 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnatomy of Industrial Scale Multilingual ASR
Apr 16, 2024
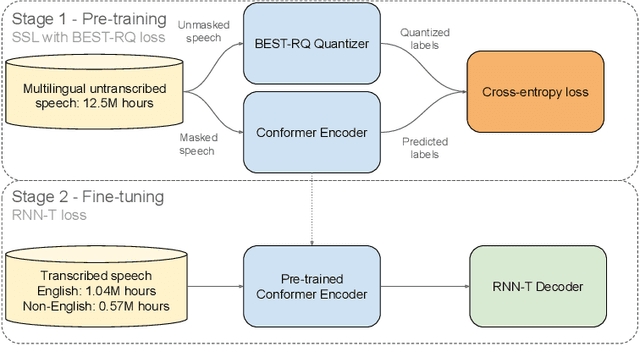


This paper describes AssemblyAI's industrial-scale automatic speech recognition (ASR) system, designed to meet the requirements of large-scale, multilingual ASR serving various application needs. Our system leverages a diverse training dataset comprising unsupervised (12.5M hours), supervised (188k hours), and pseudo-labeled (1.6M hours) data across four languages. We provide a detailed description of our model architecture, consisting of a full-context 600M-parameter Conformer encoder pre-trained with BEST-RQ and an RNN-T decoder fine-tuned jointly with the encoder. Our extensive evaluation demonstrates competitive word error rates (WERs) against larger and more computationally expensive models, such as Whisper large and Canary-1B. Furthermore, our architectural choices yield several key advantages, including an improved code-switching capability, a 5x inference speedup compared to an optimized Whisper baseline, a 30% reduction in hallucination rate on speech data, and a 90% reduction in ambient noise compared to Whisper, along with significantly improved time-stamp accuracy. Throughout this work, we adopt a system-centric approach to analyzing various aspects of fully-fledged ASR models to gain practically relevant insights useful for real-world services operating at scale.
Practical Conformer: Optimizing size, speed and flops of Conformer for on-Device and cloud ASR
Mar 31, 2023

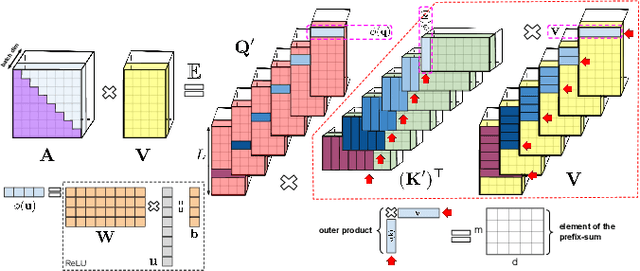

Conformer models maintain a large number of internal states, the vast majority of which are associated with self-attention layers. With limited memory bandwidth, reading these from memory at each inference step can slow down inference. In this paper, we design an optimized conformer that is small enough to meet on-device restrictions and has fast inference on TPUs. We explore various ideas to improve the execution speed, including replacing lower conformer blocks with convolution-only blocks, strategically downsizing the architecture, and utilizing an RNNAttention-Performer. Our optimized conformer can be readily incorporated into a cascaded-encoder setting, allowing a second-pass decoder to operate on its output and improve the accuracy whenever more resources are available. Altogether, we find that these optimizations can reduce latency by a factor of 6.8x, and come at a reasonable trade-off in quality. With the cascaded second-pass, we show that the recognition accuracy is completely recoverable. Thus, our proposed encoder can double as a strong standalone encoder in on device, and as the first part of a high-performance ASR pipeline.
Lego-Features: Exporting modular encoder features for streaming and deliberation ASR
Mar 31, 2023In end-to-end (E2E) speech recognition models, a representational tight-coupling inevitably emerges between the encoder and the decoder. We build upon recent work that has begun to explore building encoders with modular encoded representations, such that encoders and decoders from different models can be stitched together in a zero-shot manner without further fine-tuning. While previous research only addresses full-context speech models, we explore the problem in a streaming setting as well. Our framework builds on top of existing encoded representations, converting them to modular features, dubbed as Lego-Features, without modifying the pre-trained model. The features remain interchangeable when the model is retrained with distinct initializations. Though sparse, we show that the Lego-Features are powerful when tested with RNN-T or LAS decoders, maintaining high-quality downstream performance. They are also rich enough to represent the first-pass prediction during two-pass deliberation. In this scenario, they outperform the N-best hypotheses, since they do not need to be supplemented with acoustic features to deliver the best results. Moreover, generating the Lego-Features does not require beam search or auto-regressive computation. Overall, they present a modular, powerful and cheap alternative to the standard encoder output, as well as the N-best hypotheses.
