 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan GPT-3.5 Generate and Code Discharge Summaries?
Jan 24, 2024



Objective: To investigate GPT-3.5 in generating and coding medical documents with ICD-10 codes for data augmentation on low-resources labels. Materials and Methods: Employing GPT-3.5 we generated and coded 9,606 discharge summaries based on lists of ICD-10 code descriptions of patients with infrequent (generation) codes within the MIMIC-IV dataset. Combined with the baseline training set, this formed an augmented training set. Neural coding models were trained on baseline and augmented data and evaluated on a MIMIC-IV test set. We report micro- and macro-F1 scores on the full codeset, generation codes, and their families. Weak Hierarchical Confusion Matrices were employed to determine within-family and outside-of-family coding errors in the latter codesets. The coding performance of GPT-3.5 was evaluated both on prompt-guided self-generated data and real MIMIC-IV data. Clinical professionals evaluated the clinical acceptability of the generated documents. Results: Augmentation slightly hinders the overall performance of the models but improves performance for the generation candidate codes and their families, including one unseen in the baseline training data. Augmented models display lower out-of-family error rates. GPT-3.5 can identify ICD-10 codes by the prompted descriptions, but performs poorly on real data. Evaluators note the correctness of generated concepts while suffering in variety, supporting information, and narrative. Discussion and Conclusion: GPT-3.5 alone is unsuitable for ICD-10 coding. Augmentation positively affects generation code families but mainly benefits codes with existing examples. Augmentation reduces out-of-family errors. Discharge summaries generated by GPT-3.5 state prompted concepts correctly but lack variety, and authenticity in narratives. They are unsuitable for clinical practice.
Automated Clinical Coding: What, Why, and Where We Are?
Mar 21, 2022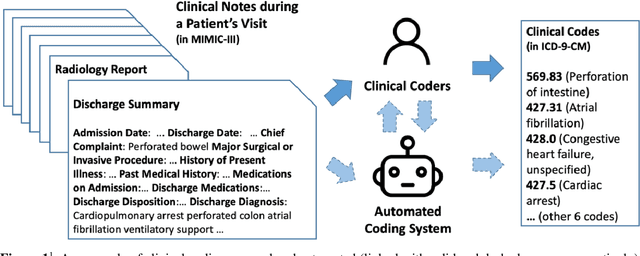
Clinical coding is the task of transforming medical information in a patient's health records into structured codes so that they can be used for statistical analysis. This is a cognitive and time-consuming task that follows a standard process in order to achieve a high level of consistency. Clinical coding could potentially be supported by an automated system to improve the efficiency and accuracy of the process. We introduce the idea of automated clinical coding and summarise its challenges from the perspective of Artificial Intelligence (AI) and Natural Language Processing (NLP), based on the literature, our project experience over the past two and half years (late 2019 - early 2022), and discussions with clinical coding experts in Scotland and the UK. Our research reveals the gaps between the current deep learning-based approach applied to clinical coding and the need for explainability and consistency in real-world practice. Knowledge-based methods that represent and reason the standard, explainable process of a task may need to be incorporated into deep learning-based methods for clinical coding. Automated clinical coding is a promising task for AI, despite the technical and organisational challenges. Coders are needed to be involved in the development process. There is much to achieve to develop and deploy an AI-based automated system to support coding in the next five years and beyond.
