 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Theoretical Framework for Acoustic Neighbor Embeddings
Dec 03, 2024This paper provides a theoretical framework for interpreting acoustic neighbor embeddings, which are representations of the phonetic content of variable-width audio or text in a fixed-dimensional embedding space. A probabilistic interpretation of the distances between embeddings is proposed, based on a general quantitative definition of phonetic similarity between words. This provides us a framework for understanding and applying the embeddings in a principled manner. Theoretical and empirical evidence to support an approximation of uniform cluster-wise isotropy are shown, which allows us to reduce the distances to simple Euclidean distances. Four experiments that validate the framework and demonstrate how it can be applied to diverse problems are described. Nearest-neighbor search between audio and text embeddings can give isolated word classification accuracy that is identical to that of finite state transducers (FSTs) for vocabularies as large as 500k. Embedding distances give accuracy with 0.5% point difference compared to phone edit distances in out-of-vocabulary word recovery, as well as producing clustering hierarchies identical to those derived from human listening experiments in English dialect clustering. The theoretical framework also allows us to use the embeddings to predict the expected confusion of device wake-up words. All source code and pretrained models are provided.
Timestamped Embedding-Matching Acoustic-to-Word CTC ASR
Jun 20, 2023In this work, we describe a novel method of training an embedding-matching word-level connectionist temporal classification (CTC) automatic speech recognizer (ASR) such that it directly produces word start times and durations, required by many real-world applications, in addition to the transcription. The word timestamps enable the ASR to output word segmentations and word confusion networks without relying on a secondary model or forced alignment process when testing. Our proposed system has similar word segmentation accuracy as a hybrid DNN-HMM (Deep Neural Network-Hidden Markov Model) system, with less than 3ms difference in mean absolute error in word start times on TIMIT data. At the same time, we observed less than 5% relative increase in the word error rate compared to the non-timestamped system when using the same audio training data and nearly identical model size. We also contribute more rigorous analysis of multiple-hypothesis embedding-matching ASR in general.
Improvements to Embedding-Matching Acoustic-to-Word ASR Using Multiple-Hypothesis Pronunciation-Based Embeddings
Oct 30, 2022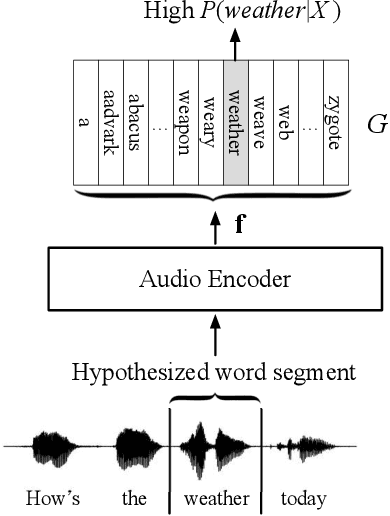
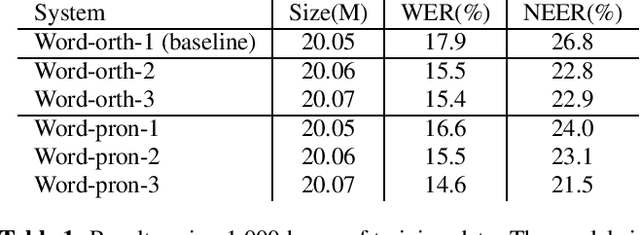
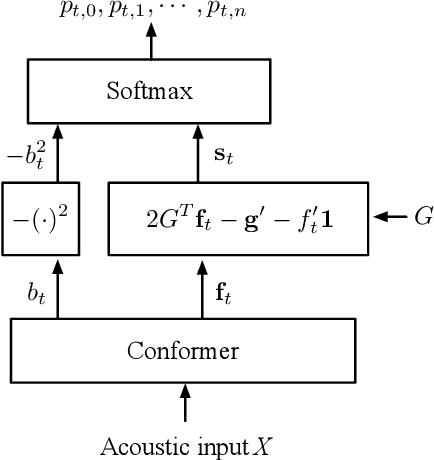

In embedding-matching acoustic-to-word (A2W) ASR, every word in the vocabulary is represented by a fixed-dimension embedding vector that can be added or removed independently of the rest of the system. The approach is potentially an elegant solution for the dynamic out-of-vocabulary (OOV) words problem, where speaker- and context-dependent named entities like contact names must be incorporated into the ASR on-the-fly for every speech utterance at testing time. Challenges still remain, however, in improving the overall accuracy of embedding-matching A2W. In this paper, we contribute two methods that improve the accuracy of embedding-matching A2W. First, we propose internally producing multiple embeddings, instead of a single embedding, at each instance in time, which allows the A2W model to propose a richer set of hypotheses over multiple time segments in the audio. Second, we propose using word pronunciation embeddings rather than word orthography embeddings to reduce ambiguities introduced by words that have more than one sound. We show that the above ideas give significant accuracy improvement, with the same training data and nearly identical model size, in scenarios where dynamic OOV words play a crucial role. On a dataset of various queries to a speech-based digital assistant that include many user-dependent contact names, we observe up to 18% decrease in word error rate using the proposed improvements.
