 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGS-BrainText: A Multi-Site Brain Imaging Report Dataset from Generation Scotland for Clinical Natural Language Processing Development and Validation
Mar 27, 2026We present GS-BrainText, a curated dataset of 8,511 brain radiology reports from the Generation Scotland cohort, of which 2,431 are annotated for 24 brain disease phenotypes. This multi-site dataset spans five Scottish NHS health boards and includes broad age representation (mean age 58, median age 53), making it uniquely valuable for developing and evaluating generalisable clinical natural language processing (NLP) algorithms and tools. Expert annotations were performed by a multidisciplinary clinical team using an annotation schema, with 10-100% double annotation per NHS health board and rigorous quality assurance. Benchmark evaluation using EdIE-R, an existing rule-based NLP system developed in conjunction with the annotation schema, revealed some performance variation across health boards (F1: 86.13-98.13), phenotypes (F1: 22.22-100) and age groups (F1: 87.01-98.13), highlighting critical challenges in generalisation of NLP tools. The GS-BrainText dataset addresses a significant gap in available UK clinical text resources and provides a valuable resource for the study of linguistic variation, diagnostic uncertainty expression and the impact of data characteristics on NLP system performance.
Ontology-Based and Weakly Supervised Rare Disease Phenotyping from Clinical Notes
May 11, 2022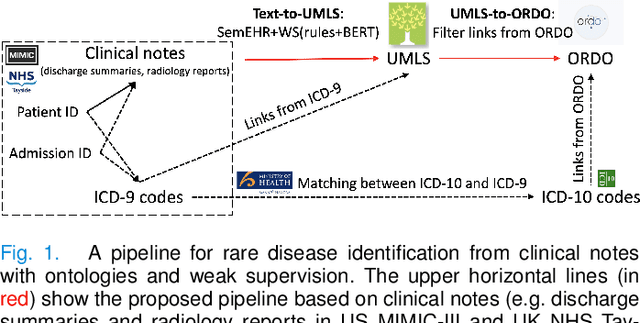
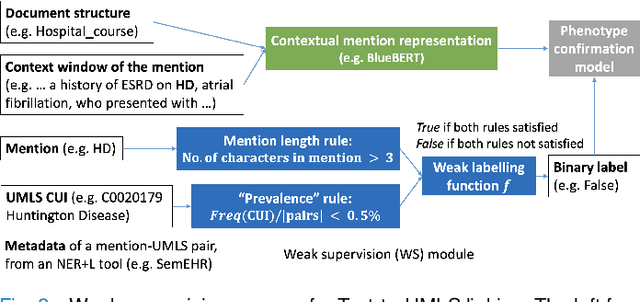
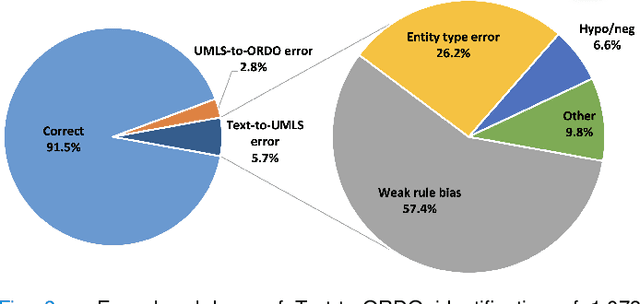
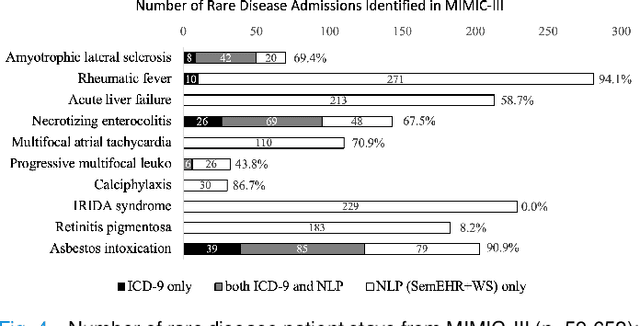
Computational text phenotyping is the practice of identifying patients with certain disorders and traits from clinical notes. Rare diseases are challenging to be identified due to few cases available for machine learning and the need for data annotation from domain experts. We propose a method using ontologies and weak supervision, with recent pre-trained contextual representations from Bi-directional Transformers (e.g. BERT). The ontology-based framework includes two steps: (i) Text-to-UMLS, extracting phenotypes by contextually linking mentions to concepts in Unified Medical Language System (UMLS), with a Named Entity Recognition and Linking (NER+L) tool, SemEHR, and weak supervision with customised rules and contextual mention representation; (ii) UMLS-to-ORDO, matching UMLS concepts to rare diseases in Orphanet Rare Disease Ontology (ORDO). The weakly supervised approach is proposed to learn a phenotype confirmation model to improve Text-to-UMLS linking, without annotated data from domain experts. We evaluated the approach on three clinical datasets of discharge summaries and radiology reports from two institutions in the US and the UK. Our best weakly supervised method achieved 81.4% precision and 91.4% recall on extracting rare disease UMLS phenotypes from MIMIC-III discharge summaries. The overall pipeline processing clinical notes can surface rare disease cases, mostly uncaptured in structured data (manually assigned ICD codes). Results on radiology reports from MIMIC-III and NHS Tayside were consistent with the discharge summaries. We discuss the usefulness of the weak supervision approach and propose directions for future studies.
