 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZS-TreeSeg: A Zero-Shot Framework for Tree Crown Instance Segmentation
Jan 31, 2026Individual tree crown segmentation is an important task in remote sensing for forest biomass estimation and ecological monitoring. However, accurate delineation in dense, overlapping canopies remains a bottleneck. While supervised deep learning methods suffer from high annotation costs and limited generalization, emerging foundation models (e.g., Segment Anything Model) often lack domain knowledge, leading to under-segmentation in dense clusters. To bridge this gap, we propose ZS-TreeSeg, a Zero-Shot framework that adapts from two mature tasks: 1) Canopy Semantic segmentation; and 2) Cells instance segmentation. By modeling tree crowns as star-convex objects within a topological flow field using Cellpose-SAM, the ZS-TreeSeg framework forces the mathematical separation of touching tree crown instances based on vector convergence. Experiments on the NEON and BAMFOREST datasets and visual inspection demonstrate that our framework generalizes robustly across diverse sensor types and canopy densities, which can offer a training-free solution for tree crown instance segmentation and labels generation.
Parallel Simulation of Contact and Actuation for Soft Growing Robots
Sep 18, 2025Soft growing robots, commonly referred to as vine robots, have demonstrated remarkable ability to interact safely and robustly with unstructured and dynamic environments. It is therefore natural to exploit contact with the environment for planning and design optimization tasks. Previous research has focused on planning under contact for passively deforming robots with pre-formed bends. However, adding active steering to these soft growing robots is necessary for successful navigation in more complex environments. To this end, we develop a unified modeling framework that integrates vine robot growth, bending, actuation, and obstacle contact. We extend the beam moment model to include the effects of actuation on kinematics under growth and then use these models to develop a fast parallel simulation framework. We validate our model and simulator with real robot experiments. To showcase the capabilities of our framework, we apply our model in a design optimization task to find designs for vine robots navigating through cluttered environments, identifying designs that minimize the number of required actuators by exploiting environmental contacts. We show the robustness of the designs to environmental and manufacturing uncertainties. Finally, we fabricate an optimized design and successfully deploy it in an obstacle-rich environment.
APT*: Asymptotically Optimal Motion Planning via Adaptively Prolated Elliptical R-Nearest Neighbors
Aug 27, 2025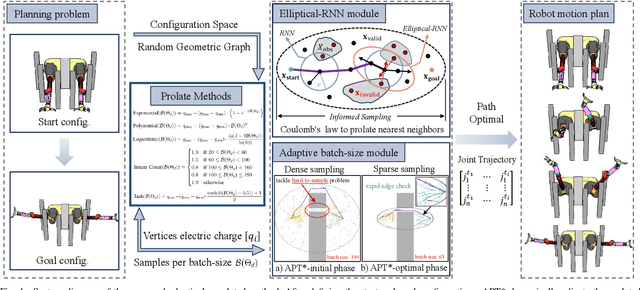
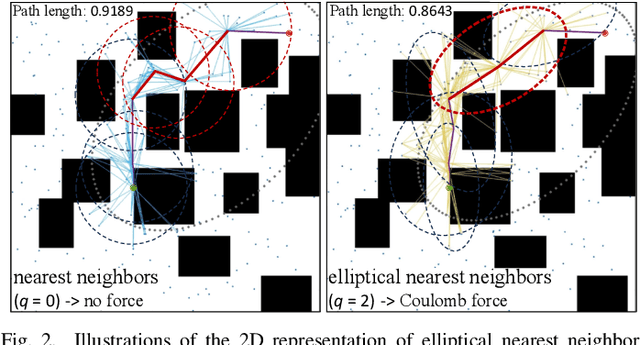
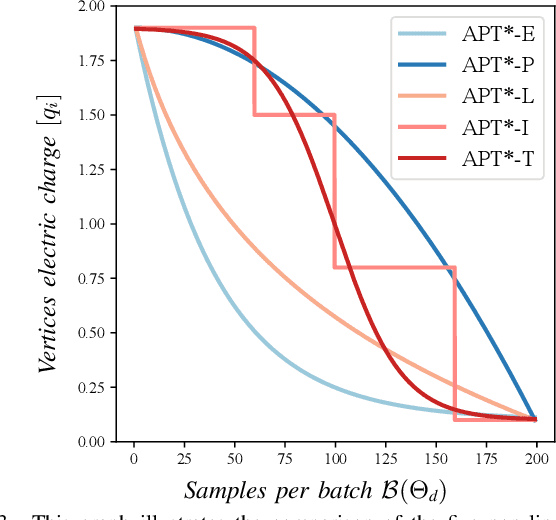
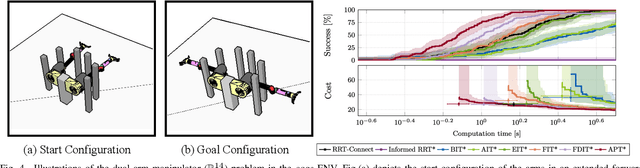
Optimal path planning aims to determine a sequence of states from a start to a goal while accounting for planning objectives. Popular methods often integrate fixed batch sizes and neglect information on obstacles, which is not problem-specific. This study introduces Adaptively Prolated Trees (APT*), a novel sampling-based motion planner that extends based on Force Direction Informed Trees (FDIT*), integrating adaptive batch-sizing and elliptical $r$-nearest neighbor modules to dynamically modulate the path searching process based on environmental feedback. APT* adjusts batch sizes based on the hypervolume of the informed sets and considers vertices as electric charges that obey Coulomb's law to define virtual forces via neighbor samples, thereby refining the prolate nearest neighbor selection. These modules employ non-linear prolate methods to adaptively adjust the electric charges of vertices for force definition, thereby improving the convergence rate with lower solution costs. Comparative analyses show that APT* outperforms existing single-query sampling-based planners in dimensions from $\mathbb{R}^4$ to $\mathbb{R}^{16}$, and it was further validated through a real-world robot manipulation task. A video showcasing our experimental results is available at: https://youtu.be/gCcUr8LiEw4
A GAN-Enhanced Deep Learning Framework for Rooftop Detection from Historical Aerial Imagery