A Unified Cascaded Encoder ASR Model for Dynamic Model Sizes
Apr 20, 2022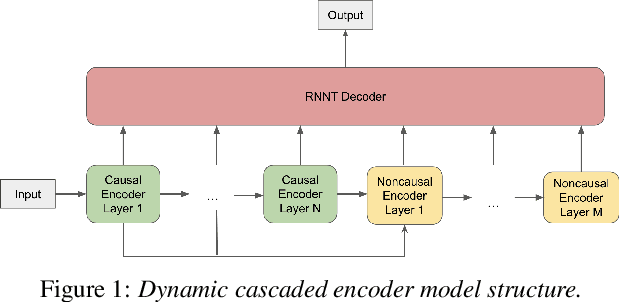
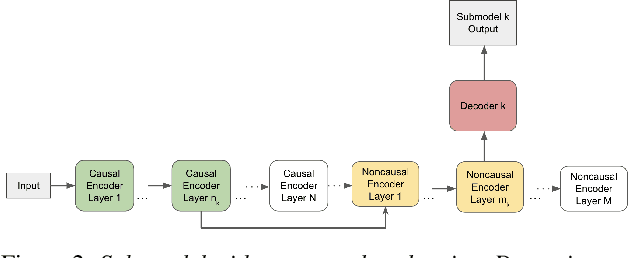
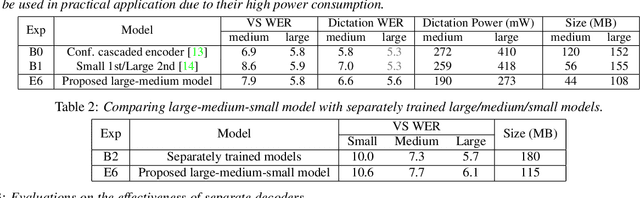
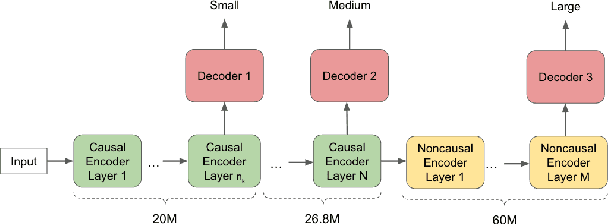
In this paper, we propose a dynamic cascaded encoder Automatic Speech Recognition (ASR) model, which unifies models for different deployment scenarios. Moreover, the model can significantly reduce model size and power consumption without loss of quality. Namely, with the dynamic cascaded encoder model, we explore three techniques to maximally boost the performance of each model size: 1) Use separate decoders for each sub-model while sharing the encoders; 2) Use funnel-pooling to improve the encoder efficiency; 3) Balance the size of causal and non-causal encoders to improve quality and fit deployment constraints. Overall, the proposed large-medium model has 30% smaller size and reduces power consumption by 33%, compared to the baseline cascaded encoder model. The triple-size model that unifies the large, medium, and small models achieves 37% total size reduction with minimal quality loss, while substantially reducing the engineering efforts of having separate models.
Tied & Reduced RNN-T Decoder
Sep 15, 2021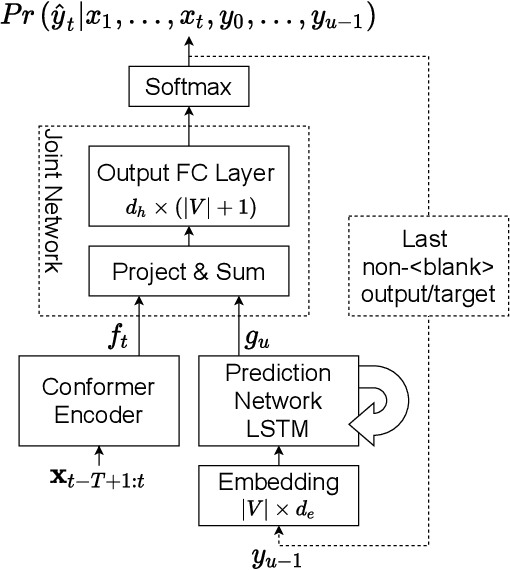
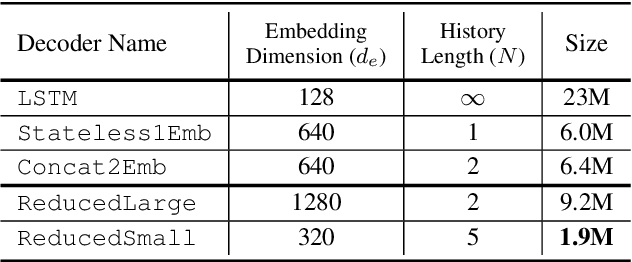
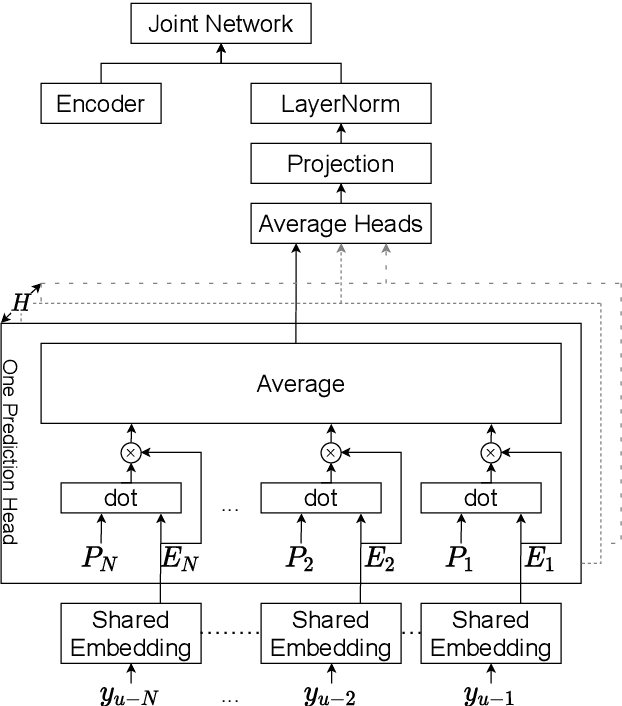
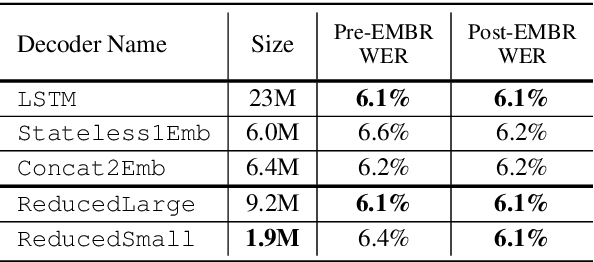
Previous works on the Recurrent Neural Network-Transducer (RNN-T) models have shown that, under some conditions, it is possible to simplify its prediction network with little or no loss in recognition accuracy (arXiv:2003.07705 [eess.AS], [2], arXiv:2012.06749 [cs.CL]). This is done by limiting the