 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHEad and neCK TumOR (HECKTOR) 2025: Benchmark of Segmentation, Diagnosis, and Prognosis in Multimodal PET/CT
Jun 18, 2026Head and neck cancers (HNC) represent a significant global health burden, with accurate tumor delineation being essential for effective radiotherapy planning. The complexity of the oropharyngeal anatomy, combined with the heterogeneous appearance of tumors on imaging, makes manual segmentation time-intensive and subject to inter-observer variability. Beyond segmentation, predicting long-term clinical outcomes, such as recurrence-free survival (RFS), and determining human papillomavirus (HPV) status from noninvasive imaging, remain challenging yet clinically valuable goals. The HECKTOR 2025 challenge addresses these needs by establishing a comprehensive benchmark for automated HNC analysis using multimodal PET/CT imaging and electronic health records. Building on previous editions (2020-2022), this challenge features an expanded multi-institutional dataset comprising over 1,100 patients from 10 centers worldwide. Participants were tasked with three complementary objectives: (1) segmenting primary gross tumor volumes (GTVp) and metastatic lymph nodes (GTVn), (2) predicting recurrence-free survival, and (3) classifying HPV status. The challenge attracted 35 registered teams, with 15 final submissions evaluated on a held-out test set. Top-performing algorithms achieved a mean Dice similarity coefficient of 0.75 for segmentation, a concordance index of 0.66 for survival prediction, and a balanced accuracy of 0.56 for HPV classification. This paper presents a comprehensive analysis of the submitted methodologies, evaluates their performance across different lesion characteristics, and discusses their implications for clinical translation in automated oncology workflows and decision support systems.
Multi-Contrast MRI Motion Correction via Parameter-Informed Disentanglement and Adaptive Experts
May 29, 2026Motion artifacts in magnetic resonance imaging (MRI) degrade diagnostic reliability. Existing deep learning methods are typically contrast-specific and fail to generalize across diverse modalities and artifact severities. We propose a unified framework combining parameter-informed contrast disentanglement with severity-aware adaptive correction. ScanCLIP, pretrained on over 30,000 MRI text-image pairs, derives contrast embeddings from acquisition parameters to disentangle contrast style from anatomical content, yielding contrast-free features. A Vision Transformer then estimates motion severity and routes features through a Mixture-of-Experts network, enabling targeted artifact correction. A dual-pathway decoder reconstructs both the clean image and residual artifact map, enforcing image-space consistency. On IXI and HCP benchmarks, our method improves PSNR by 0.75 dB and SSIM by up to 0.0279 over state-of-the-art approaches, with larger gains at higher artifact severities. It further demonstrates robust zero-shot generalization on real-world clinical data acquired with unseen scanning parameters, where existing methods either fail to remove artifacts or introduce additional distortions.
CT-MVSNet: Efficient Multi-View Stereo with Cross-scale Transformer
Dec 14, 2023



Recent deep multi-view stereo (MVS) methods have widely incorporated transformers into cascade network for high-resolution depth estimation, achieving impressive results. However, existing transformer-based methods are constrained by their computational costs, preventing their extension to finer stages. In this paper, we propose a novel cross-scale transformer (CT) that processes feature representations at different stages without additional computation. Specifically, we introduce an adaptive matching-aware transformer (AMT) that employs different interactive attention combinations at multiple scales. This combined strategy enables our network to capture intra-image context information and enhance inter-image feature relationships. Besides, we present a dual-feature guided aggregation (DFGA) that embeds the coarse global semantic information into the finer cost volume construction to further strengthen global and local feature awareness. Meanwhile, we design a feature metric loss (FM Loss) that evaluates the feature bias before and after transformation to reduce the impact of feature mismatch on depth estimation. Extensive experiments on DTU dataset and Tanks and Temples (T\&T) benchmark demonstrate that our method achieves state-of-the-art results. Code is available at https://github.com/wscstrive/CT-MVSNet.