Mar 29, 2025Accurate rooftop detection from historical aerial imagery is vital for examining long-term urban development and human settlement patterns. However, black-and-white analog photographs pose significant challenges for modern object detection frameworks due to their limited spatial resolution, lack of color information, and archival degradation. To address these limitations, this study introduces a two-stage image enhancement pipeline based on Generative Adversarial Networks (GANs): image colorization using DeOldify, followed by super-resolution enhancement with Real-ESRGAN. The enhanced images were then used to train and evaluate rooftop detection models, including Faster R-CNN, DETReg, and YOLOv11n. Results show that combining colorization with super-resolution substantially improves detection performance, with YOLOv11n achieving a mean Average Precision (mAP) exceeding 85%. This reflects an improvement of approximately 40% over original black-and-white images and 20% over images enhanced through colorization alone. The proposed method effectively bridges the gap between archival imagery and contemporary deep learning techniques, enabling more reliable extraction of building footprints from historical aerial photographs.
RoboBERT: An End-to-end Multimodal Robotic Manipulation Model
Feb 11, 2025Embodied intelligence integrates multiple modalities, enabling agents to understand images, language, and actions simultaneously. However, existing models always depend on additional datasets or extensive pre-training to maximize performance improvements, consuming abundant training time and expensive hardware cost. To tackle this issue, we present RoboBERT, a novel end-to-end robotic manipulation model integrated with a unique training strategy. This model utilizes a CNN-based diffusion policy, enhancing and stabilizing the effectiveness of this model by separating training processes for different modalities. It also underscores the importance of data augmentation, verifying various techniques to significantly boost performance. Unlike models that depend on extra data or large foundation models, RoboBERT achieves a highly competitive success rate while using only language-labeled expert demonstrations and maintaining a relatively smaller model size. Specifically, RoboBERT achieves an average length of 4.52 on the CALVIN benchmark for \(ABCD \rightarrow D\) task, setting a new state-of-the-art (SOTA) record. Furthermore, when tested on a real robot, the model demonstrates superior performance, achieving a higher success rate than other methods trained with the same data. We propose that these concepts and methodologies of RoboBERT demonstrate extensive versatility and compatibility, contributing significantly to the development of lightweight multimodal robotic models. The code can be accessed on https://github.com/PeterWangsicheng/RoboBERT
Physics-Grounded Differentiable Simulation for Soft Growing Robots
Jan 29, 2025



Soft-growing robots (i.e., vine robots) are a promising class of soft robots that allow for navigation and growth in tightly confined environments. However, these robots remain challenging to model and control due to the complex interplay of the inflated structure and inextensible materials, which leads to obstacles for autonomous operation and design optimization. Although there exist simulators for these systems that have achieved qualitative and quantitative success in matching high-level behavior, they still often fail to capture realistic vine robot shapes using simplified parameter models and have difficulties in high-throughput simulation necessary for planning and parameter optimization. We propose a differentiable simulator for these systems, enabling the use of the simulator "in-the-loop" of gradient-based optimization approaches to address the issues listed above. With the more complex parameter fitting made possible by this approach, we experimentally validate and integrate a closed-form nonlinear stiffness model for thin-walled inflated tubes based on a first-principles approach to local material wrinkling. Our simulator also takes advantage of data-parallel operations by leveraging existing differentiable computation frameworks, allowing multiple simultaneous rollouts. We demonstrate the feasibility of using a physics-grounded nonlinear stiffness model within our simulator, and how it can be an effective tool in sim-to-real transfer. We provide our implementation open source.
