 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParthenon Law: A Self-Evolving Legal-Agent Framework
Jun 03, 2026As agents grow more capable, legal-domain LLM agents promise to turn document-heavy matters into reviewable work products -- yet reliable deployment faces three obstacles: no large-scale evidence on how today's strongest model-and-harness combinations behave on end-to-end legal matters; no agent architecture adapted to the legal vertical, only general-purpose harnesses; and, in a setting that keeps shifting with new facts, authorities, and deadlines, no mechanism for systems to learn from their own outcomes. We address each. A large-scale empirical study on Harvey LAB -- $12{,}510$ agent trajectories -- shows that even frontier agents remain far from completing matters in a single pass: per-criterion accuracy climbs with stronger models while strict matter completion stalls. We then introduce \textsc{Parthenon}, a self-evolving legal-agent framework that factors Model, Harness, Agent roles, legal Knowledge, deterministic Tools, and procedural Skills into auditable surfaces for source traceability, date and number grounding, deliverable compliance, and issue closure. Finally, an anti-leakage learning loop converts scored failures into task-agnostic edits to skills, tools, and knowledge, letting the system improve with experience -- as a firm refines its checklists and playbooks after each matter -- without touching model weights. Across our large-scale empirical analysis, \textsc{Parthenon} substantially improves the performance of state-of-the-art models and harnesses on legal-matter tasks.
Clo-HDnn: A 4.66 TFLOPS/W and 3.78 TOPS/W Continual On-Device Learning Accelerator with Energy-efficient Hyperdimensional Computing via Progressive Search
Jul 23, 2025Clo-HDnn is an on-device learning (ODL) accelerator designed for emerging continual learning (CL) tasks. Clo-HDnn integrates hyperdimensional computing (HDC) along with low-cost Kronecker HD Encoder and weight clustering feature extraction (WCFE) to optimize accuracy and efficiency. Clo-HDnn adopts gradient-free CL to efficiently update and store the learned knowledge in the form of class hypervectors. Its dual-mode operation enables bypassing costly feature extraction for simpler datasets, while progressive search reduces complexity by up to 61% by encoding and comparing only partial query hypervectors. Achieving 4.66 TFLOPS/W (FE) and 3.78 TOPS/W (classifier), Clo-HDnn delivers 7.77x and 4.85x higher energy efficiency compared to SOTA ODL accelerators.
OpenAI o1 System Card
Dec 21, 2024



The o1 model series is trained with large-scale reinforcement learning to reason using chain of thought. These advanced reasoning capabilities provide new avenues for improving the safety and robustness of our models. In particular, our models can reason about our safety policies in context when responding to potentially unsafe prompts, through deliberative alignment. This leads to state-of-the-art performance on certain benchmarks for risks such as generating illicit advice, choosing stereotyped responses, and succumbing to known jailbreaks. Training models to incorporate a chain of thought before answering has the potential to unlock substantial benefits, while also increasing potential risks that stem from heightened intelligence. Our results underscore the need for building robust alignment methods, extensively stress-testing their efficacy, and maintaining meticulous risk management protocols. This report outlines the safety work carried out for the OpenAI o1 and OpenAI o1-mini models, including safety evaluations, external red teaming, and Preparedness Framework evaluations.
Personalization of CTC-based End-to-End Speech Recognition Using Pronunciation-Driven Subword Tokenization
Oct 16, 2023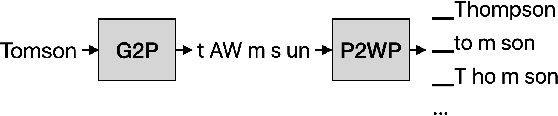


Recent advances in deep learning and automatic speech recognition have improved the accuracy of end-to-end speech recognition systems, but recognition of personal content such as contact names remains a challenge. In this work, we describe our personalization solution for an end-to-end speech recognition system based on connectionist temporal classification. Building on previous work, we present a novel method for generating additional subword tokenizations for personal entities from their pronunciations. We show that using this technique in combination with two established techniques, contextual biasing and wordpiece prior normalization, we are able to achieve personal named entity accuracy on par with a competitive hybrid system.
Acoustic Model Fusion for End-to-end Speech Recognition
Oct 10, 2023

