 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerceptions of Edinburgh: Capturing Neighbourhood Characteristics by Clustering Geoparsed Local News
Sep 17, 2024



The communities that we live in affect our health in ways that are complex and hard to define. Moreover, our understanding of the place-based processes affecting health and inequalities is limited. This undermines the development of robust policy interventions to improve local health and well-being. News media provides social and community information that may be useful in health studies. Here we propose a methodology for characterising neighbourhoods by using local news articles. More specifically, we show how we can use Natural Language Processing (NLP) to unlock further information about neighbourhoods by analysing, geoparsing and clustering news articles. Our work is novel because we combine street-level geoparsing tailored to the locality with clustering of full news articles, enabling a more detailed examination of neighbourhood characteristics. We evaluate our outputs and show via a confluence of evidence, both from a qualitative and a quantitative perspective, that the themes we extract from news articles are sensible and reflect many characteristics of the real world. This is significant because it allows us to better understand the effects of neighbourhoods on health. Our findings on neighbourhood characterisation using news data will support a new generation of place-based research which examines a wider set of spatial processes and how they affect health, enabling new epidemiological research.
A Systematic Review of Natural Language Processing Applied to Radiology Reports
Feb 18, 2021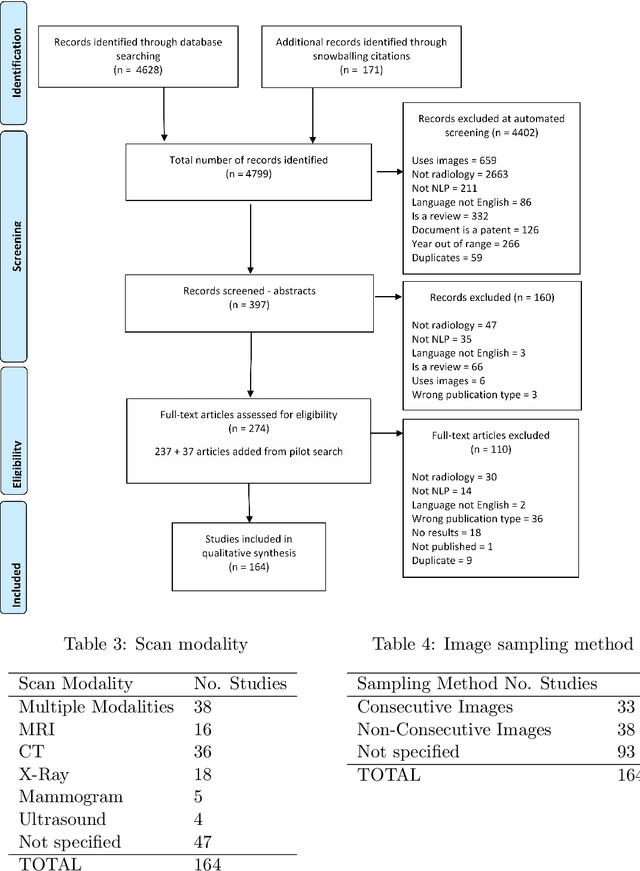
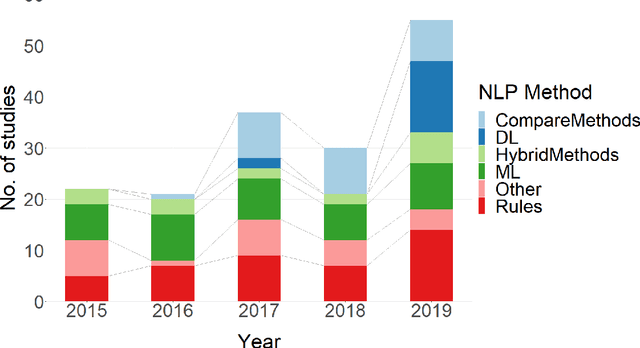
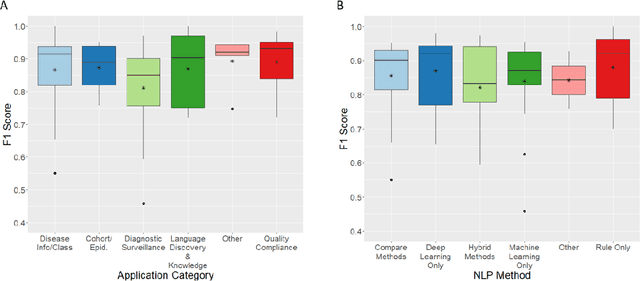
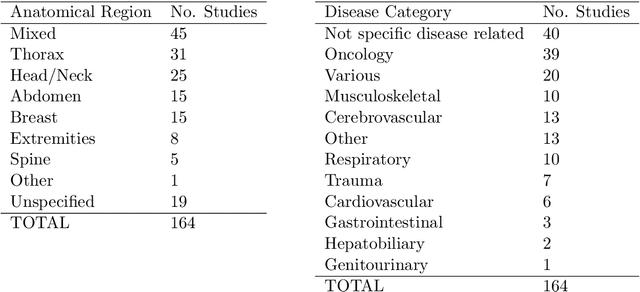
NLP has a significant role in advancing healthcare and has been found to be key in extracting structured information from radiology reports. Understanding recent developments in NLP application to radiology is of significance but recent reviews on this are limited. This study systematically assesses recent literature in NLP applied to radiology reports. Our automated literature search yields 4,799 results using automated filtering, metadata