Anisotropic Stiffness and Programmable Actuation for Soft Robots Enabled by an Inflated Rotational Joint
Oct 16, 2024



Soft robots are known for their ability to perform tasks with great adaptability, enabled by their distributed, non-uniform stiffness and actuation. Bending is the most fundamental motion for soft robot design, but creating robust, and easy-to-fabricate soft bending joint with tunable properties remains an active problem of research. In this work, we demonstrate an inflatable actuation module for soft robots with a defined bending plane enabled by forced partial wrinkling. This lowers the structural stiffness in the bending direction, with the final stiffness easily designed by the ratio of wrinkled and unwrinkled regions. We present models and experimental characterization showing the stiffness properties of the actuation module, as well as its ability to maintain the kinematic constraint over a large range of loading conditions. We demonstrate the potential for complex actuation in a soft continuum robot and for decoupling actuation force and efficiency from load capacity. The module provides a novel method for embedding intelligent actuation into soft pneumatic robots.
How Does Diverse Interpretability of Textual Prompts Impact Medical Vision-Language Zero-Shot Tasks?
Aug 31, 2024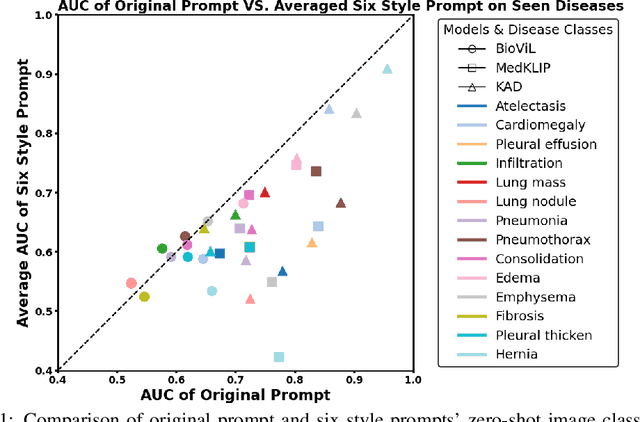
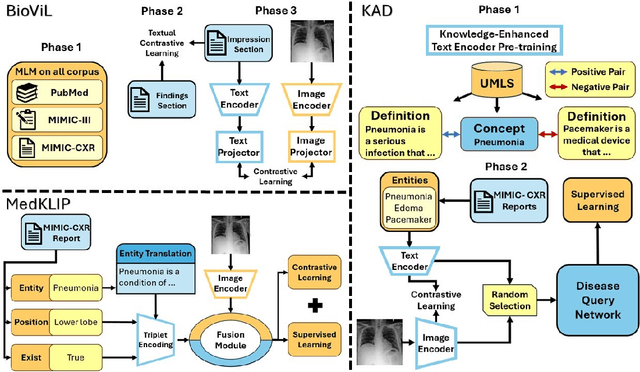
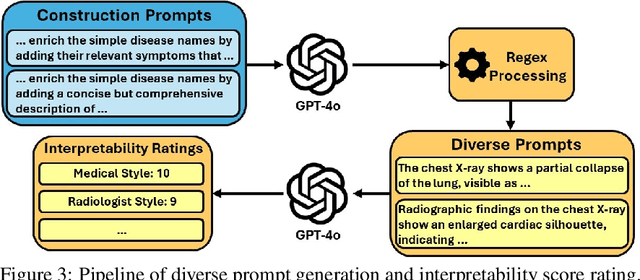
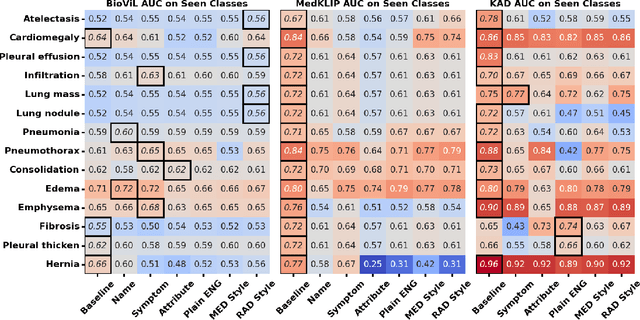
Recent advancements in medical vision-language pre-training (MedVLP) have significantly enhanced zero-shot medical vision tasks such as image classification by leveraging large-scale medical image-text pair pre-training. However, the performance of these tasks can be heavily influenced by the variability in textual prompts describing the categories, necessitating robustness in MedVLP models to diverse prompt styles. Yet, this sensitivity remains underexplored. In this work, we are the first to systematically assess the sensitivity of three widely-used MedVLP methods to a variety of prompts across 15 different diseases. To achieve this, we designed six unique prompt styles to mirror real clinical scenarios, which were subsequently ranked by interpretability. Our findings indicate that all MedVLP models evaluated show unstable performance across different prompt styles, suggesting a lack of robustness. Additionally, the models' performance varied with increasing prompt interpretability, revealing difficulties in comprehending complex medical concepts. This study underscores the need for further development in MedVLP methodologies to enhance their robustness to diverse zero-shot prompts.