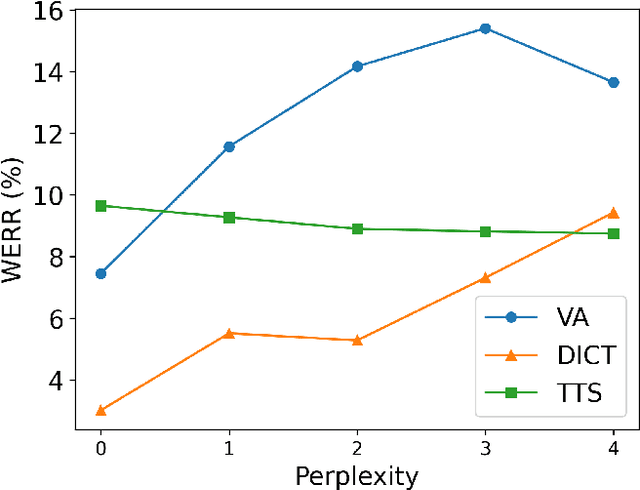
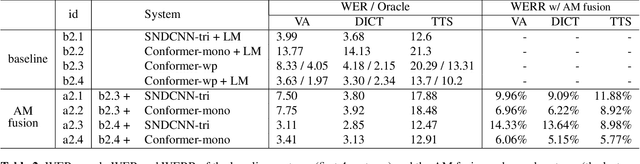
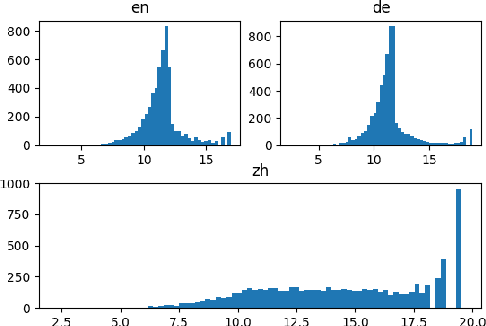
Recent advances in deep learning and automatic speech recognition (ASR) have enabled the end-to-end (E2E) ASR system and boosted the accuracy to a new level. The E2E systems implicitly model all conventional ASR components, such as the acoustic model (AM) and the language model (LM), in a single network trained on audio-text pairs. Despite this simpler system architecture, fusing a separate LM, trained exclusively on text corpora, into the E2E system has proven to be beneficial. However, the application of LM fusion presents certain drawbacks, such as its inability to address the domain mismatch issue inherent to the internal AM. Drawing inspiration from the concept of LM fusion, we propose the integration of an external AM into the E2E system to better address the domain mismatch. By implementing this novel approach, we have achieved a significant reduction in the word error rate, with an impressive drop of up to 14.3% across varied test sets. We also discovered that this AM fusion approach is particularly beneficial in enhancing named entity recognition.
AlerTiger: Deep Learning for AI Model Health Monitoring at LinkedIn
Jun 03, 2023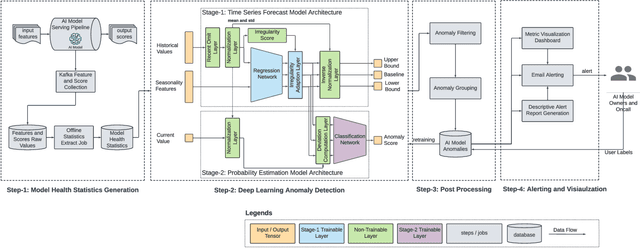
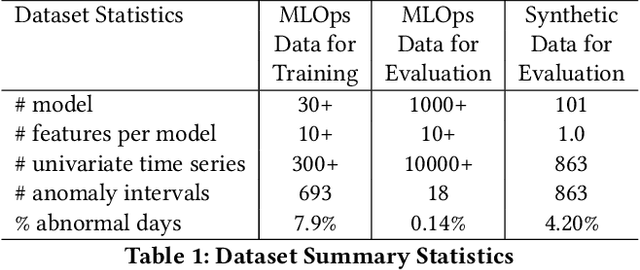
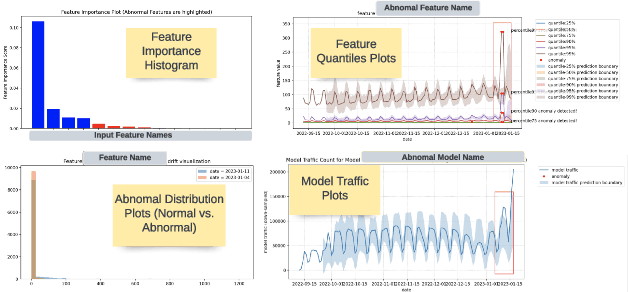
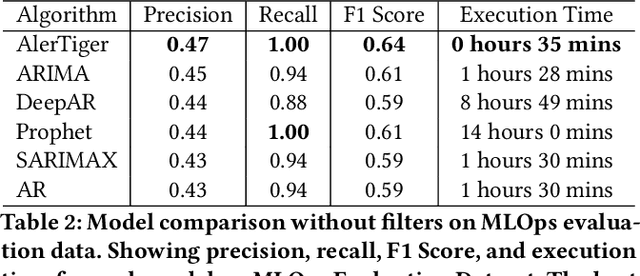
Data-driven companies use AI models extensively to develop products and intelligent business solutions, making the health of these models crucial for business success. Model monitoring and alerting in industries pose unique challenges, including a lack of clear model health metrics definition, label sparsity, and fast model iterations that result in short-lived models and features. As a product, there are also requirements for scalability, generalizability, and explainability. To tackle these challenges, we propose AlerTiger, a deep-learning-based MLOps model monitoring system that helps AI teams across the company monitor their AI models' health by detecting anomalies in models' input features and output score over time. The system consists of four major steps: model statistics generation, deep-learning-based anomaly detection, anomaly post-processing, and user alerting. Our solution generates three categories of statistics to indicate AI model health, offers a two-stage deep anomaly detection solution to address label sparsity and attain the generalizability of monitoring new models, and provides holistic reports for actionable alerts. This approach has been deployed to most of LinkedIn's production AI models for over a year and has identified several model issues that later led to significant business metric gains after fixing.
Training Large-Vocabulary Neural Language Models by Private Federated Learning for Resource-Constrained Devices
Jul 18, 2022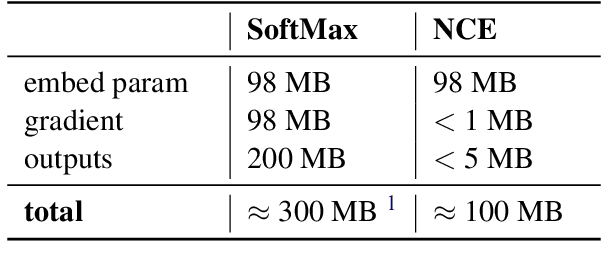
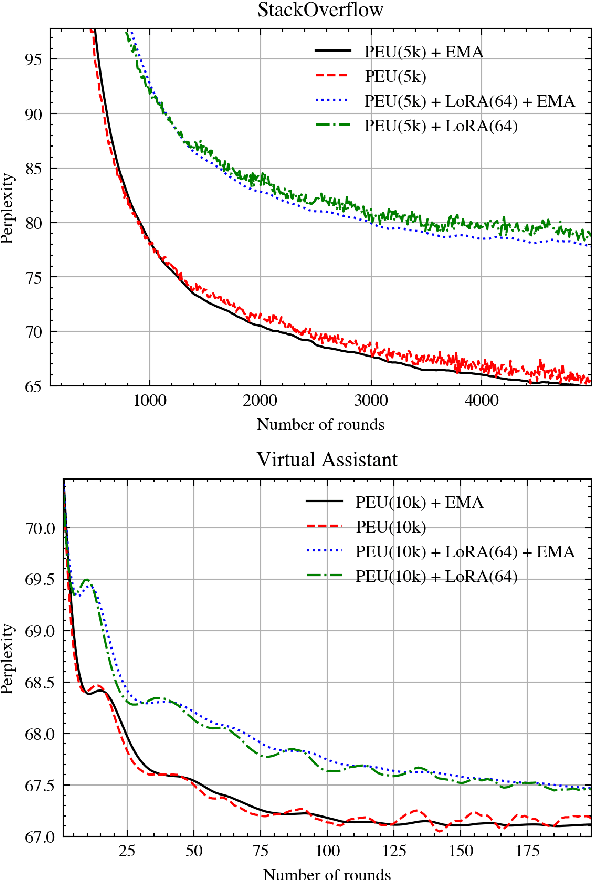

