 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonalization of CTC-based End-to-End Speech Recognition Using Pronunciation-Driven Subword Tokenization
Oct 16, 2023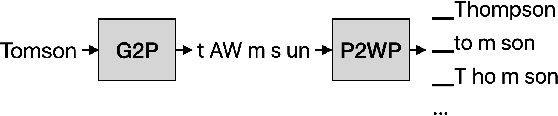


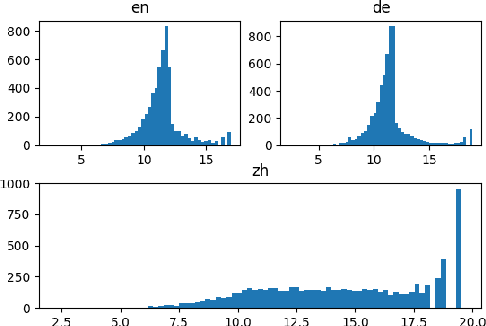
Recent advances in deep learning and automatic speech recognition have improved the accuracy of end-to-end speech recognition systems, but recognition of personal content such as contact names remains a challenge. In this work, we describe our personalization solution for an end-to-end speech recognition system based on connectionist temporal classification. Building on previous work, we present a novel method for generating additional subword tokenizations for personal entities from their pronunciations. We show that using this technique in combination with two established techniques, contextual biasing and wordpiece prior normalization, we are able to achieve personal named entity accuracy on par with a competitive hybrid system.
Acoustic Model Fusion for End-to-end Speech Recognition
Oct 10, 2023

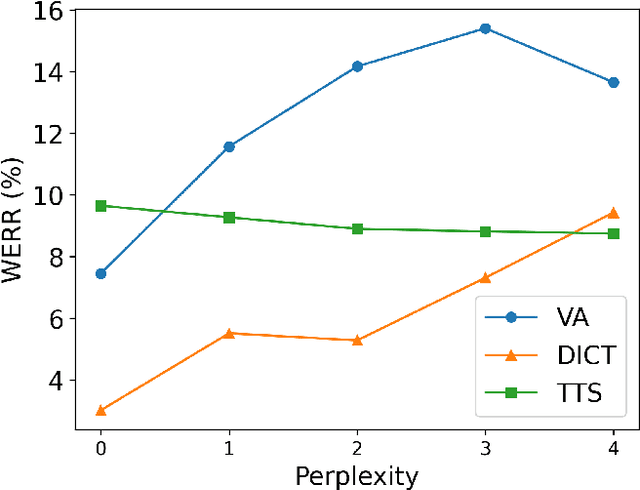
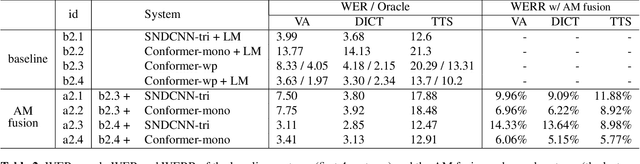
Recent advances in deep learning and automatic speech recognition (ASR) have enabled the end-to-end (E2E) ASR system and boosted the accuracy to a new level. The E2E systems implicitly model all conventional ASR components, such as the acoustic model (AM) and the language model (LM), in a single network trained on audio-text pairs. Despite this simpler system architecture, fusing a separate LM, trained exclusively on text corpora, into the E2E system has proven to be beneficial. However, the application of LM fusion presents certain drawbacks, such as its inability to address the domain mismatch issue inherent to the internal AM. Drawing inspiration from the concept of LM fusion, we propose the integration of an external AM into the E2E system to better address the domain mismatch. By implementing this novel approach, we have achieved a significant reduction in the word error rate, with an impressive drop of up to 14.3% across varied test sets. We also discovered that this AM fusion approach is particularly beneficial in enhancing named entity recognition.
Space-Efficient Representation of Entity-centric Query Language Models
Jun 29, 2022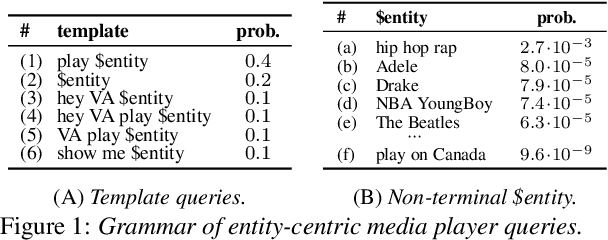

