 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing many-body Bell correlation depth with superconducting qubits
Jun 25, 2024


Quantum nonlocality describes a stronger form of quantum correlation than that of entanglement. It refutes Einstein's belief of local realism and is among the most distinctive and enigmatic features of quantum mechanics. It is a crucial resource for achieving quantum advantages in a variety of practical applications, ranging from cryptography and certified random number generation via self-testing to machine learning. Nevertheless, the detection of nonlocality, especially in quantum many-body systems, is notoriously challenging. Here, we report an experimental certification of genuine multipartite Bell correlations, which signal nonlocality in quantum many-body systems, up to 24 qubits with a fully programmable superconducting quantum processor. In particular, we employ energy as a Bell correlation witness and variationally decrease the energy of a many-body system across a hierarchy of thresholds, below which an increasing Bell correlation depth can be certified from experimental data. As an illustrating example, we variationally prepare the low-energy state of a two-dimensional honeycomb model with 73 qubits and certify its Bell correlations by measuring an energy that surpasses the corresponding classical bound with up to 48 standard deviations. In addition, we variationally prepare a sequence of low-energy states and certify their genuine multipartite Bell correlations up to 24 qubits via energies measured efficiently by parity oscillation and multiple quantum coherence techniques. Our results establish a viable approach for preparing and certifying multipartite Bell correlations, which provide not only a finer benchmark beyond entanglement for quantum devices, but also a valuable guide towards exploiting multipartite Bell correlation in a wide spectrum of practical applications.
An Advanced Reinforcement Learning Framework for Online Scheduling of Deferrable Workloads in Cloud Computing
Jun 03, 2024
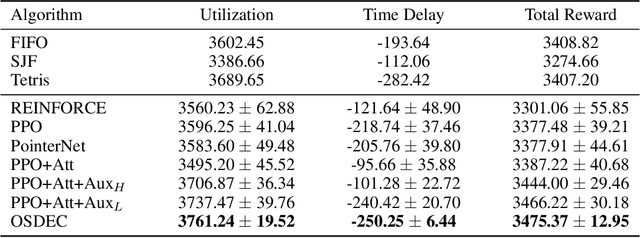
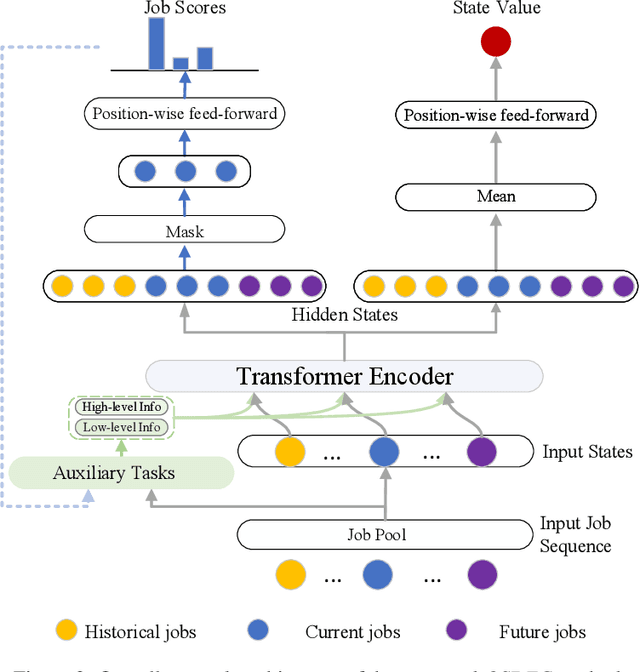
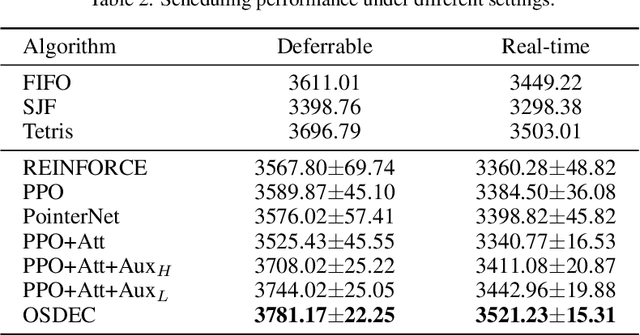
Efficient resource utilization and perfect user experience usually conflict with each other in cloud computing platforms. Great efforts have been invested in increasing resource utilization but trying not to affect users' experience for cloud computing platforms. In order to better utilize the remaining pieces of computing resources spread over the whole platform, deferrable jobs are provided with a discounted price to users. For this type of deferrable jobs, users are allowed to submit jobs that will run for a specific uninterrupted duration in a flexible range of time in the future with a great discount. With these deferrable jobs to be scheduled under the remaining capacity after deploying those on-demand jobs, it remains a challenge to achieve high resource utilization and meanwhile shorten the waiting time for users as much as possible in an online manner. In this paper, we propose an online deferrable job scheduling method called \textit{Online Scheduling for DEferrable jobs in Cloud} (\OSDEC{}), where a deep reinforcement learning model is adopted to learn the scheduling policy, and several auxiliary tasks are utilized to provide better state representations and improve the performance of the model. With the integrated reinforcement learning framework, the proposed method can well plan the deployment schedule and achieve a short waiting time for users while maintaining a high resource utilization for the platform. The proposed method is validated on a public dataset and shows superior performance.
