 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking and Analyzing In-context Learning, Fine-tuning and Supervised Learning for Biomedical Knowledge Curation: a focused study on chemical entities of biological interest
Dec 20, 2023Automated knowledge curation for biomedical ontologies is key to ensure that they remain comprehensive, high-quality and up-to-date. In the era of foundational language models, this study compares and analyzes three NLP paradigms for curation tasks: in-context learning (ICL), fine-tuning (FT), and supervised learning (ML). Using the Chemical Entities of Biological Interest (ChEBI) database as a model ontology, three curation tasks were devised. For ICL, three prompting strategies were employed with GPT-4, GPT-3.5, BioGPT. PubmedBERT was chosen for the FT paradigm. For ML, six embedding models were utilized for training Random Forest and Long-Short Term Memory models. Five setups were designed to assess ML and FT model performance across different data availability scenarios.Datasets for curation tasks included: task 1 (620,386), task 2 (611,430), and task 3 (617,381), maintaining a 50:50 positive versus negative ratio. For ICL models, GPT-4 achieved best accuracy scores of 0.916, 0.766 and 0.874 for tasks 1-3 respectively. In a direct comparison, ML (trained on ~260,000 triples) outperformed ICL in accuracy across all tasks. (accuracy differences: +.11, +.22 and +.17). Fine-tuned PubmedBERT performed similarly to leading ML models in tasks 1 & 2 (F1 differences: -.014 and +.002), but worse in task 3 (-.048). Simulations revealed performance declines in both ML and FT models with smaller and higher imbalanced training data. where ICL (particularly GPT-4) excelled in tasks 1 & 3. GPT-4 excelled in tasks 1 and 3 with less than 6,000 triples, surpassing ML/FT. ICL underperformed ML/FT in task 2.ICL-augmented foundation models can be good assistants for knowledge curation with correct prompting, however, not making ML and FT paradigms obsolete. The latter two require task-specific data to beat ICL. In such cases, ML relies on small pretrained embeddings, minimizing computational demands.
Ontology-Based and Weakly Supervised Rare Disease Phenotyping from Clinical Notes
May 11, 2022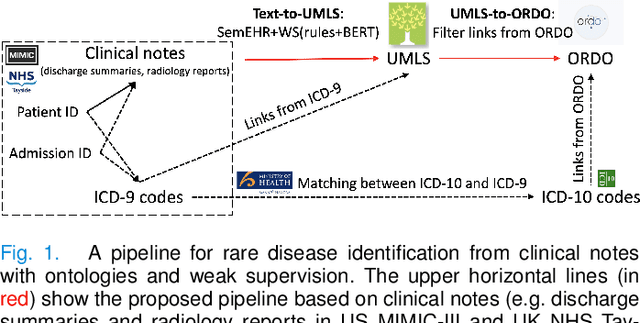
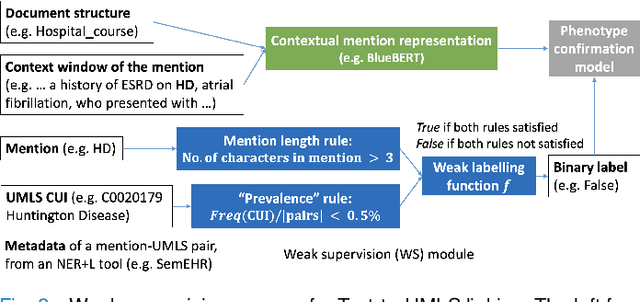
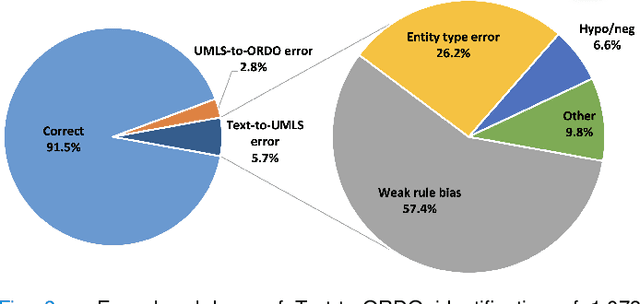
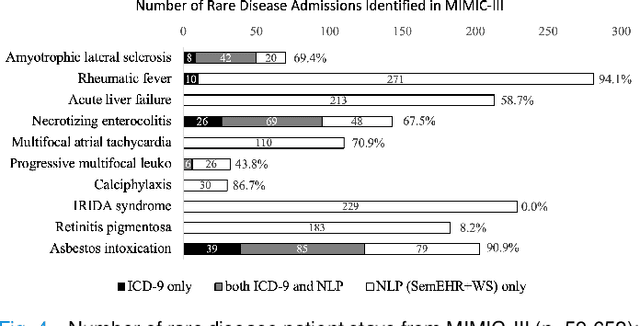
Computational text phenotyping is the practice of identifying patients with certain disorders and traits from clinical notes. Rare diseases are challenging to be identified due to few cases available for machine learning and the need for data annotation from domain experts. We propose a method using ontologies and weak supervision, with recent pre-trained contextual representations from Bi-directional Transformers (e.g. BERT). The ontology-based framework includes two steps: (i) Text-to-UMLS, extracting phenotypes by contextually linking mentions to concepts in Unified Medical Language System (UMLS), with a Named Entity Recognition and Linking (NER+L) tool, SemEHR, and weak supervision with customised rules and contextual mention representation; (ii) UMLS-to-ORDO, matching UMLS concepts to rare diseases in Orphanet Rare Disease Ontology (ORDO). The weakly supervised approach is proposed to learn a phenotype confirmation model to improve Text-to-UMLS linking, without annotated data from domain experts. We evaluated the approach on three clinical datasets of discharge summaries and radiology reports from two institutions in the US and the UK. Our best weakly supervised method achieved 81.4% precision and 91.4% recall on extracting rare disease UMLS phenotypes from MIMIC-III discharge summaries. The overall pipeline processing clinical notes can surface rare disease cases, mostly uncaptured in structured data (manually assigned ICD codes). Results on radiology reports from MIMIC-III and NHS Tayside were consistent with the discharge summaries. We discuss the usefulness of the weak supervision approach and propose directions for future studies.