context size of previous labels and/or using a simpler architecture for its layers instead of LSTMs. The benefits of such changes include reduction in model size, faster inference and power savings, which are all useful for on-device applications. In this work, we study ways to make the RNN-T decoder (prediction network + joint network) smaller and faster without degradation in recognition performance. Our prediction network performs a simple weighted averaging of the input embeddings, and shares its embedding matrix weights with the joint network's output layer (a.k.a. weight tying, commonly used in language modeling arXiv:1611.01462 [cs.LG]). This simple design, when used in conjunction with additional Edit-based Minimum Bayes Risk (EMBR) training, reduces the RNN-T Decoder from 23M parameters to just 2M, without affecting word-error rate (WER).
Connecting and Comparing Language Model Interpolation Techniques
Aug 26, 2019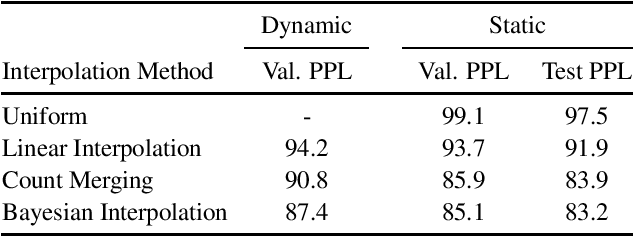
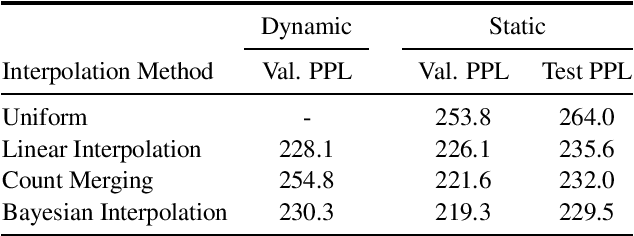
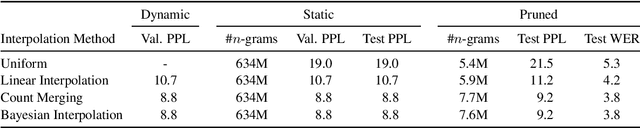
In this work, we uncover a theoretical connection between two language model interpolation techniques, count merging and Bayesian interpolation. We compare these techniques as well as linear interpolation in three scenarios with abundant training data per component model. Consistent with prior work, we show that both count merging and Bayesian interpolation outperform linear interpolation. We include the first (to our knowledge) published comparison of count merging and Bayesian interpolation, showing that the two techniques perform similarly. Finally, we argue that other considerations will make Bayesian interpolation the preferred approach in most circumstances.