PatchScaler: An Efficient Patch-independent Diffusion Model for Super-Resolution
May 27, 2024



Diffusion models significantly improve the quality of super-resolved images with their impressive content generation capabilities. However, the huge computational costs limit the applications of these methods.Recent efforts have explored reasonable inference acceleration to reduce the number of sampling steps, but the computational cost remains high as each step is performed on the entire image.This paper introduces PatchScaler, a patch-independent diffusion-based single image super-resolution (SR) method, designed to enhance the efficiency of the inference process.The proposed method is motivated by the observation that not all the image patches within an image need the same sampling steps for reconstructing high-resolution images.Based on this observation, we thus develop a Patch-adaptive Group Sampling (PGS) to divide feature patches into different groups according to the patch-level reconstruction difficulty and dynamically assign an appropriate sampling configuration for each group so that the inference speed can be better accelerated.In addition, to improve the denoising ability at each step of the sampling, we develop a texture prompt to guide the estimations of the diffusion model by retrieving high-quality texture priors from a patch-independent reference texture memory.Experiments show that our PatchScaler achieves favorable performance in both quantitative and qualitative evaluations with fast inference speed.Our code and model are available at \url{https://github.com/yongliuy/PatchScaler}.
Retrieving and Refining: A Hybrid Framework with Large Language Models for Rare Disease Identification
May 16, 2024The infrequency and heterogeneity of clinical presentations in rare diseases often lead to underdiagnosis and their exclusion from structured datasets. This necessitates the utilization of unstructured text data for comprehensive analysis. However, the manual identification from clinical reports is an arduous and intrinsically subjective task. This study proposes a novel hybrid approach that synergistically combines a traditional dictionary-based natural language processing (NLP) tool with the powerful capabilities of large language models (LLMs) to enhance the identification of rare diseases from unstructured clinical notes. We comprehensively evaluate various prompting strategies on six large language models (LLMs) of varying sizes and domains (general and medical). This evaluation encompasses zero-shot, few-shot, and retrieval-augmented generation (RAG) techniques to enhance the LLMs' ability to reason about and understand contextual information in patient reports. The results demonstrate effectiveness in rare disease identification, highlighting the potential for identifying underdiagnosed patients from clinical notes.
