 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoupling Training-Free Guided Diffusion by ADMM
Nov 18, 2024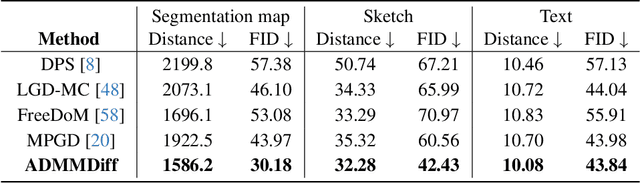
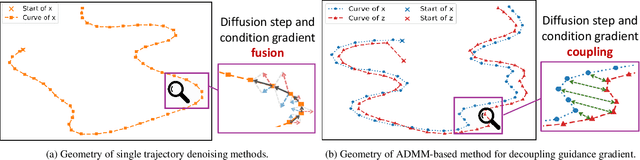


In this paper, we consider the conditional generation problem by guiding off-the-shelf unconditional diffusion models with differentiable loss functions in a plug-and-play fashion. While previous research has primarily focused on balancing the unconditional diffusion model and the guided loss through a tuned weight hyperparameter, we propose a novel framework that distinctly decouples these two components. Specifically, we introduce two variables ${x}$ and ${z}$, to represent the generated samples governed by the unconditional generation model and the guidance function, respectively. This decoupling reformulates conditional generation into two manageable subproblems, unified by the constraint ${x} = {z}$. Leveraging this setup, we develop a new algorithm based on the Alternating Direction Method of Multipliers (ADMM) to adaptively balance these components. Additionally, we establish the equivalence between the diffusion reverse step and the proximal operator of ADMM and provide a detailed convergence analysis of our algorithm under certain mild assumptions. Our experiments demonstrate that our proposed method ADMMDiff consistently generates high-quality samples while ensuring strong adherence to the conditioning criteria. It outperforms existing methods across a range of conditional generation tasks, including image generation with various guidance and controllable motion synthesis.
Design Editing for Offline Model-based Optimization
May 22, 2024



Offline model-based optimization (MBO) aims to maximize a black-box objective function using only an offline dataset of designs and scores. A prevalent approach involves training a conditional generative model on existing designs and their associated scores, followed by the generation of new designs conditioned on higher target scores. However, these newly generated designs often underperform due to the lack of high-scoring training data. To address this challenge, we introduce a novel method, Design Editing for Offline Model-based Optimization (DEMO), which consists of two phases. In the first phase, termed pseudo-target distribution generation, we apply gradient ascent on the offline dataset using a trained surrogate model, producing a synthetic dataset where the predicted scores serve as new labels. A conditional diffusion model is subsequently trained on this synthetic dataset to capture a pseudo-target distribution, which enhances the accuracy of the conditional diffusion model in generating higher-scoring designs. Nevertheless, the pseudo-target distribution is susceptible to noise stemming from inaccuracies in the surrogate model, consequently predisposing the conditional diffusion model to generate suboptimal designs. We hence propose the second phase, existing design editing, to directly incorporate the high-scoring features from the offline dataset into design generation. In this phase, top designs from the offline dataset are edited by introducing noise, which are subsequently refined using the conditional diffusion model to produce high-scoring designs. Overall, high-scoring designs begin with inheriting high-scoring features from the second phase and are further refined with a more accurate conditional diffusion model in the first phase. Empirical evaluations on 7 offline MBO tasks show that DEMO outperforms various baseline methods.
FastVideoEdit: Leveraging Consistency Models for Efficient Text-to-Video Editing
Mar 10, 2024