enriching steps and citation search combined with manual review. Our analysis is based on 21 variables including radiology characteristics, NLP methodology, performance, study, and clinical application characteristics. We present a comprehensive analysis of the 164 publications retrieved with each categorised into one of 6 clinical application categories. Deep learning use increases but conventional machine learning approaches are still prevalent. Deep learning remains challenged when data is scarce and there is little evidence of adoption into clinical practice. Despite 17% of studies reporting greater than 0.85 F1 scores, it is hard to comparatively evaluate these approaches given that most of them use different datasets. Only 14 studies made their data and 15 their code available with 10 externally validating results. Automated understanding of clinical narratives of the radiology reports has the potential to enhance the healthcare process but reproducibility and explainability of models are important if the domain is to move applications into clinical use. More could be done to share code enabling validation of methods on different institutional data and to reduce heterogeneity in reporting of study properties allowing inter-study comparisons. Our results have significance for researchers providing a systematic synthesis of existing work to build on, identify gaps, opportunities for collaboration and avoid duplication.
Plague Dot Text: Text mining and annotation of outbreak reports of the Third Plague Pandemic
Feb 04, 2020
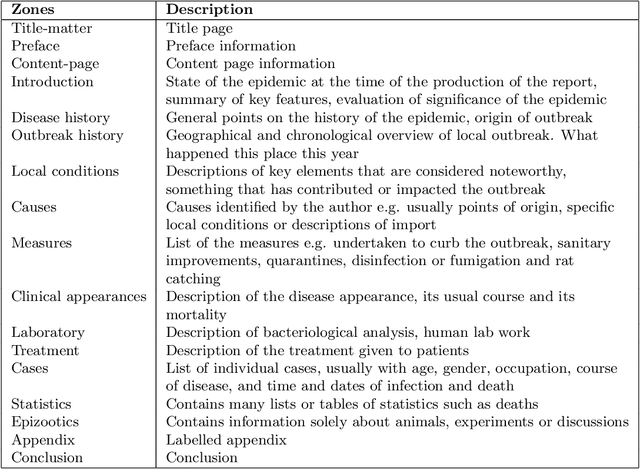
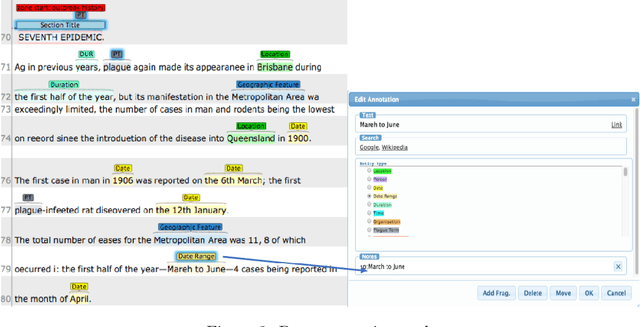
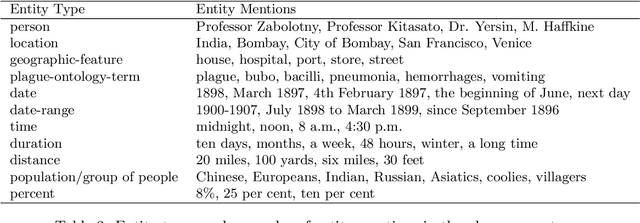
The design of models that govern diseases in population is commonly built on information and data gathered from past outbreaks. However, epidemic outbreaks are never captured in statistical data alone but are communicated by narratives, supported by empirical observations. Outbreak reports discuss correlations between populations, locations and the disease to infer insights into causes, vectors and potential interventions. The problem with these narratives is usually the lack of consistent structure or strong conventions, which prohibit their formal analysis in larger corpora. Our interdisciplinary research