Verco: Learning Coordinated Verbal Communication for Multi-agent Reinforcement Learning
Apr 27, 2024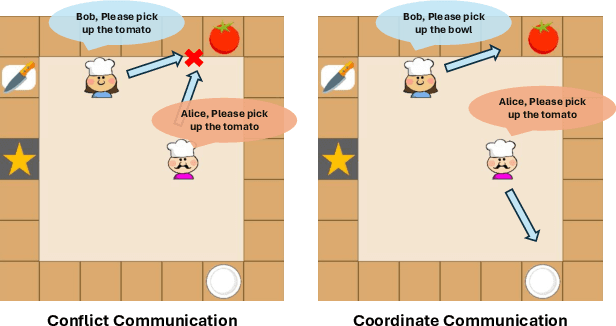
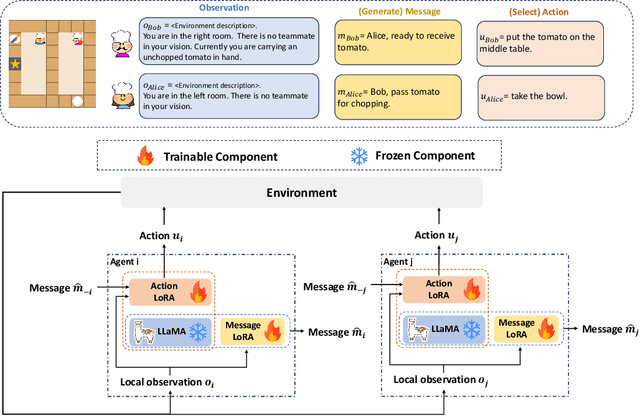
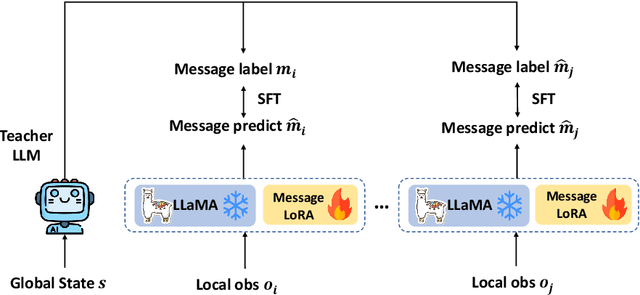
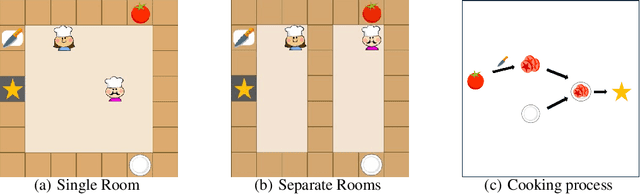
In recent years, multi-agent reinforcement learning algorithms have made significant advancements in diverse gaming environments, leading to increased interest in the broader application of such techniques. To address the prevalent challenge of partial observability, communication-based algorithms have improved cooperative performance through the sharing of numerical embedding between agents. However, the understanding of the formation of collaborative mechanisms is still very limited, making designing a human-understandable communication mechanism a valuable problem to address. In this paper, we propose a novel multi-agent reinforcement learning algorithm that embeds large language models into agents, endowing them with the ability to generate human-understandable verbal communication. The entire framework has a message module and an action module. The message module is responsible for generating and sending verbal messages to other agents, effectively enhancing information sharing among agents. To further enhance the message module, we employ a teacher model to generate message labels from the global view and update the student model through Supervised Fine-Tuning (SFT). The action module receives messages from other agents and selects actions based on current local observations and received messages. Experiments conducted on the Overcooked game demonstrate our method significantly enhances the learning efficiency and performance of existing methods, while also providing an interpretable tool for humans to understand the process of multi-agent cooperation.
A Language Model based Framework for New Concept Placement in Ontologies
Mar 04, 2024We investigate the task of inserting new concepts extracted from texts into an ontology using language models. We explore an approach with three steps: edge search which is to find a set of candidate locations to insert (i.e., subsumptions between concepts), edge formation and enrichment which leverages the ontological structure to produce and enhance the edge candidates, and edge selection which eventually locates the edge to be placed into. In all steps, we propose to leverage neural methods, where we apply embedding-based methods and contrastive learning with Pre-trained Language Models (PLMs) such as BERT for edge search, and adapt a BERT fine-tuning-based multi-label Edge-Cross-encoder, and Large Language Models (LLMs) such as GPT series, FLAN-T5, and Llama 2, for edge selection. We evaluate the methods on recent datasets created using the SNOMED CT ontology and the MedMentions entity linking benchmark. The best settings in our framework use fine-tuned PLM for search and a multi-label Cross-encoder for selection. Zero-shot prompting of LLMs is still not adequate for the task, and we propose explainable instruction tuning of LLMs for improved performance. Our study shows the advantages of PLMs and highlights the encouraging performance of LLMs that motivates future studies.