Diffusion models have demonstrated remarkable capabilities in text-to-image and text-to-video generation, opening up possibilities for video editing based on textual input. However, the computational cost associated with sequential sampling in diffusion models poses challenges for efficient video editing. Existing approaches relying on image generation models for video editing suffer from time-consuming one-shot fine-tuning, additional condition extraction, or DDIM inversion, making real-time applications impractical. In this work, we propose FastVideoEdit, an efficient zero-shot video editing approach inspired by Consistency Models (CMs). By leveraging the self-consistency property of CMs, we eliminate the need for time-consuming inversion or additional condition extraction, reducing editing time. Our method enables direct mapping from source video to target video with strong preservation ability utilizing a special variance schedule. This results in improved speed advantages, as fewer sampling steps can be used while maintaining comparable generation quality. Experimental results validate the state-of-the-art performance and speed advantages of FastVideoEdit across evaluation metrics encompassing editing speed, temporal consistency, and text-video alignment.
Server-side Rescoring of Spoken Entity-centric Knowledge Queries for Virtual Assistants
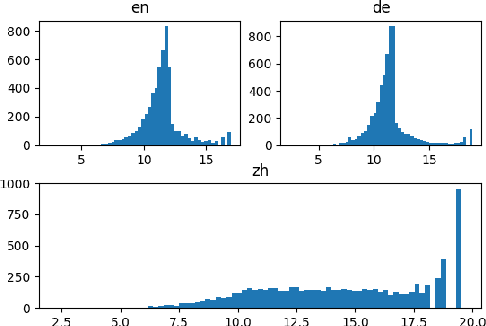
Nov 02, 2023On-device Virtual Assistants (VAs) powered by Automatic Speech Recognition (ASR) require effective knowledge integration for the challenging entity-rich query recognition. In this paper, we conduct an empirical study of modeling strategies for server-side rescoring of spoken information domain queries using various categories of Language Models (LMs) (N-gram word LMs, sub-word neural LMs). We investigate the combination of on-device and server-side signals, and demonstrate significant WER improvements of 23%-35% on various entity-centric query subpopulations by integrating various server-side LMs compared to performing ASR on-device only. We also perform a comparison between LMs trained on domain data and a GPT-3 variant offered by OpenAI as a baseline. Furthermore, we also show that model fusion of multiple server-side LMs trained from scratch most effectively combines complementary strengths of each model and integrates knowledge learned from domain-specific data to a VA ASR system.
Personalization of CTC-based End-to-End Speech Recognition Using Pronunciation-Driven Subword Tokenization
Oct 16, 2023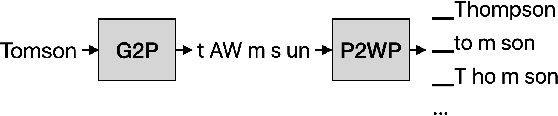


Recent advances in deep learning and automatic speech recognition have improved the accuracy of end-to-end speech recognition systems, but recognition of personal content such as contact names remains a challenge. In this work, we describe our personalization solution for an end-to-end speech recognition system based on connectionist temporal classification. Building on previous work, we present a novel method for generating additional subword tokenizations for personal entities from their pronunciations. We show that using this technique in combination with two established techniques, contextual biasing and wordpiece prior normalization, we are able to achieve personal named entity accuracy on par with a competitive hybrid system.
Techniques to Improve Neural Math Word Problem Solvers
Feb 06, 2023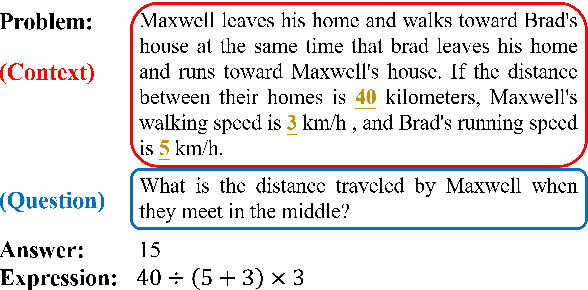
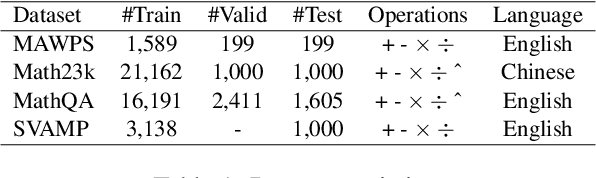
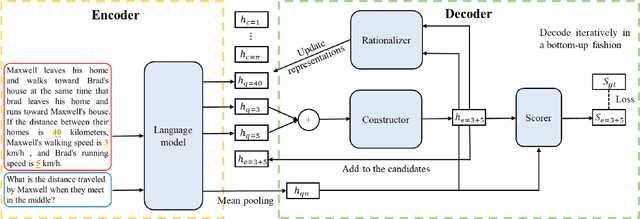