Federated Learning (FL) is a technique to train models using data distributed across devices. Differential Privacy (DP) provides a formal privacy guarantee for sensitive data. Our goal is to train a large neural network language model (NNLM) on compute-constrained devices while preserving privacy using FL and DP. However, the DP-noise introduced to the model increases as the model size grows, which often prevents convergence. We propose Partial Embedding Updates (PEU), a novel technique to decrease noise by decreasing payload size. Furthermore, we adopt Low Rank Adaptation (LoRA) and Noise Contrastive Estimation (NCE) to reduce the memory demands of large models on compute-constrained devices. This combination of techniques makes it possible to train large-vocabulary language models while preserving accuracy and privacy.
Voice trigger detection from LVCSR hypothesis lattices using bidirectional lattice recurrent neural networks
Feb 29, 2020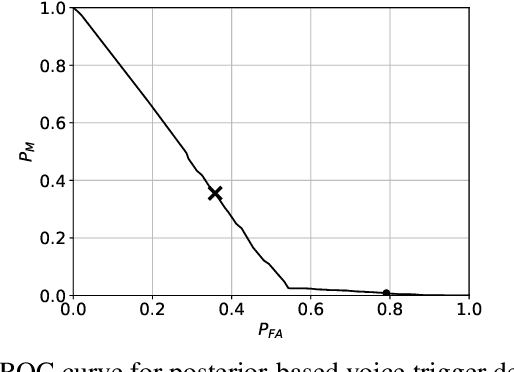
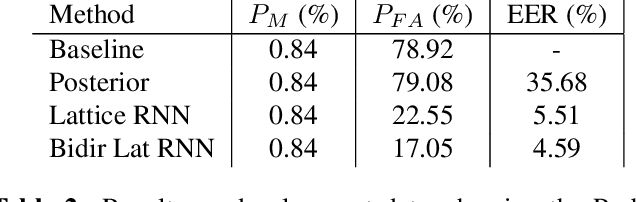
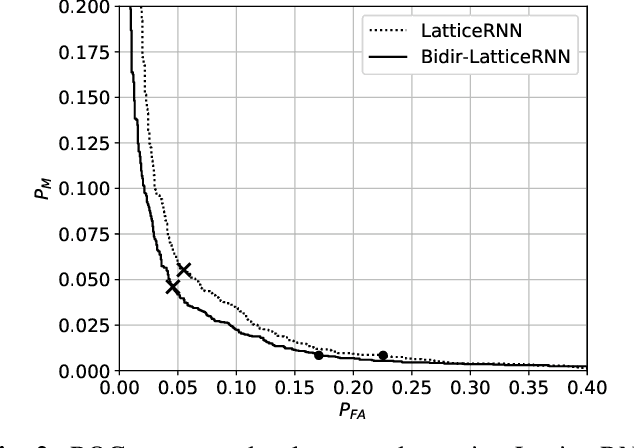