CoPHE: A Count-Preserving Hierarchical Evaluation Metric in Large-Scale Multi-Label Text Classification
Sep 10, 2021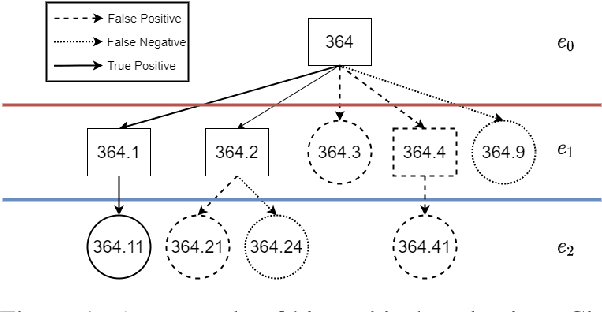

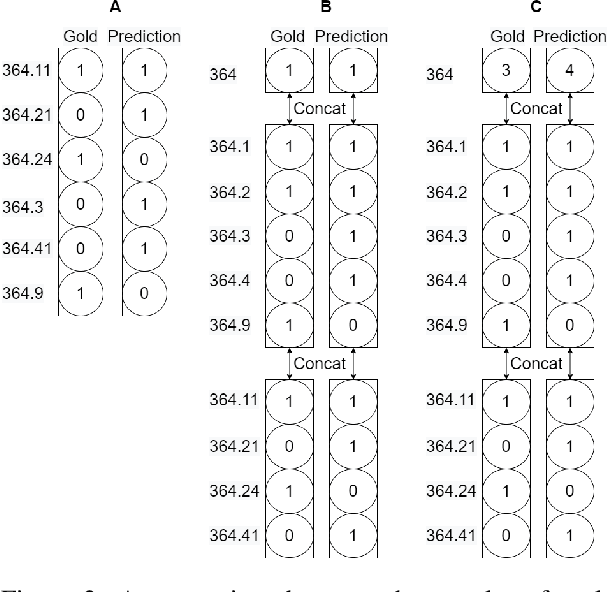

Large-Scale Multi-Label Text Classification (LMTC) includes tasks with hierarchical label spaces, such as automatic assignment of ICD-9 codes to discharge summaries. Performance of models in prior art is evaluated with standard precision, recall, and F1 measures without regard for the rich hierarchical structure. In this work we argue for hierarchical evaluation of the predictions of neural LMTC models. With the example of the ICD-9 ontology we describe a structural issue in the representation of the structured label space in prior art, and propose an alternative representation based on the depth of the ontology. We propose a set of metrics for hierarchical evaluation using the depth-based representation. We compare the evaluation scores from the proposed metrics with previously used metrics on prior art LMTC models for ICD-9 coding in MIMIC-III. We also propose further avenues of research involving the proposed ontological representation.
Paying Per-label Attention for Multi-label Extraction from Radiology Reports
Aug 07, 2020Training medical image analysis models requires large amounts of expertly annotated data which is time-consuming and expensive to obtain. Images are often accompanied by free-text radiology reports which are a rich source of information. In this paper, we tackle the automated extraction of structured labels from head CT reports for imaging of suspected stroke patients, using deep learning. Firstly, we propose a set of 31 labels which correspond to radiographic findings (e.g. hyperdensity) and clinical impressions (e.g. haemorrhage) related to neurological abnormalities. Secondly, inspired by previous work, we extend existing state-of-the-art neural network models with a label-dependent attention mechanism. Using this mechanism and simple synthetic data augmentation, we are able to robustly extract many labels with a single model, classified according to the radiologist's reporting (positive, uncertain, negative). This approach can be used in further research to effectively extract many labels from medical text.