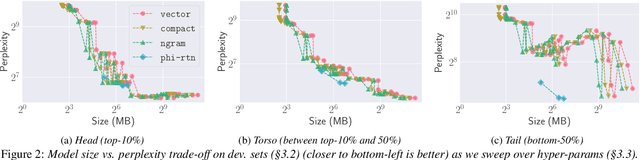
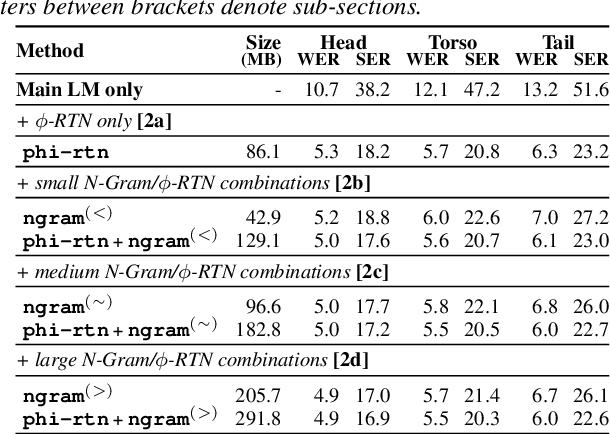
Virtual assistants make use of automatic speech recognition (ASR) to help users answer entity-centric queries. However, spoken entity recognition is a difficult problem, due to the large number of frequently-changing named entities. In addition, resources available for recognition are constrained when ASR is performed on-device. In this work, we investigate the use of probabilistic grammars as language models within the finite-state transducer (FST) framework. We introduce a deterministic approximation to probabilistic grammars that avoids the explicit expansion of non-terminals at model creation time, integrates directly with the FST framework, and is complementary to n-gram models. We obtain a 10% relative word error rate improvement on long tail entity queries compared to when a similarly-sized n-gram model is used without our method.
Connecting and Comparing Language Model Interpolation Techniques
Aug 26, 2019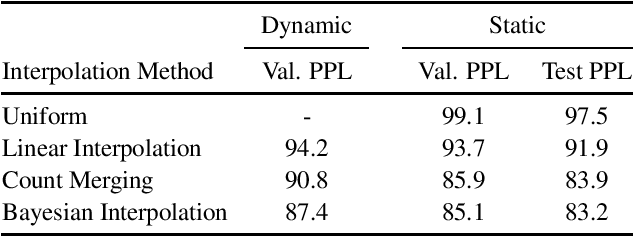
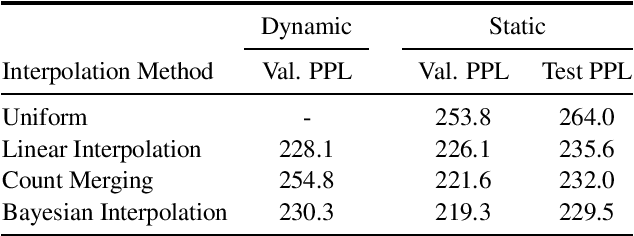
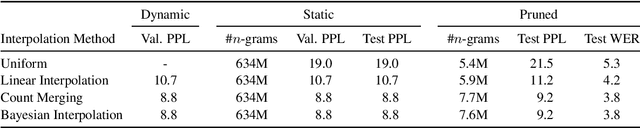
In this work, we uncover a theoretical connection between two language model interpolation techniques, count merging and Bayesian interpolation. We compare these techniques as well as linear interpolation in three scenarios with abundant training data per component model. Consistent with prior work, we show that both count merging and Bayesian interpolation outperform linear interpolation. We include the first (to our knowledge) published comparison of count merging and Bayesian interpolation, showing that the two techniques perform similarly. Finally, we argue that other considerations will make Bayesian interpolation the preferred approach in most circumstances.