Automated Clinical Coding: What, Why, and Where We Are?
Mar 21, 2022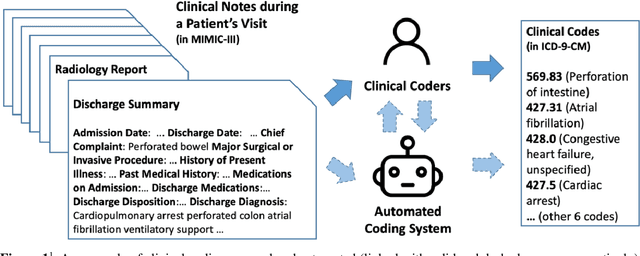
Clinical coding is the task of transforming medical information in a patient's health records into structured codes so that they can be used for statistical analysis. This is a cognitive and time-consuming task that follows a standard process in order to achieve a high level of consistency. Clinical coding could potentially be supported by an automated system to improve the efficiency and accuracy of the process. We introduce the idea of automated clinical coding and summarise its challenges from the perspective of Artificial Intelligence (AI) and Natural Language Processing (NLP), based on the literature, our project experience over the past two and half years (late 2019 - early 2022), and discussions with clinical coding experts in Scotland and the UK. Our research reveals the gaps between the current deep learning-based approach applied to clinical coding and the need for explainability and consistency in real-world practice. Knowledge-based methods that represent and reason the standard, explainable process of a task may need to be incorporated into deep learning-based methods for clinical coding. Automated clinical coding is a promising task for AI, despite the technical and organisational challenges. Coders are needed to be involved in the development process. There is much to achieve to develop and deploy an AI-based automated system to support coding in the next five years and beyond.
A Systematic Review of Natural Language Processing Applied to Radiology Reports
Feb 18, 2021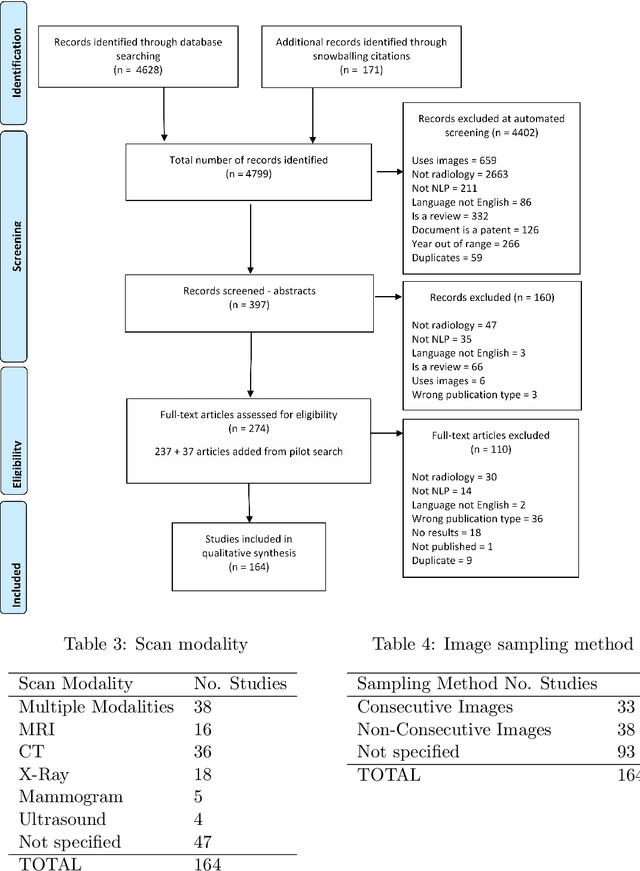
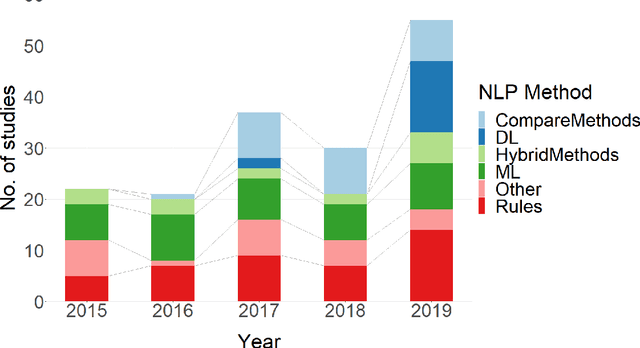
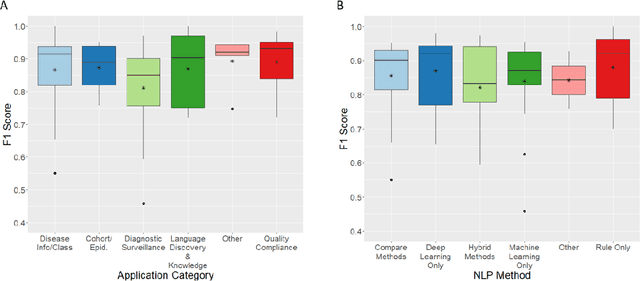
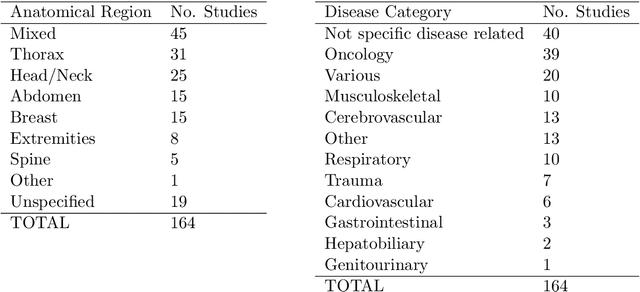