Language Transfer for Early Warning of Epidemics from Social Media
Oct 10, 2019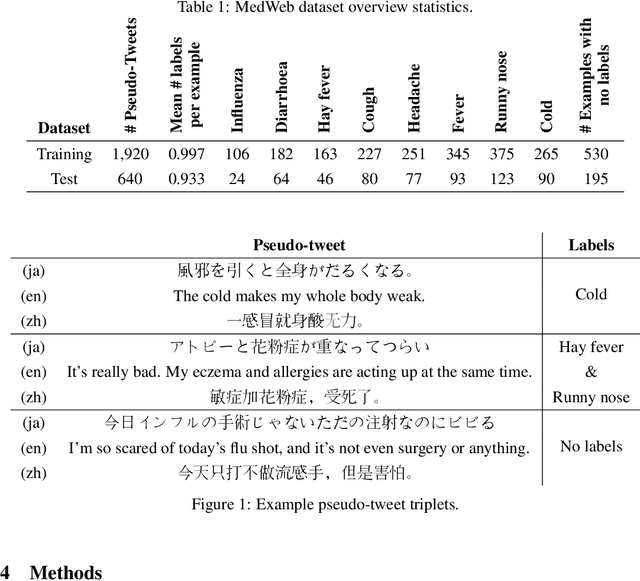
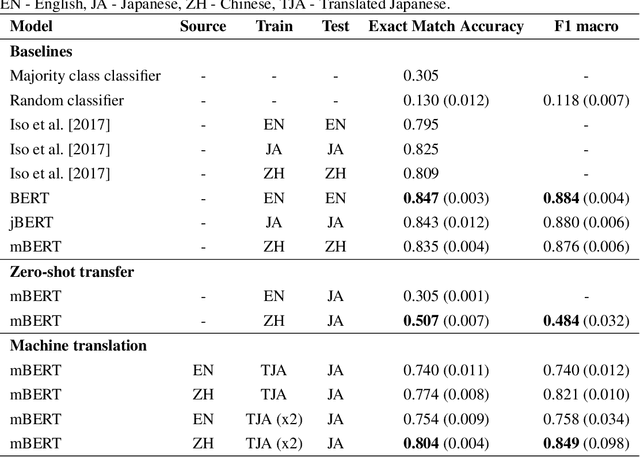
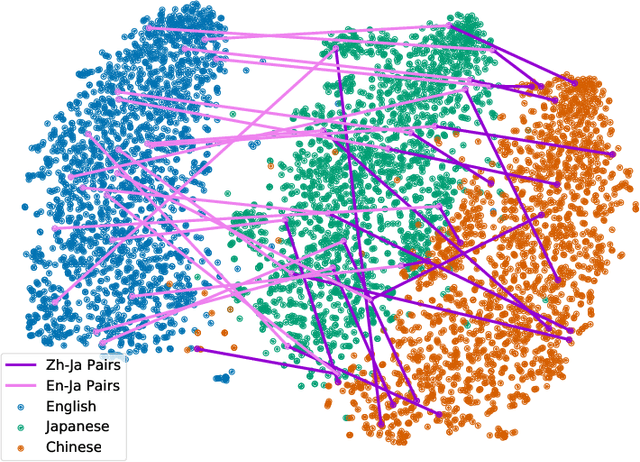
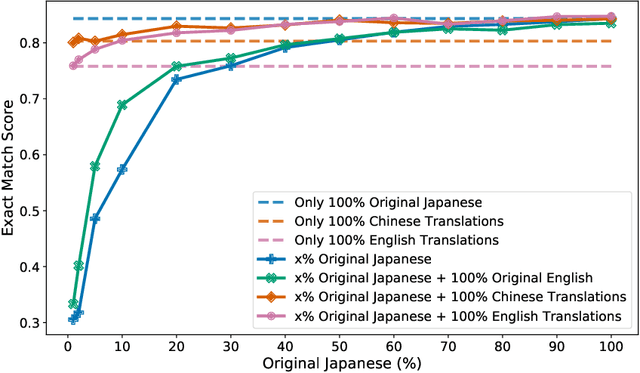
Statements on social media can be analysed to identify individuals who are experiencing red flag medical symptoms, allowing early detection of the spread of disease such as influenza. Since disease does not respect cultural borders and may spread between populations speaking different languages, we would like to build multilingual models. However, the data required to train models for every language may be difficult, expensive and time-consuming to obtain, particularly for low-resource languages. Taking Japanese as our target language, we explore methods by which data in one language might be used to build models for a different language. We evaluate strategies of training on machine translated data and of zero-shot transfer through the use of multilingual models. We find that the choice of source language impacts the performance, with Chinese-Japanese being a better language pair than English-Japanese. Training on machine translated data shows promise, especially when used in conjunction with a small amount of target language data.