several key advantages, including an improved code-switching capability, a 5x inference speedup compared to an optimized Whisper baseline, a 30% reduction in hallucination rate on speech data, and a 90% reduction in ambient noise compared to Whisper, along with significantly improved time-stamp accuracy. Throughout this work, we adopt a system-centric approach to analyzing various aspects of fully-fledged ASR models to gain practically relevant insights useful for real-world services operating at scale.
Two-pass Endpoint Detection for Speech Recognition
Jan 17, 2024Endpoint (EP) detection is a key component of far-field speech recognition systems that assist the user through voice commands. The endpoint detector has to trade-off between accuracy and latency, since waiting longer reduces the cases of users being cut-off early. We propose a novel two-pass solution for endpointing, where the utterance endpoint detected from a first pass endpointer is verified by a 2nd-pass model termed EP Arbitrator. Our method improves the trade-off between early cut-offs and latency over a baseline endpointer, as tested on datasets including voice-assistant transactional queries, conversational speech, and the public SLURP corpus. We demonstrate that our method shows improvements regardless of the first-pass EP model used.
Separator-Transducer-Segmenter: Streaming Recognition and Segmentation of Multi-party Speech
May 10, 2022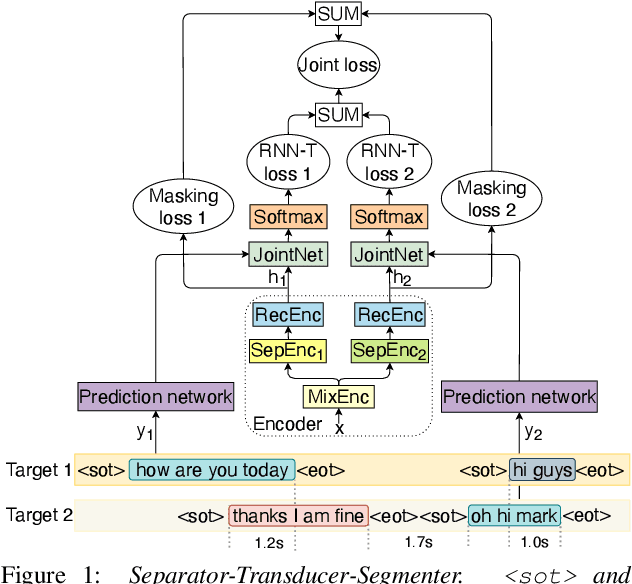


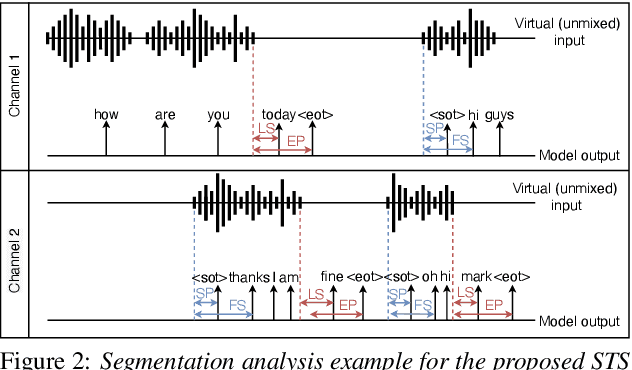
Streaming recognition and segmentation of multi-party conversations with overlapping speech is crucial for the next generation of voice assistant applications. In this work we address its challenges discovered in the previous work on multi-turn recurrent neural network transducer (MT-RNN-T) with a novel approach, separator-transducer-segmenter (STS), that enables tighter integration of speech separation, recognition and segmentation in a single model. First, we propose a new segmentation modeling strategy through start-of-turn and end-of-turn tokens that improves segmentation without recognition accuracy degradation. Second, we further improve both speech recognition and segmentation accuracy through an emission regularization method, FastEmit, and multi-task training with speech activity information as an additional training signal. Third, we experiment with end-of-turn emission latency penalty to improve end-point detection for each speaker turn. Finally, we establish a novel framework for segmentation analysis of multi-party conversations through emission latency metrics. With our best model, we report 4.6% abs. turn counting accuracy improvement and 17% rel. word error rate (WER) improvement on LibriCSS dataset compared to the previously published work.
Multi-turn RNN-T for streaming recognition of multi-party speech
Dec 19, 2021



Automatic speech recognition (ASR) of single channel far-field recordings with an unknown number of speakers is traditionally tackled by cascaded modules. Recent research shows that end-to-end (E2E) multi-speaker ASR models can achieve superior recognition accuracy compared to modular systems. However, these models do not ensure real-time applicability due to their dependency on full audio context. This work takes real-time applicability as the first priority in model design and addresses a few challenges in previous work on multi-speaker recurrent neural network transducer (MS-RNN-T). First, we introduce on-the-fly overlapping speech simulation during training, yielding 14% relative word error rate (WER) improvement on LibriSpeechMix test set. Second, we propose a novel multi-turn RNN-T (MT-RNN-T) model with an overlap-based target arrangement strategy that generalizes to an arbitrary number of speakers without changes in the model architecture. We investigate the impact of the maximum number of speakers seen during training on MT-RNN-T performance on LibriCSS test set, and report 28% relative WER improvement over the two-speaker MS-RNN-T. Third, we experiment with a rich transcription strategy for joint recognition and segmentation of multi-party speech. Through an in-depth analysis, we discuss potential pitfalls of the proposed system as well as promising future research directions.