Conformer-Based Speech Recognition On Extreme Edge-Computing Devices
Dec 16, 2023


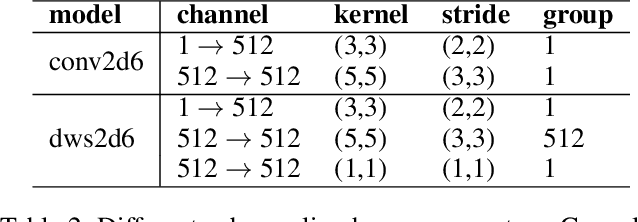
With increasingly more powerful compute capabilities and resources in today's devices, traditionally compute-intensive automatic speech recognition (ASR) has been moving from the cloud to devices to better protect user privacy. However, it is still challenging to implement on-device ASR on resource-constrained devices, such as smartphones, smart wearables, and other small home automation devices. In this paper, we propose a series of model architecture adaptions, neural network graph transformations, and numerical optimizations to fit an advanced Conformer based end-to-end streaming ASR system on resource-constrained devices without accuracy degradation. We achieve over 5.26 times faster than realtime (0.19 RTF) speech recognition on small wearables while minimizing energy consumption and achieving state-of-the-art accuracy. The proposed methods are widely applicable to other transformer-based server-free AI applications. In addition, we provide a complete theory on optimal pre-normalizers that numerically stabilize layer normalization in any Lp-norm using any floating point precision.
CT-MVSNet: Efficient Multi-View Stereo with Cross-scale Transformer
Dec 14, 2023



Recent deep multi-view stereo (MVS) methods have widely incorporated transformers into cascade network for high-resolution depth estimation, achieving impressive results. However, existing transformer-based methods are constrained by their computational costs, preventing their extension to finer stages. In this paper, we propose a novel cross-scale transformer (CT) that processes feature representations at different stages without additional computation. Specifically, we introduce an adaptive matching-aware transformer (AMT) that employs different interactive attention combinations at multiple scales. This combined strategy enables our network to capture intra-image context information and enhance inter-image feature relationships. Besides, we present a dual-feature guided aggregation (DFGA) that embeds the coarse global semantic information into the finer cost volume construction to further strengthen global and local feature awareness. Meanwhile, we design a feature metric loss (FM Loss) that evaluates the feature bias before and after transformation to reduce the impact of feature mismatch on depth estimation. Extensive experiments on DTU dataset and Tanks and Temples (T\&T) benchmark demonstrate that our method achieves state-of-the-art results. Code is available at https://github.com/wscstrive/CT-MVSNet.