Can GPT-3.5 Generate and Code Discharge Summaries?
Jan 24, 2024



Objective: To investigate GPT-3.5 in generating and coding medical documents with ICD-10 codes for data augmentation on low-resources labels. Materials and Methods: Employing GPT-3.5 we generated and coded 9,606 discharge summaries based on lists of ICD-10 code descriptions of patients with infrequent (generation) codes within the MIMIC-IV dataset. Combined with the baseline training set, this formed an augmented training set. Neural coding models were trained on baseline and augmented data and evaluated on a MIMIC-IV test set. We report micro- and macro-F1 scores on the full codeset, generation codes, and their families. Weak Hierarchical Confusion Matrices were employed to determine within-family and outside-of-family coding errors in the latter codesets. The coding performance of GPT-3.5 was evaluated both on prompt-guided self-generated data and real MIMIC-IV data. Clinical professionals evaluated the clinical acceptability of the generated documents. Results: Augmentation slightly hinders the overall performance of the models but improves performance for the generation candidate codes and their families, including one unseen in the baseline training data. Augmented models display lower out-of-family error rates. GPT-3.5 can identify ICD-10 codes by the prompted descriptions, but performs poorly on real data. Evaluators note the correctness of generated concepts while suffering in variety, supporting information, and narrative. Discussion and Conclusion: GPT-3.5 alone is unsuitable for ICD-10 coding. Augmentation positively affects generation code families but mainly benefits codes with existing examples. Augmentation reduces out-of-family errors. Discharge summaries generated by GPT-3.5 state prompted concepts correctly but lack variety, and authenticity in narratives. They are unsuitable for clinical practice.
COIN: Chance-Constrained Imitation Learning for Uncertainty-aware Adaptive Resource Oversubscription Policy
Jan 13, 2024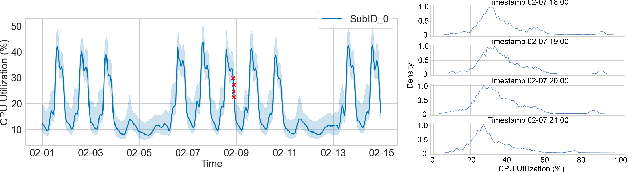
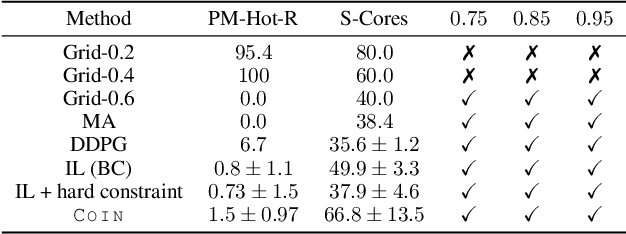
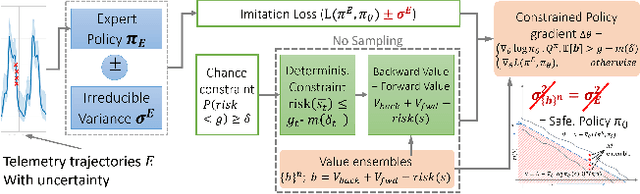
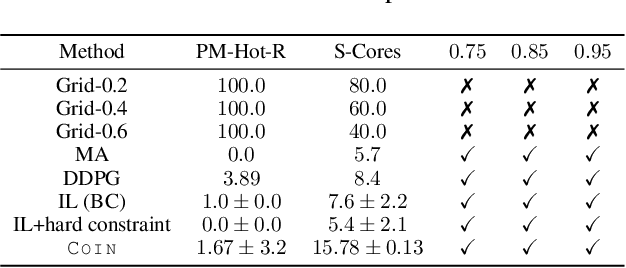
We address the challenge of learning safe and robust decision policies in presence of uncertainty in context of the real scientific problem of adaptive resource oversubscription to enhance resource efficiency while ensuring safety against resource congestion risk. Traditional supervised prediction or forecasting models are ineffective in learning adaptive policies whereas standard online optimization or reinforcement learning is difficult to deploy on real systems. Offline methods such as imitation learning (IL) are ideal since we can directly leverage historical resource usage telemetry. But, the underlying aleatoric uncertainty in such telemetry is a critical bottleneck. We solve this with our proposed novel chance-constrained imitation learning framework, which ensures implicit safety against uncertainty in a principled manner via a combination of stochastic (chance) constraints on resource congestion risk and ensemble value functions. This leads to substantial ($\approx 3-4\times$) improvement in resource efficiency and safety in many oversubscription scenarios, including resource management in cloud services.