Streaming Multi-speaker ASR with RNN-T
Nov 23, 2020
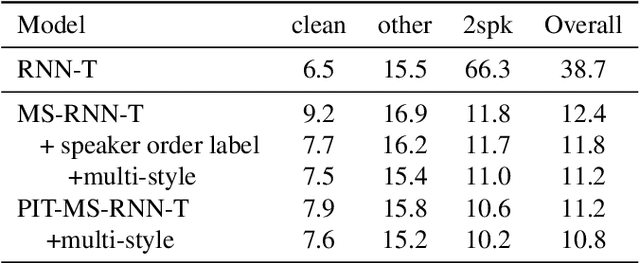
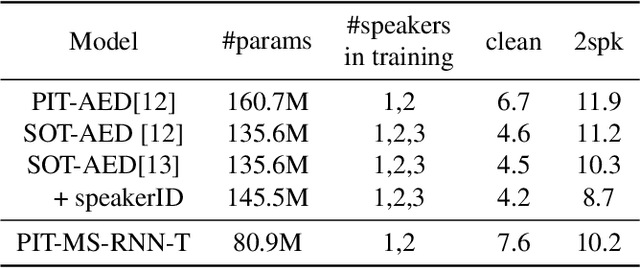
Recent research shows end-to-end ASR systems can recognize overlapped speech from multiple speakers. However, all published works have assumed no latency constraints during inference, which does not hold for most voice assistant interactions. This work focuses on multi-speaker speech recognition based on a recurrent neural network transducer (RNN-T) that has been shown to provide high recognition accuracy at a low latency online recognition regime. We investigate two approaches to multi-speaker model training of the RNN-T: deterministic output-target assignment and permutation invariant training. We show that guiding separation with speaker order labels in the former case enhances the high-level speaker tracking capability of RNN-T. Apart from that, with multistyle training on single- and multi-speaker utterances, the resulting models gain robustness against ambiguous numbers of speakers during inference. Our best model achieves a WER of 10.2% on simulated 2-speaker LibriSpeech data, which is competitive with the previously reported state-of-the-art nonstreaming model (10.3%), while the proposed model could be directly applied for streaming applications.
Analysis of Deep Clustering as Preprocessing for Automatic Speech Recognition of Sparsely Overlapping Speech
May 09, 2019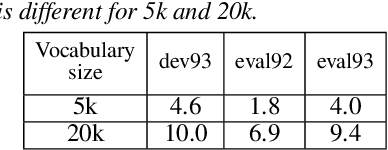
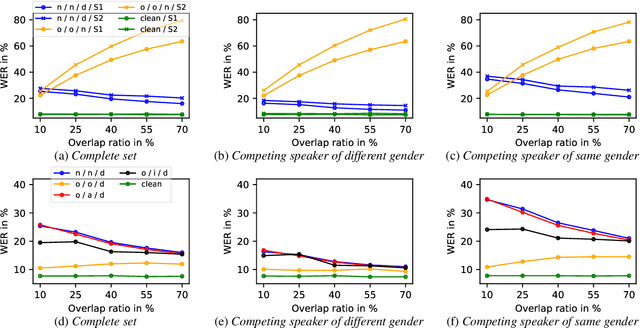
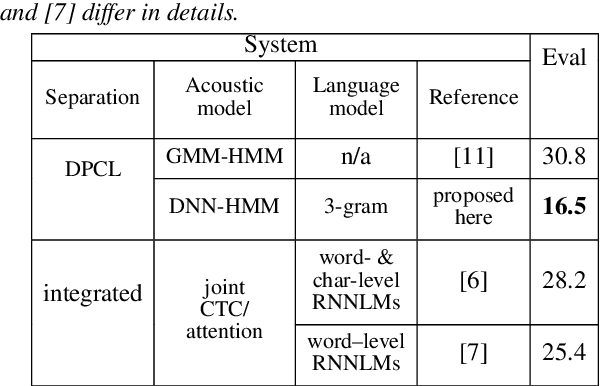
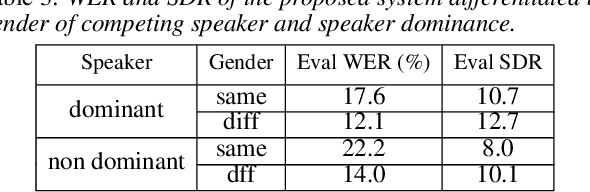
Significant performance degradation of automatic speech recognition (ASR) systems is observed when the audio signal contains cross-talk. One of the recently proposed approaches to solve the problem of multi-speaker ASR is the deep clustering (DPCL) approach. Combining DPCL with a state-of-the-art hybrid acoustic model, we obtain a word error rate (WER) of 16.5 % on the commonly used wsj0-2mix dataset, which is the best performance reported thus far to the best of our knowledge. The wsj0-2mix dataset contains simulated cross-talk where the speech of multiple speakers overlaps for almost the entire utterance. In a more realistic ASR scenario the audio signal contains significant portions of single-speaker speech and only part of the signal contains speech of multiple competing speakers. This paper investigates obstacles of applying DPCL as a preprocessing method for ASR in such a scenario of sparsely overlapping speech. To this end we present a data simulation approach, closely related to the wsj0-2mix dataset, generating sparsely overlapping speech datasets of arbitrary overlap ratio. The analysis of applying DPCL to sparsely overlapping speech is an important interim step between the fully overlapping datasets like wsj0-2mix and more realistic ASR datasets, such as CHiME-5 or AMI.