MD-IQA: Learning Multi-scale Distributed Image Quality Assessment with Semi Supervised Learning for Low Dose CT
Nov 14, 2023Image quality assessment (IQA) plays a critical role in optimizing radiation dose and developing novel medical imaging techniques in computed tomography (CT). Traditional IQA methods relying on hand-crafted features have limitations in summarizing the subjective perceptual experience of image quality. Recent deep learning-based approaches have demonstrated strong modeling capabilities and potential for medical IQA, but challenges remain regarding model generalization and perceptual accuracy. In this work, we propose a multi-scale distributions regression approach to predict quality scores by constraining the output distribution, thereby improving model generalization. Furthermore, we design a dual-branch alignment network to enhance feature extraction capabilities. Additionally, semi-supervised learning is introduced by utilizing pseudo-labels for unlabeled data to guide model training. Extensive qualitative experiments demonstrate the effectiveness of our proposed method for advancing the state-of-the-art in deep learning-based medical IQA. Code is available at: https://github.com/zunzhumu/MD-IQA.
Dual Feature Augmentation Network for Generalized Zero-shot Learning
Sep 25, 2023Zero-shot learning (ZSL) aims to infer novel classes without training samples by transferring knowledge from seen classes. Existing embedding-based approaches for ZSL typically employ attention mechanisms to locate attributes on an image. However, these methods often ignore the complex entanglement among different attributes' visual features in the embedding space. Additionally, these methods employ a direct attribute prediction scheme for classification, which does not account for the diversity of attributes in images of the same category. To address these issues, we propose a novel Dual Feature Augmentation Network (DFAN), which comprises two feature augmentation modules, one for visual features and the other for semantic features. The visual feature augmentation module explicitly learns attribute features and employs cosine distance to separate them, thus enhancing attribute representation. In the semantic feature augmentation module, we propose a bias learner to capture the offset that bridges the gap between actual and predicted attribute values from a dataset's perspective. Furthermore, we introduce two predictors to reconcile the conflicts between local and global features. Experimental results on three benchmarks demonstrate the marked advancement of our method compared to state-of-the-art approaches. Our code is available at https://github.com/Sion1/DFAN.
Whole-body tumor segmentation of 18F -FDG PET/CT using a cascaded and ensembled convolutional neural networks
Oct 14, 2022



Background: A crucial initial processing step for quantitative PET/CT analysis is the segmentation of tumor lesions enabling accurate feature ex-traction, tumor characterization, oncologic staging, and image-based therapy response assessment. Manual lesion segmentation is however associated with enormous effort and cost and is thus infeasible in clinical routine. Goal: The goal of this study was to report the performance of a deep neural network designed to automatically segment regions suspected of cancer in whole-body 18F-FDG PET/CT images in the context of the AutoPET challenge. Method: A cascaded approach was developed where a stacked ensemble of 3D UNET CNN processed the PET/CT images at a fixed 6mm resolution. A refiner network composed of residual layers enhanced the 6mm segmentation mask to the original resolution. Results: 930 cases were used to train the model. 50% were histologically proven cancer patients and 50% were healthy controls. We obtained a dice=0.68 on 84 stratified test cases. Manual and automatic Metabolic Tumor Volume (MTV) were highly correlated (R2 = 0.969,Slope = 0.947). Inference time was 89.7 seconds on average. Conclusion: The proposed algorithm accurately segmented regions suspicious for cancer in whole-body 18F -FDG PET/CT images.
