 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Does Diverse Interpretability of Textual Prompts Impact Medical Vision-Language Zero-Shot Tasks?
Paper and Code
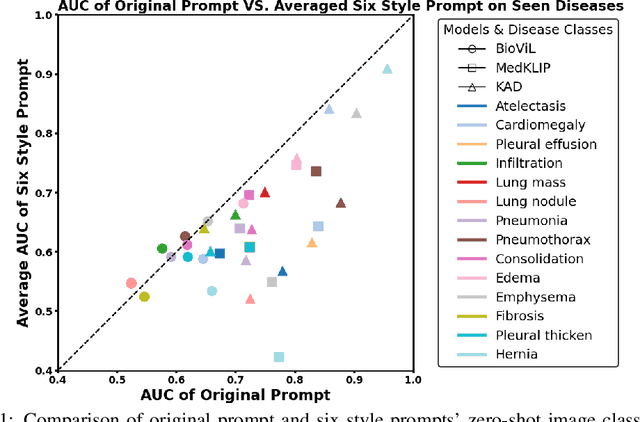
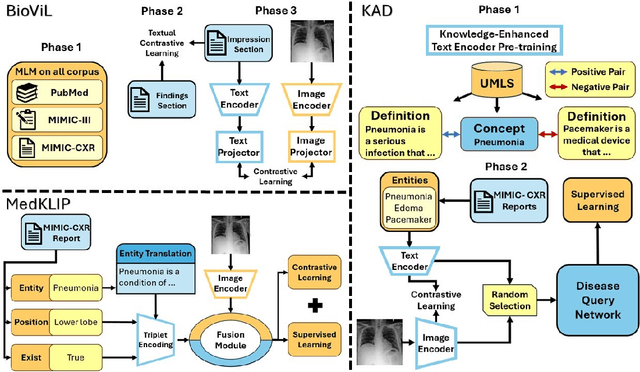
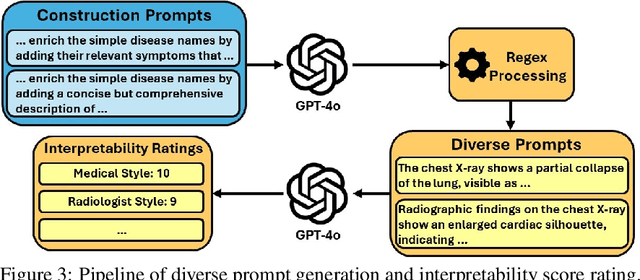
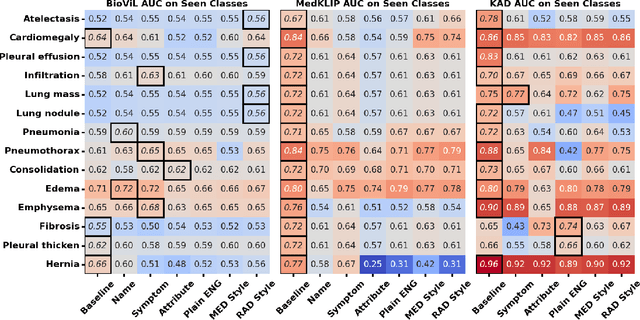
Recent advancements in medical vision-language pre-training (MedVLP) have significantly enhanced zero-shot medical vision tasks such as image classification by leveraging large-scale medical image-text pair pre-training. However, the performance of these tasks can be heavily influenced by the variability in textual prompts describing the categories, necessitating robustness in MedVLP models to diverse prompt styles. Yet, this sensitivity remains underexplored. In this work, we are the first to systematically assess the sensitivity of three widely-used MedVLP methods to a variety of prompts across 15 different diseases. To achieve this, we designed six unique prompt styles to mirror real clinical scenarios, which were subsequently ranked by interpretability. Our findings indicate that all MedVLP models evaluated show unstable performance across different prompt styles, suggesting a lack of robustness. Additionally, the models' performance varied with increasing prompt interpretability, revealing difficulties in comprehending complex medical concepts. This study underscores the need for further development in MedVLP methodologies to enhance their robustness to diverse zero-shot prompts.