TaskWeaver: A Code-First Agent Framework
Dec 01, 2023
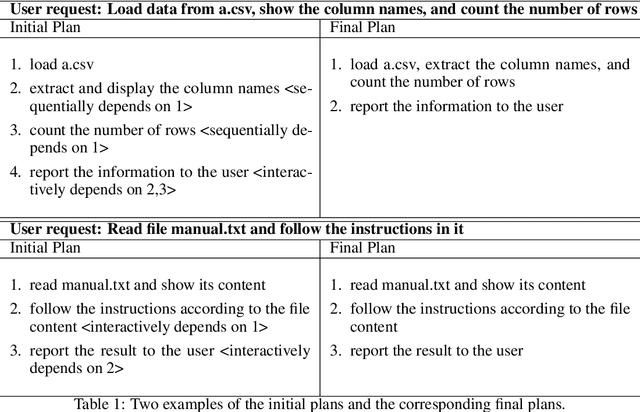
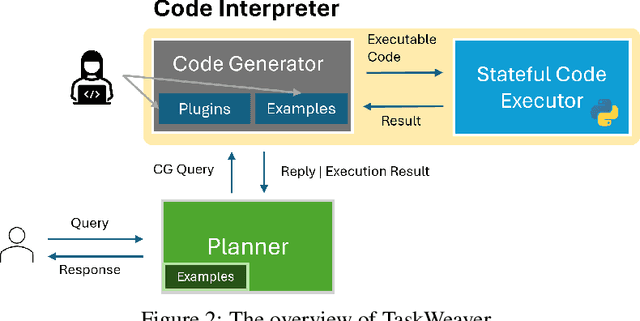
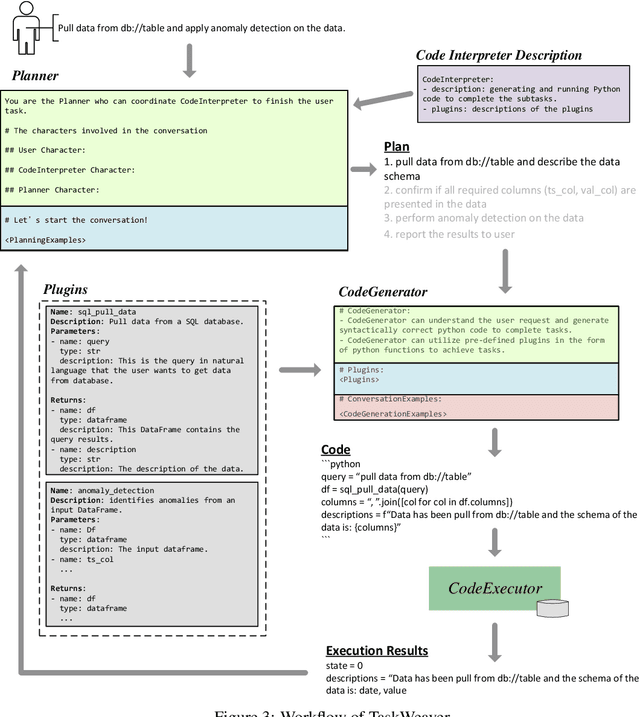
Large Language Models (LLMs) have shown impressive abilities in natural language understanding and generation, leading to their use in applications such as chatbots and virtual assistants. However, existing LLM frameworks face limitations in handling domain-specific data analytics tasks with rich data structures. Moreover, they struggle with flexibility to meet diverse user requirements. To address these issues, TaskWeaver is proposed as a code-first framework for building LLM-powered autonomous agents. It converts user requests into executable code and treats user-defined plugins as callable functions. TaskWeaver provides support for rich data structures, flexible plugin usage, and dynamic plugin selection, and leverages LLM coding capabilities for complex logic. It also incorporates domain-specific knowledge through examples and ensures the secure execution of generated code. TaskWeaver offers a powerful and flexible framework for creating intelligent conversational agents that can handle complex tasks and adapt to domain-specific scenarios. The code is open-sourced at https://github.com/microsoft/TaskWeaver/.