Multi-Modal MRI Reconstruction Assisted with Spatial Alignment Network
Aug 30, 2021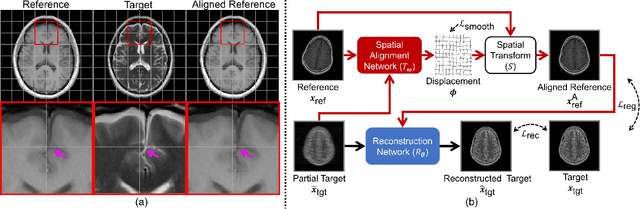
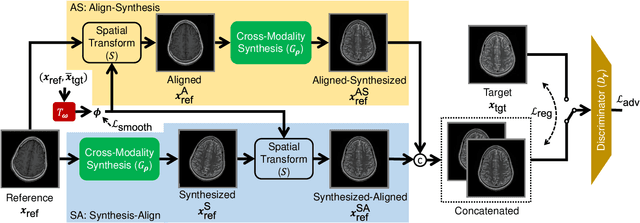

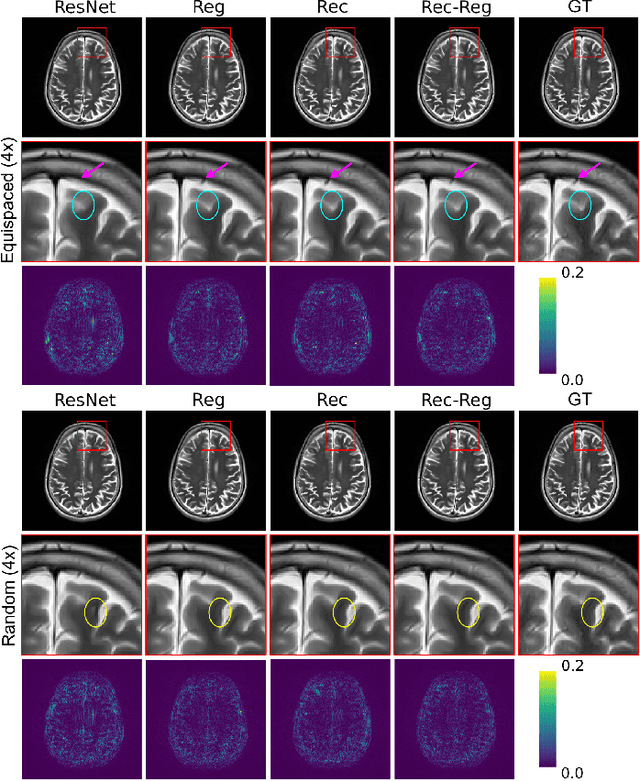
In clinical practice, magnetic resonance imaging (MRI) with multiple contrasts is usually acquired in a single study to assess different properties of the same region of interest in human body. The whole acquisition process can be accelerated by having one or more modalities under-sampled in the $k$-space. Recent researches demonstrate that, considering the redundancy between different contrasts or modalities, a target MRI modality under-sampled in the $k$-space can be more efficiently reconstructed with a fully-sampled MRI contrast as the reference modality. However, we find that the performance of the above multi-modal reconstruction can be negatively affected by subtle spatial misalignment between different contrasts, which is actually common in clinical practice. In this paper, to compensate for such spatial misalignment, we integrate the spatial alignment network with multi-modal reconstruction towards better reconstruction quality of the target modality. First, the spatial alignment network estimates the spatial misalignment between the fully-sampled reference and the under-sampled target images, and warps the reference image accordingly. Then, the aligned fully-sampled reference image joins the multi-modal reconstruction of the under-sampled target image. Also, considering the contrast difference between the target and the reference images, we particularly design the cross-modality-synthesis-based registration loss, in combination with the reconstruction loss, to jointly train the spatial alignment network and the reconstruction network. Experiments on both clinical MRI and multi-coil $k$-space raw data demonstrate the superiority and robustness of multi-modal MRI reconstruction empowered with our spatial alignment network. Our code is publicly available at \url{https://github.com/woxuankai/SpatialAlignmentNetwork}.