NLP has a significant role in advancing healthcare and has been found to be key in extracting structured information from radiology reports. Understanding recent developments in NLP application to radiology is of significance but recent reviews on this are limited. This study systematically assesses recent literature in NLP applied to radiology reports. Our automated literature search yields 4,799 results using automated filtering, metadata enriching steps and citation search combined with manual review. Our analysis is based on 21 variables including radiology characteristics, NLP methodology, performance, study, and clinical application characteristics. We present a comprehensive analysis of the 164 publications retrieved with each categorised into one of 6 clinical application categories. Deep learning use increases but conventional machine learning approaches are still prevalent. Deep learning remains challenged when data is scarce and there is little evidence of adoption into clinical practice. Despite 17% of studies reporting greater than 0.85 F1 scores, it is hard to comparatively evaluate these approaches given that most of them use different datasets. Only 14 studies made their data and 15 their code available with 10 externally validating results. Automated understanding of clinical narratives of the radiology reports has the potential to enhance the healthcare process but reproducibility and explainability of models are important if the domain is to move applications into clinical use. More could be done to share code enabling validation of methods on different institutional data and to reduce heterogeneity in reporting of study properties allowing inter-study comparisons. Our results have significance for researchers providing a systematic synthesis of existing work to build on, identify gaps, opportunities for collaboration and avoid duplication.