investigates more than 100 reports from the third plague pandemic (1894-1952) evaluating ways of building a corpus to extract and structure this narrative information through text mining and manual annotation. In this paper we discuss the progress of our ongoing exploratory project, how we enhance optical character recognition (OCR) methods to improve text capture, our approach to structure the narratives and identify relevant entities in the reports. The structured corpus is made available via Solr enabling search and analysis across the whole collection for future research dedicated, for example, to the identification of concepts. We show preliminary visualisations of the characteristics of causation and differences with respect to gender as a result of syntactic-category-dependent corpus statistics. Our goal is to develop structured accounts of some of the most significant concepts that were used to understand the epidemiology of the third plague pandemic around the globe. The corpus enables researchers to analyse the reports collectively allowing for deep insights into the global epidemiological consideration of plague in the early twentieth century.
Named Entity Recognition for Electronic Health Records: A Comparison of Rule-based and Machine Learning Approaches
Mar 10, 2019

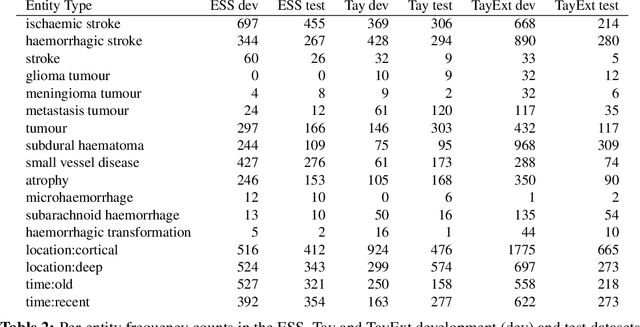
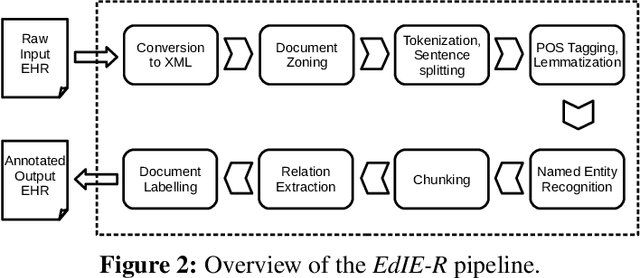
This work investigates multiple approaches to Named Entity Recognition (NER) for text in Electronic Health Record (EHR) data. In particular, we look into the application of (i) rule-based, (ii) deep learning and (iii) transfer learning systems for the task of NER on brain imaging reports with a focus on records from patients with stroke. We explore the strengths and weaknesses of each approach, develop rules and train on a common dataset, and evaluate each system's performance on common test sets of Scottish radiology reports from two sources (brain imaging reports in ESS -- Edinburgh Stroke Study data collected by NHS Lothian as well as radiology reports created in NHS Tayside). Our comparison shows that a hand-crafted system is the most accurate way to automatically label EHR, but machine learning approaches can provide a feasible alternative where resources for a manual system are not readily available.