Counter-Empirical Attacking based on Adversarial Reinforcement Learning for Time-Relevant Scoring System
Nov 09, 2023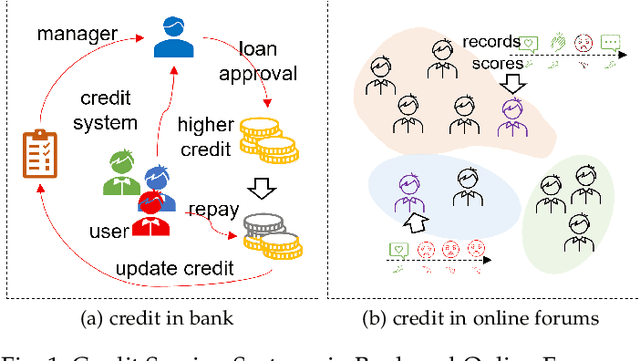
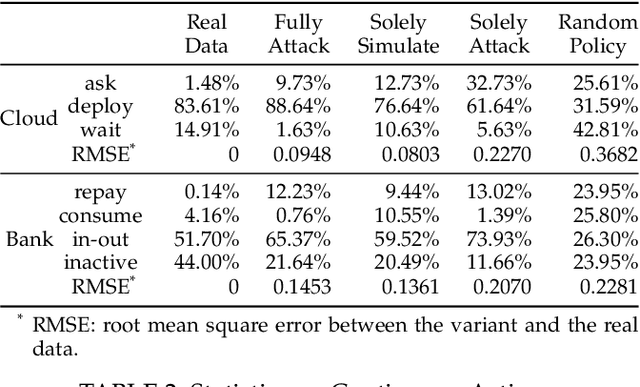
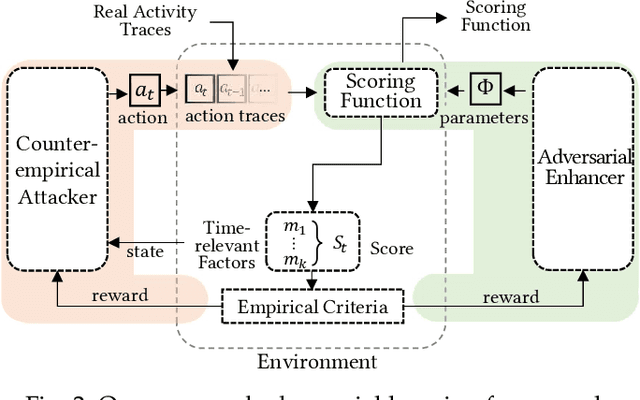

Scoring systems are commonly seen for platforms in the era of big data. From credit scoring systems in financial services to membership scores in E-commerce shopping platforms, platform managers use such systems to guide users towards the encouraged activity pattern, and manage resources more effectively and more efficiently thereby. To establish such scoring systems, several "empirical criteria" are firstly determined, followed by dedicated top-down design for each factor of the score, which usually requires enormous effort to adjust and tune the scoring function in the new application scenario. What's worse, many fresh projects usually have no ground-truth or any experience to evaluate a reasonable scoring system, making the designing even harder. To reduce the effort of manual adjustment of the scoring function in every new scoring system, we innovatively study the scoring system from the preset empirical criteria without any ground truth, and propose a novel framework to improve the system from scratch. In this paper, we propose a "counter-empirical attacking" mechanism that can generate "attacking" behavior traces and try to break the empirical rules of the scoring system. Then an adversarial "enhancer" is applied to evaluate the scoring system and find the improvement strategy. By training the adversarial learning problem, a proper scoring function can be learned to be robust to the attacking activity traces that are trying to violate the empirical criteria. Extensive experiments have been conducted on two scoring systems including a shared computing resource platform and a financial credit system. The experimental results have validated the effectiveness of our proposed framework.