Explainable Automated Coding of Clinical Notes using Hierarchical Label-wise Attention Networks and Label Embedding Initialisation
Oct 30, 2020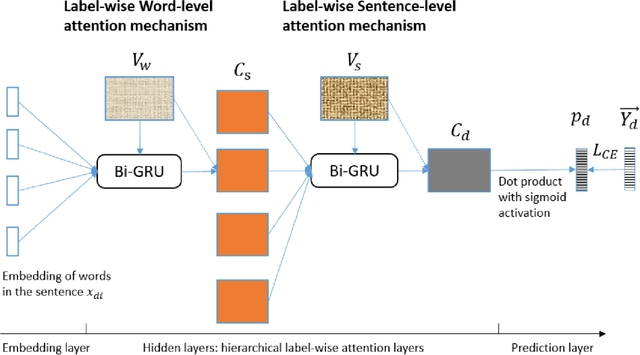
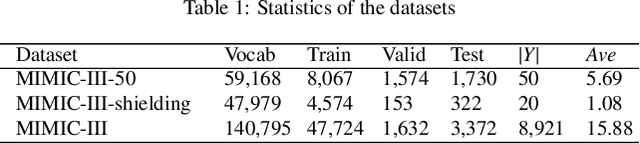
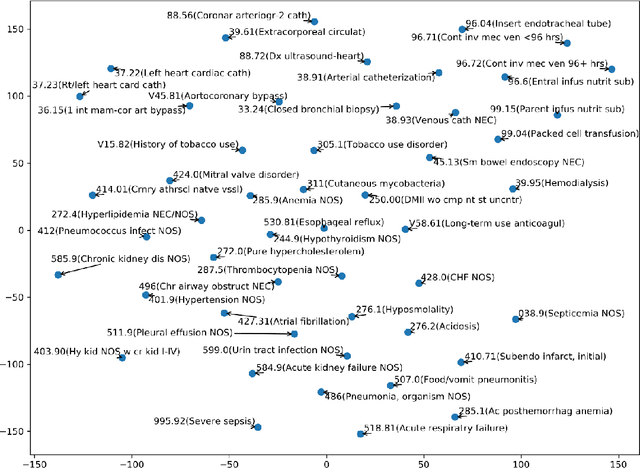
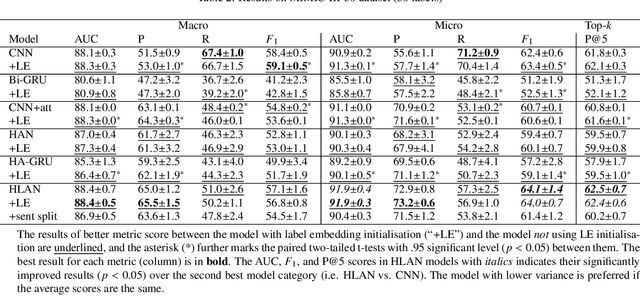
Diagnostic or procedural coding of clinical notes aims to derive a coded summary of disease-related information about patients. Such coding is usually done manually in hospitals but could potentially be automated to improve the efficiency and accuracy of medical coding. Recent studies on deep learning for automated medical coding achieved promising performances. However, the explainability of these models is usually poor, preventing them to be used confidently in supporting clinical practice. Another limitation is that these models mostly assume independence among labels, ignoring the complex correlation among medical codes which can potentially be exploited to improve the performance. We propose a Hierarchical Label-wise Attention Network (HLAN), which aimed to interpret the model by quantifying importance (as attention weights) of words and sentences related to each of the labels. Secondly, we propose to enhance the major deep learning models with a label embedding (LE) initialisation approach, which learns a dense, continuous vector representation and then injects the representation into the final layers and the label-wise attention layers in the models. We evaluated the methods using three settings on the MIMIC-III discharge summaries: full codes, top-50 codes, and the UK NHS COVID-19 shielding codes. Experiments were conducted to compare HLAN and LE initialisation to the state-of-the-art neural network based methods. HLAN achieved the best Micro-level AUC and $F_1$ on the top-50 code prediction and comparable results on the NHS COVID-19 shielding code prediction to other models. By highlighting the most salient words and sentences for each label, HLAN showed more meaningful and comprehensive model interpretation compared to its downgraded baselines and the CNN-based models. LE initialisation consistently boosted most deep learning models for automated medical coding.
