 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAcoustic Neighbor Embeddings
Paper and Code
Aug 06, 2020
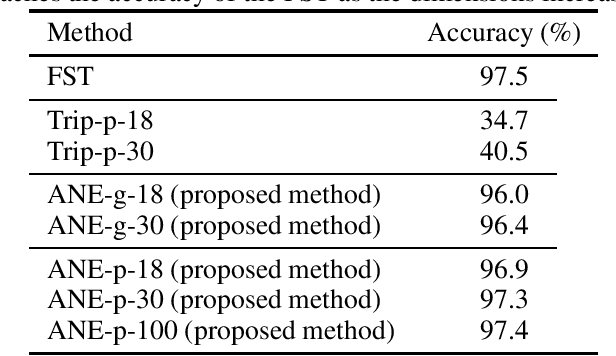
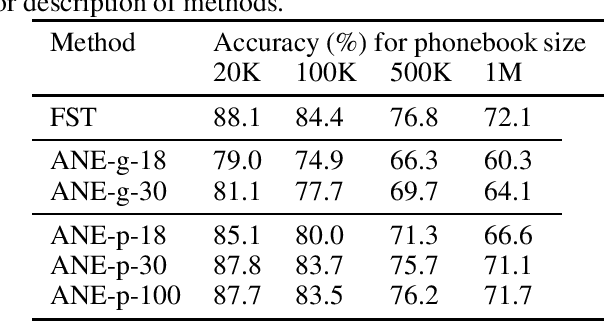

This paper proposes a novel acoustic word embedding called Acoustic Neighbor Embeddings where speech or text of arbitrary length are mapped to a vector space of fixed, reduced dimensions by adapting stochastic neighbor embedding (SNE) to sequential inputs. The Euclidean distance between coordinates in the embedding space reflects the phonetic confusability between their corresponding sequences. Two encoder neural networks are trained: an acoustic encoder that accepts speech signals in the form of frame-wise subword posterior probabilities obtained from an acoustic model and a text encoder that accepts text in the form of subword transcriptions. Compared to a known method based on a triplet loss, the proposed method is shown to have more effective gradients for neural network training. Experimentally, it also gives more accurate results when the two encoder networks are used in tandem in a word (name) recognition task, and when the text encoder network is used standalone in an approximate phonetic match task. In particular, in a name recognition task depending solely on the Euclidean distance between embedding vectors, the proposed embeddings can achieve recognition accuracy that closely approaches that of conventional finite state transducer(FST)-based decoding. For test data with 1K vocabularies, the accuracy difference is 0.6% points using only 18-dimensional embeddings, and for test data with a 1M vocabulary, the difference is 0.4% points using 100-dimensional embeddings.