Acoustic Neighbor Embeddings
Aug 06, 2020
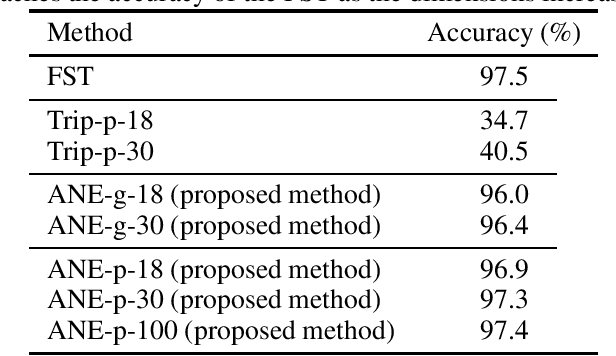
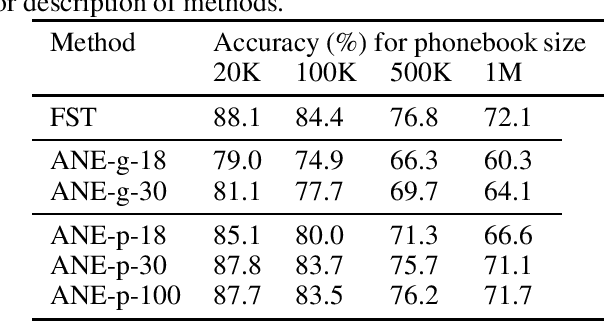

This paper proposes a novel acoustic word embedding called Acoustic Neighbor Embeddings where speech or text of arbitrary length are mapped to a vector space of fixed, reduced dimensions by adapting stochastic neighbor embedding (SNE) to sequential inputs. The Euclidean distance between coordinates in the embedding space reflects the phonetic confusability between their corresponding sequences. Two encoder neural networks are trained: an acoustic encoder that accepts speech signals in the form of frame-wise subword posterior probabilities obtained from an acoustic model and a text encoder that accepts text in the form of subword transcriptions. Compared to a known method based on a triplet loss, the proposed method is shown to have more effective gradients for neural network training. Experimentally, it also gives more accurate results when the two encoder networks are used in tandem in a word (name) recognition task, and when the text encoder network is used standalone in an approximate phonetic match task. In particular, in a name recognition task depending solely on the Euclidean distance between embedding vectors, the proposed embeddings can achieve recognition accuracy that closely approaches that of conventional finite state transducer(FST)-based decoding. For test data with 1K vocabularies, the accuracy difference is 0.6% points using only 18-dimensional embeddings, and for test data with a 1M vocabulary, the difference is 0.4% points using 100-dimensional embeddings.