FastPET: Near Real-Time PET Reconstruction from Histo-Images Using a Neural Network
Feb 11, 2020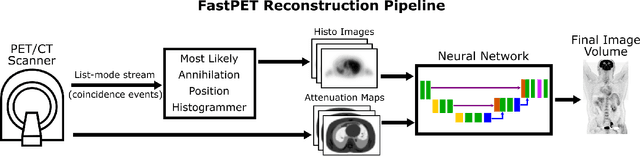
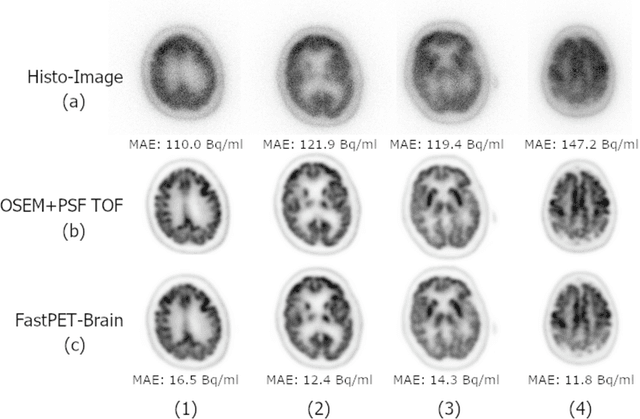
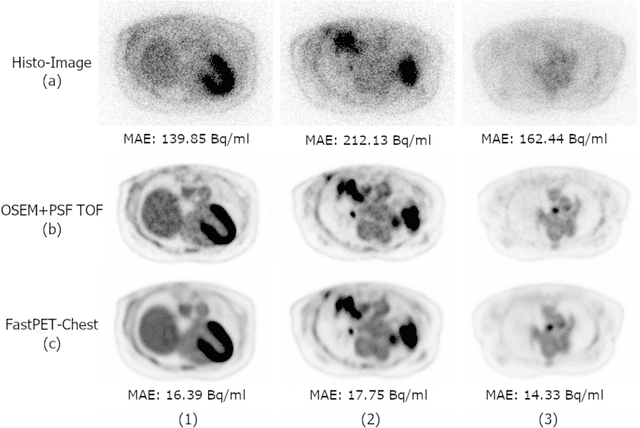
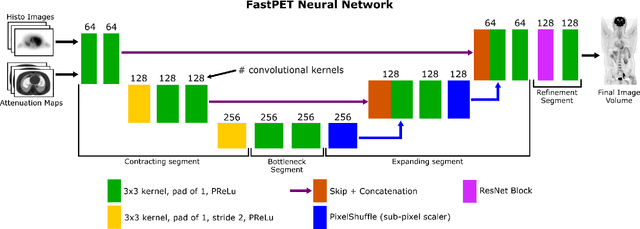
Direct reconstruction of positron emission tomography (PET) data using deep neural networks is a growing field of research. Initial results are promising, but often the networks are complex, memory utilization inefficient, produce relatively small image sizes (e.g. 128x128), and low count rate reconstructions are of varying quality. This paper proposes FastPET, a novel direct reconstruction convolutional neural network that is architecturally simple, memory space efficient, produces larger images (e.g. 440x440) and is capable of processing a wide range of count densities. FastPET operates on noisy and blurred histo-images reconstructing clinical-quality multi-slice image volumes 800x faster than ordered subsets expectation maximization (OSEM). Patient data studies show a higher contrast recovery value than for OSEM with equivalent variance and a higher overall signal-to-noise ratio with both cases due to FastPET's lower noise images. This work also explored the application to low dose PET imaging and found FastPET able to produce images comparable to normal dose with only 50% and 25% counts. We additionally explored the effect of reducing the anatomical region by training specific FastPET variants on brain and chest images and found narrowing the data distribution led to increased performance.