Multi-Scale Boosted Dehazing Network with Dense Feature Fusion
Apr 28, 2020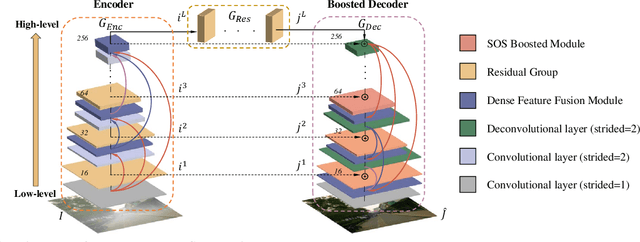

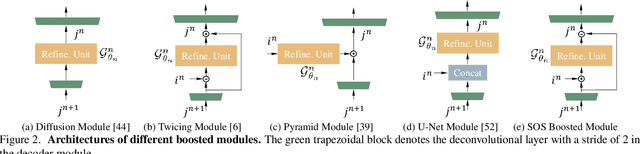
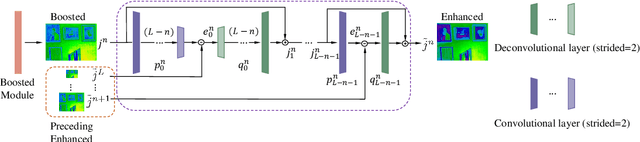
In this paper, we propose a Multi-Scale Boosted Dehazing Network with Dense Feature Fusion based on the U-Net architecture. The proposed method is designed based on two principles, boosting and error feedback, and we show that they are suitable for the dehazing problem. By incorporating the Strengthen-Operate-Subtract boosting strategy in the decoder of the proposed model, we develop a simple yet effective boosted decoder to progressively restore the haze-free image. To address the issue of preserving spatial information in the U-Net architecture, we design a dense feature fusion module using the back-projection feedback scheme. We show that the dense feature fusion module can simultaneously remedy the missing spatial information from high-resolution features and exploit the non-adjacent features. Extensive evaluations demonstrate that the proposed model performs favorably against the state-of-the-art approaches on the benchmark datasets as well as real-world hazy images.
Dual Adversarial Learning with Attention Mechanism for Fine-grained Medical Image Synthesis
Jul 07, 2019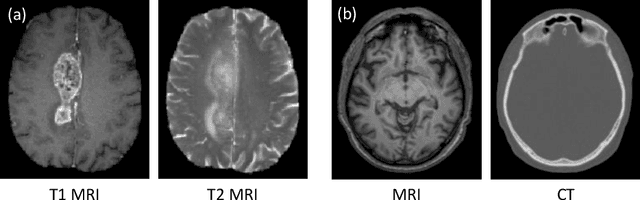
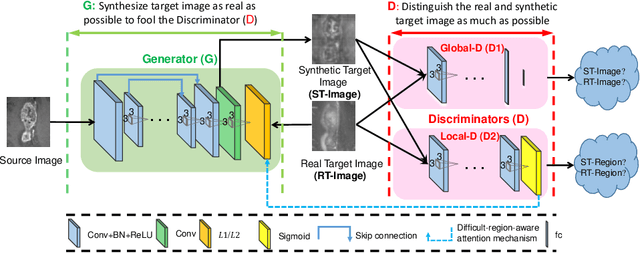

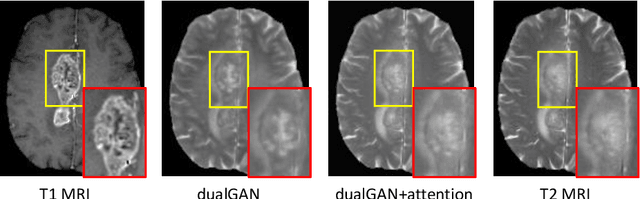
Medical imaging plays a critical role in various clinical applications. However, due to multiple considerations such as cost and risk, the acquisition of certain image modalities could be limited. To address this issue, many cross-modality medical image synthesis methods have been proposed. However, the current methods cannot well model the hard-to-synthesis regions (e.g., tumor or lesion regions). To address this issue, we propose a simple but effective strategy, that is, we propose a dual-discriminator (dual-D) adversarial learning system, in which, a global-D is used to make an overall evaluation for the synthetic image, and a local-D is proposed to densely evaluate the local regions of the synthetic image. More importantly, we build an adversarial attention mechanism which targets at better modeling hard-to-synthesize regions (e.g., tumor or lesion regions) based on the local-D. Experimental results show the robustness and accuracy of our method in synthesizing fine-grained target images from the corresponding source images. In particular, we evaluate our method on two datasets, i.e., to address the tasks of generating T2 MRI from T1 MRI for the brain tumor images and generating MRI from CT. Our method outperforms the state-of-the-art methods under comparison in all datasets and tasks. And the proposed difficult-region-aware attention mechanism is also proved to be able to help generate more realistic images, especially for the hard-to-synthesize regions.