Voice trigger detection from LVCSR hypothesis lattices using bidirectional lattice recurrent neural networks
Feb 29, 2020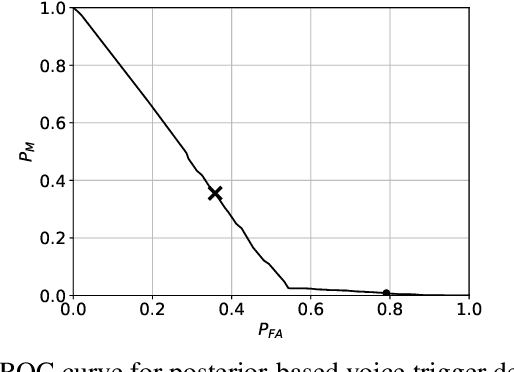
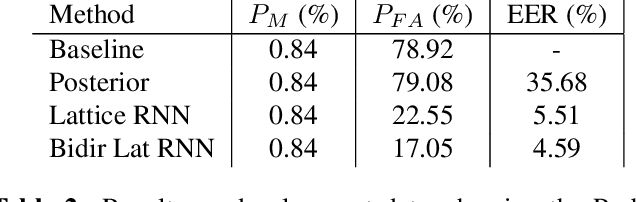
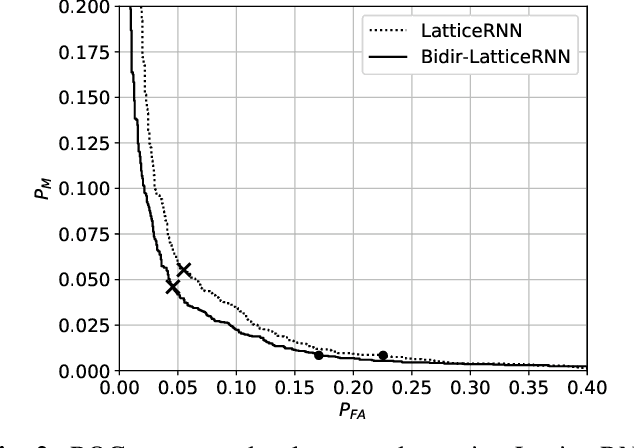

We propose a method to reduce false voice triggers of a speech-enabled personal assistant by post-processing the hypothesis lattice of a server-side large-vocabulary continuous speech recognizer (LVCSR) via a neural network. We first discuss how an estimate of the posterior probability of the trigger phrase can be obtained from the hypothesis lattice using known techniques to perform detection, then investigate a statistical model that processes the lattice in a more explicitly data-driven, discriminative manner. We propose using a Bidirectional Lattice Recurrent Neural Network (LatticeRNN) for the task, and show that it can significantly improve detection accuracy over using the 1-best result or the posterior.
* Presented at IEEE ICASSP, May 2019
On Modeling ASR Word Confidence
Jul 22, 2019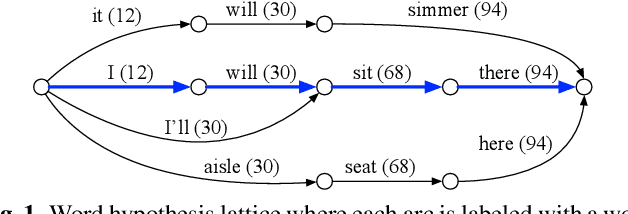
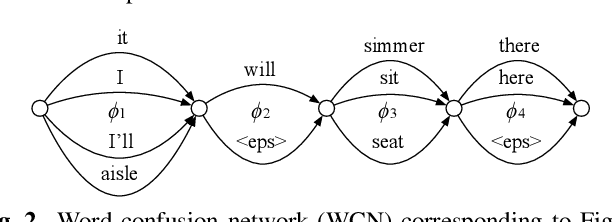
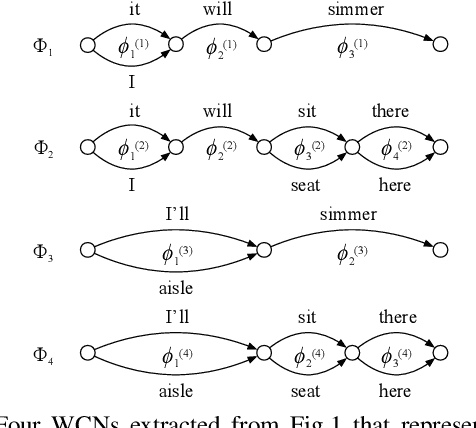
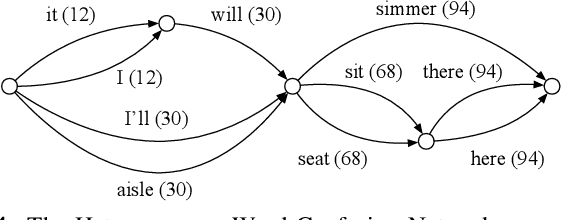
We present a new method for computing ASR word confidences that effectively mitigates ASR errors for diverse downstream applications, improves the word error rate of the 1-best result, and allows better comparison of scores across different models. We propose 1) a new method for modeling word confidence using a Heterogeneous Word Confusion Network (HWCN) that addresses some key flaws in conventional Word Confusion Networks, and 2) a new score calibration method for facilitating direct comparison of scores from different models. Using a bidirectional lattice recurrent neural network to compute the confidence scores of each word in the HWCN, we show that the word sequence with the best overall confidence is more accurate than the default 1-best result of the recognizer, and that the calibration method greatly improves the reliability of recognizer combination.