Direct Neural Network 3D Image Reconstruction of Radon Encoded Data
Aug 19, 2019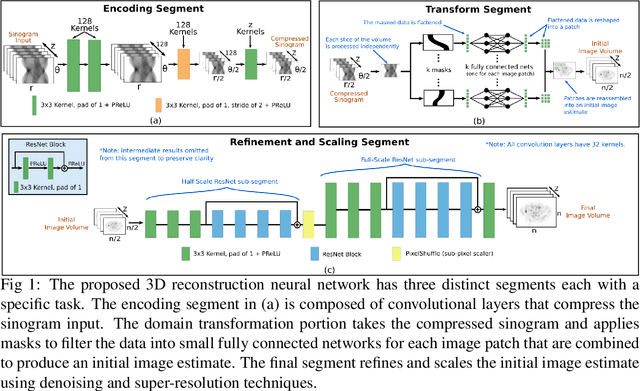
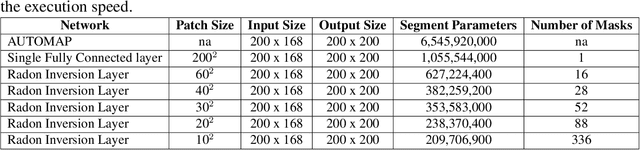
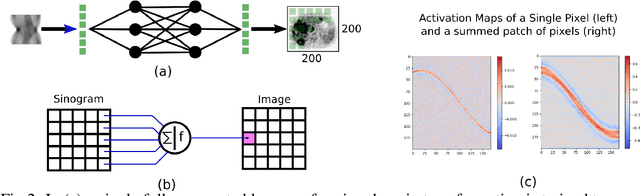

Neural network image reconstruction directly from measurement data is a growing field of research, but until now has been limited to producing small (e.g. 128x128) 2D images by the large memory requirements of the previously suggested networks. In order to facilitate further research with direct reconstruction, we developed a more efficient network capable of 3D reconstruction of Radon encoded data with a relatively large image matrix (e.g. 400x400). Our proposed network is able to produce image quality comparable to the benchmark Ordered Subsets Expectation Maximization (OSEM) algorithm. We address the most memory intensive aspect of transforming the data from sinogram space to image space through a specially designed Radon inversion layer. We insert this layer between an initial network segment designed to encode the sinogram input and an output segment designed to refine and scale the initial image estimate to produce the final image. We demonstrate 3D reconstructions comparable to OSEM for 1, 4, 8 and 16 slices with no modifications to the network's architecture, capacity or hyper-parameters on a data set of simulated PET whole-body scans. When batch operations are considered, this network can reconstruct an entire PET whole-body volume in a single pass or about one second. Although results in this paper are on PET data, the proposed methods would be equally applicable to X-ray CT or any other Radon encoded measurement data.
Named Entity Recognition for Electronic Health Records: A Comparison of Rule-based and Machine Learning Approaches
Mar 10, 2019

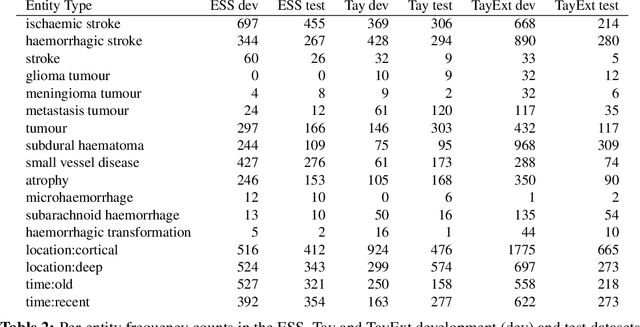
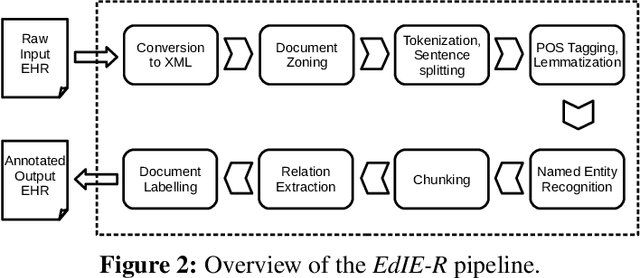
This work investigates multiple approaches to Named Entity Recognition (NER) for text in Electronic Health Record (EHR) data. In particular, we look into the application of (i) rule-based, (ii) deep learning and (iii) transfer learning systems for the task of NER on brain imaging reports with a focus on records from patients with stroke. We explore the strengths and weaknesses of each approach, develop rules and train on a common dataset, and evaluate each system's performance on common test sets of Scottish radiology reports from two sources (brain imaging reports in ESS -- Edinburgh Stroke Study data collected by NHS Lothian as well as radiology reports created in NHS Tayside). Our comparison shows that a hand-crafted system is the most accurate way to automatically label EHR, but machine learning approaches can provide a feasible alternative where resources for a manual system are not readily available.