Task Decomposition and Synchronization for Semantic Biomedical Image Segmentation
May 21, 2019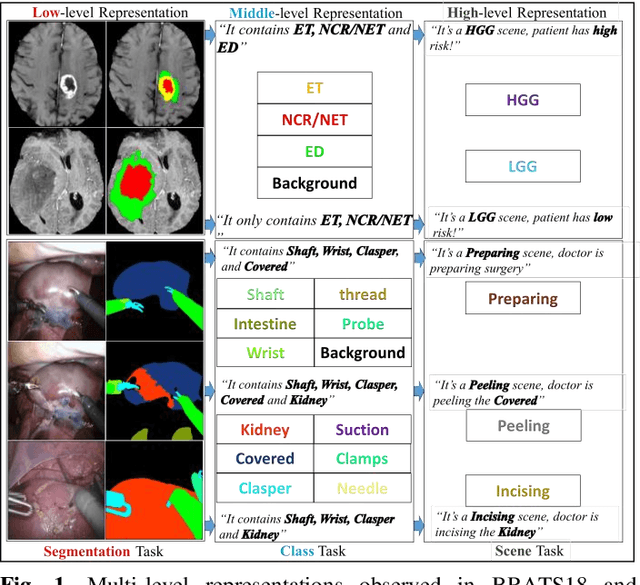

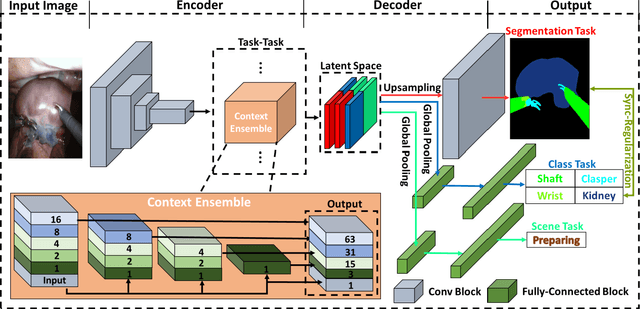
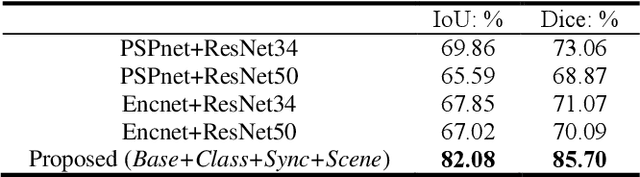
Semantic segmentation is essentially important to biomedical image analysis. Many recent works mainly focus on integrating the Fully Convolutional Network (FCN) architecture with sophisticated convolution implementation and deep supervision. In this paper, we propose to decompose the single segmentation task into three subsequent sub-tasks, including (1) pixel-wise image segmentation, (2) prediction of the class labels of the objects within the image, and (3) classification of the scene the image belonging to. While these three sub-tasks are trained to optimize their individual loss functions of different perceptual levels, we propose to let them interact by the task-task context ensemble. Moreover, we propose a novel sync-regularization to penalize the deviation between the outputs of the pixel-wise segmentation and the class prediction tasks. These effective regularizations help FCN utilize context information comprehensively and attain accurate semantic segmentation, even though the number of the images for training may be limited in many biomedical applications. We have successfully applied our framework to three diverse 2D/3D medical image datasets, including Robotic Scene Segmentation Challenge 18 (ROBOT18), Brain Tumor Segmentation Challenge 18 (BRATS18), and Retinal Fundus Glaucoma Challenge (REFUGE18). We have achieved top-tier performance in all three challenges.