We propose a method to reduce false voice triggers of a speech-enabled personal assistant by post-processing the hypothesis lattice of a server-side large-vocabulary continuous speech recognizer (LVCSR) via a neural network. We first discuss how an estimate of the posterior probability of the trigger phrase can be obtained from the hypothesis lattice using known techniques to perform detection, then investigate a statistical model that processes the lattice in a more explicitly data-driven, discriminative manner. We propose using a Bidirectional Lattice Recurrent Neural Network (LatticeRNN) for the task, and show that it can significantly improve detection accuracy over using the 1-best result or the posterior.
* Presented at IEEE ICASSP, May 2019
SNDCNN: Self-normalizing deep CNNs with scaled exponential linear units for speech recognition
Oct 09, 2019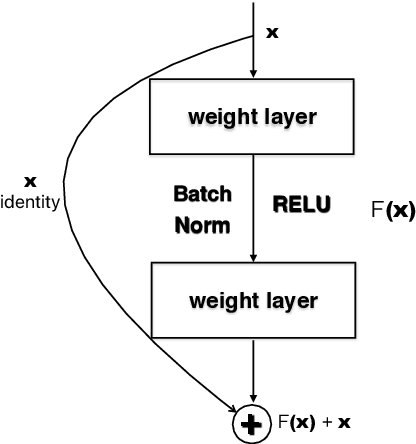

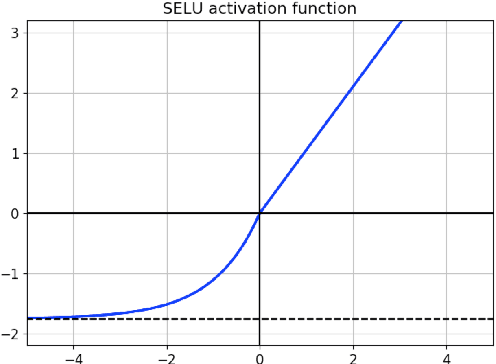

Very deep CNNs achieve state-of-the-art results in both computer vision and speech recognition, but are difficult to train. The most popular way to train very deep CNNs is to use shortcut connections (SC) together with batch normalization (BN). Inspired by Self-Normalizing Neural Networks, we propose the self-normalizing deep CNN (SNDCNN) based acoustic model topology, by removing the SC/BN and replacing the typical RELU activations with scaled exponential linear unit (SELU) in ResNet-50. SELU activations make the network self-normalizing and remove the need for both shortcut connections and batch normalization. Compared to ResNet-50, we can achieve the same or lower word error rate (WER) while at the same time improving both training and inference speed by 60%-80%. We also explore other model inference optimizations to further reduce latency for production use.