Developing automatic Math Word Problem (MWP) solvers is a challenging task that demands the ability of understanding and mathematical reasoning over the natural language. Recent neural-based approaches mainly encode the problem text using a language model and decode a mathematical expression over quantities and operators iteratively. Note the problem text of a MWP consists of a context part and a question part, a recent work finds these neural solvers may only perform shallow pattern matching between the context text and the golden expression, where question text is not well used. Meanwhile, existing decoding processes fail to enforce the mathematical laws into the design, where the representations for mathematical equivalent expressions are different. To address these two issues, we propose a new encoder-decoder architecture that fully leverages the question text and preserves step-wise commutative law. Besides generating quantity embeddings, our encoder further encodes the question text and uses it to guide the decoding process. At each step, our decoder uses Deep Sets to compute expression representations so that these embeddings are invariant under any permutation of quantities. Experiments on four established benchmarks demonstrate that our framework outperforms state-of-the-art neural MWP solvers, showing the effectiveness of our techniques. We also conduct a detailed analysis of the results to show the limitations of our approach and further discuss the potential future work. Code is available at https://github.com/sophistz/Question-Aware-Deductive-MWP.
Distinctive Image Captioning via CLIP Guided Group Optimization
Aug 14, 2022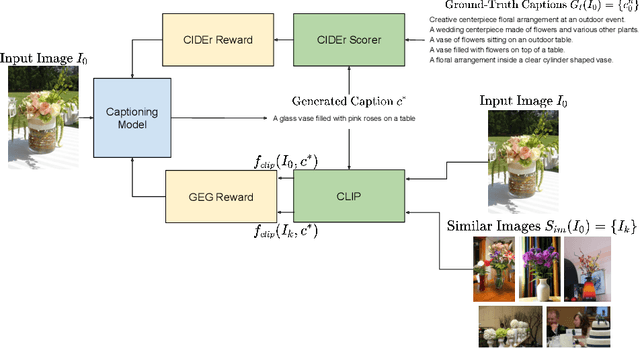
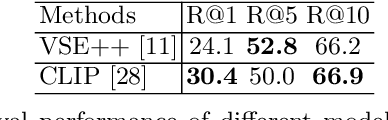
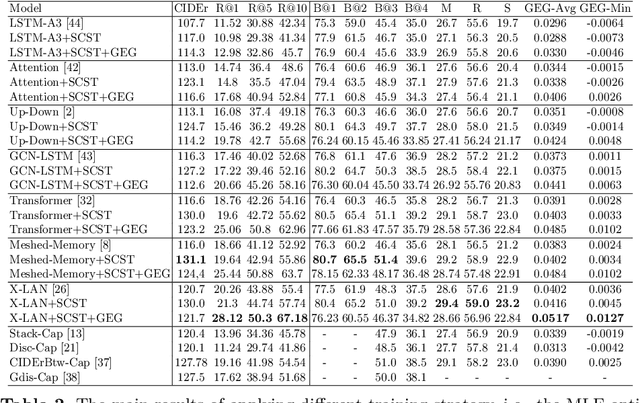
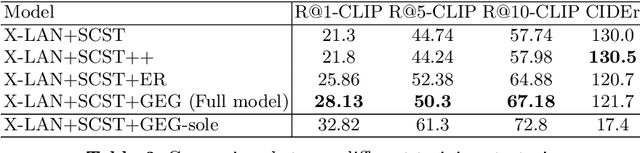
Image captioning models are usually trained according to human annotated ground-truth captions, which could generate accurate but generic captions. In this paper, we focus on generating the distinctive captions that can distinguish the target image from other similar images. To evaluate the distinctiveness of captions, we introduce a series of metrics that use large-scale vision-language pre-training model CLIP to quantify the distinctiveness. To further improve the distinctiveness of captioning models, we propose a simple and effective training strategy which trains the model by comparing target image with similar image group and optimizing the group embedding gap. Extensive experiments are conducted on various baseline models to demonstrate the wide applicability of our strategy and the consistency of metric results with human evaluation. By comparing the performance of our best model with existing state-of-the-art models, we claim that our model achieves new state-of-the-art towards distinctiveness objective.