 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConformer-Based Speech Recognition On Extreme Edge-Computing Devices
Dec 16, 2023


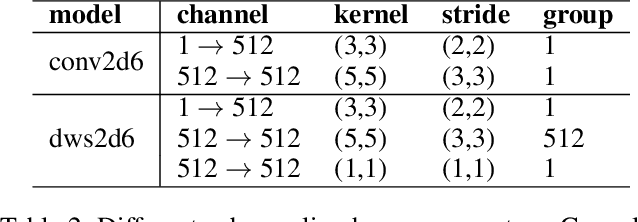
With increasingly more powerful compute capabilities and resources in today's devices, traditionally compute-intensive automatic speech recognition (ASR) has been moving from the cloud to devices to better protect user privacy. However, it is still challenging to implement on-device ASR on resource-constrained devices, such as smartphones, smart wearables, and other small home automation devices. In this paper, we propose a series of model architecture adaptions, neural network graph transformations, and numerical optimizations to fit an advanced Conformer based end-to-end streaming ASR system on resource-constrained devices without accuracy degradation. We achieve over 5.26 times faster than realtime (0.19 RTF) speech recognition on small wearables while minimizing energy consumption and achieving state-of-the-art accuracy. The proposed methods are widely applicable to other transformer-based server-free AI applications. In addition, we provide a complete theory on optimal pre-normalizers that numerically stabilize layer normalization in any Lp-norm using any floating point precision.
On Modeling ASR Word Confidence
Jul 22, 2019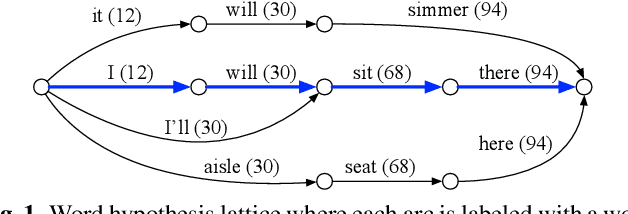
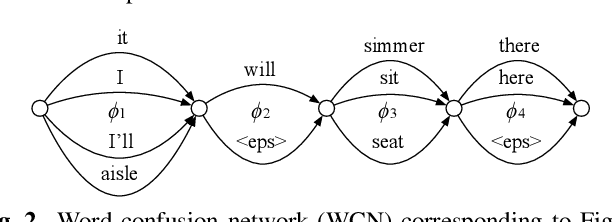
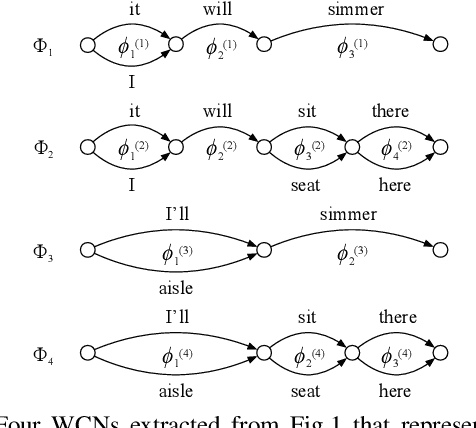
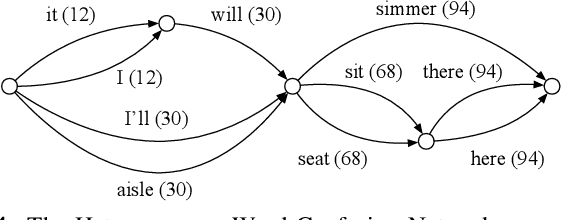
We present a new method for computing ASR word confidences that effectively mitigates ASR errors for diverse downstream applications, improves the word error rate of the 1-best result, and allows better comparison of scores across different models. We propose 1) a new method for modeling word confidence using a Heterogeneous Word Confusion Network (HWCN) that addresses some key flaws in conventional Word Confusion Networks, and 2) a new score calibration method for facilitating direct comparison of scores from different models. Using a bidirectional lattice recurrent neural network to compute the confidence scores of each word in the HWCN, we show that the word sequence with the best overall confidence is more accurate than the default 1-best result of the recognizer, and that the calibration method greatly improves the reliability of recognizer combination.