Quantifying Health Inequalities Induced by Data and AI Models
May 03, 2022


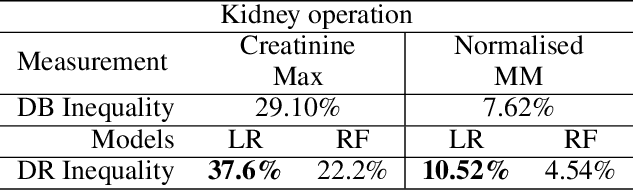
AI technologies are being increasingly tested and applied in critical environments including healthcare. Without an effective way to detect and mitigate AI induced inequalities, AI might do more harm than good, potentially leading to the widening of underlying inequalities. This paper proposes a generic allocation-deterioration framework for detecting and quantifying AI induced inequality. Specifically, AI induced inequalities are quantified as the area between two allocation-deterioration curves. To assess the framework's performance, experiments were conducted on ten synthetic datasets (N>33,000) generated from HiRID - a real-world Intensive Care Unit (ICU) dataset, showing its ability to accurately detect and quantify inequality proportionally to controlled inequalities. Extensive analyses were carried out to quantify health inequalities (a) embedded in two real-world ICU datasets; (b) induced by AI models trained for two resource allocation scenarios. Results showed that compared to men, women had up to 33% poorer deterioration in markers of prognosis when admitted to HiRID ICUs. All four AI models assessed were shown to induce significant inequalities (2.45% to 43.2%) for non-White compared to White patients. The models exacerbated data embedded inequalities significantly in 3 out of 8 assessments, one of which was >9 times worse. The codebase is at https://github.com/knowlab/DAindex-Framework.
Rare Disease Identification from Clinical Notes with Ontologies and Weak Supervision
May 08, 2021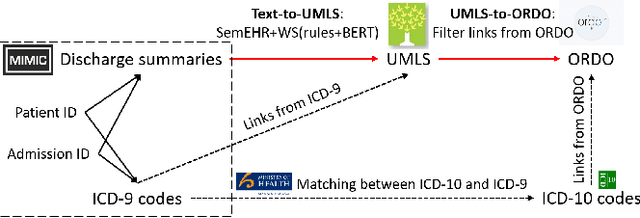
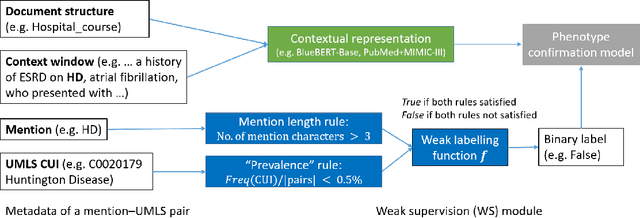


The identification of rare diseases from clinical notes with Natural Language Processing (NLP) is challenging due to the few cases available for machine learning and the need of data annotation from clinical experts. We propose a method using ontologies and weak supervision. The approach includes two steps: (i) Text-to-UMLS, linking text mentions to concepts in Unified Medical Language System (UMLS), with a named entity linking tool (e.g. SemEHR) and weak supervision based on customised rules and Bidirectional Encoder Representations from Transformers (BERT) based contextual representations, and (ii) UMLS-to-ORDO, matching UMLS concepts to rare diseases in Orphanet Rare Disease Ontology (ORDO). Using MIMIC-III discharge summaries as a case study, we show that the Text-to-UMLS process can be greatly improved with weak supervision, without any annotated data from domain experts. Our analysis shows that the overall pipeline processing discharge summaries can surface rare disease cases, which are mostly uncaptured in manual ICD codes of the hospital admissions.