 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBioHopR: A Benchmark for Multi-Hop, Multi-Answer Reasoning in Biomedical Domain
May 28, 2025

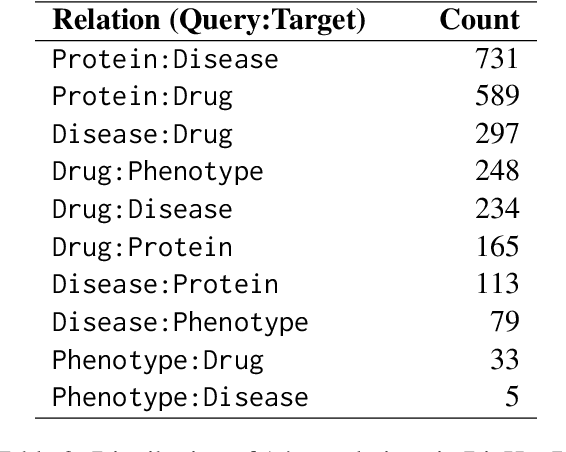
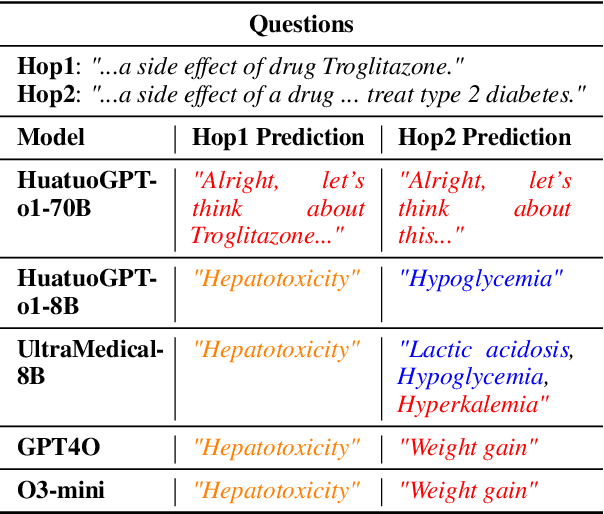
Biomedical reasoning often requires traversing interconnected relationships across entities such as drugs, diseases, and proteins. Despite the increasing prominence of large language models (LLMs), existing benchmarks lack the ability to evaluate multi-hop reasoning in the biomedical domain, particularly for queries involving one-to-many and many-to-many relationships. This gap leaves the critical challenges of biomedical multi-hop reasoning underexplored. To address this, we introduce BioHopR, a novel benchmark designed to evaluate multi-hop, multi-answer reasoning in structured biomedical knowledge graphs. Built from the comprehensive PrimeKG, BioHopR includes 1-hop and 2-hop reasoning tasks that reflect real-world biomedical complexities. Evaluations of state-of-the-art models reveal that O3-mini, a proprietary reasoning-focused model, achieves 37.93% precision on 1-hop tasks and 14.57% on 2-hop tasks, outperforming proprietary models such as GPT4O and open-source biomedical models including HuatuoGPT-o1-70B and Llama-3.3-70B. However, all models exhibit significant declines in multi-hop performance, underscoring the challenges of resolving implicit reasoning steps in the biomedical domain. By addressing the lack of benchmarks for multi-hop reasoning in biomedical domain, BioHopR sets a new standard for evaluating reasoning capabilities and highlights critical gaps between proprietary and open-source models while paving the way for future advancements in biomedical LLMs.
MedExQA: Medical Question Answering Benchmark with Multiple Explanations
Jun 10, 2024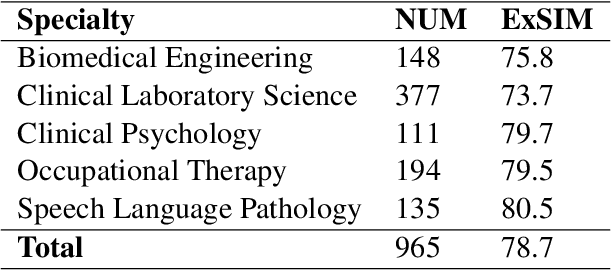
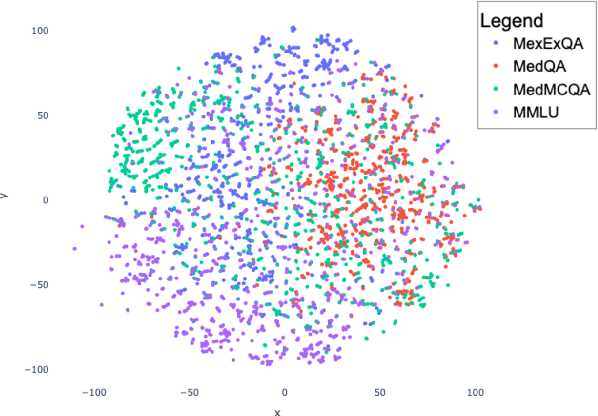
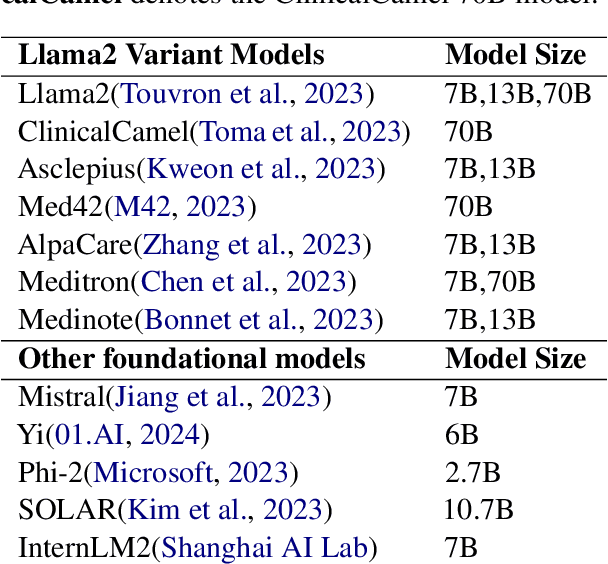
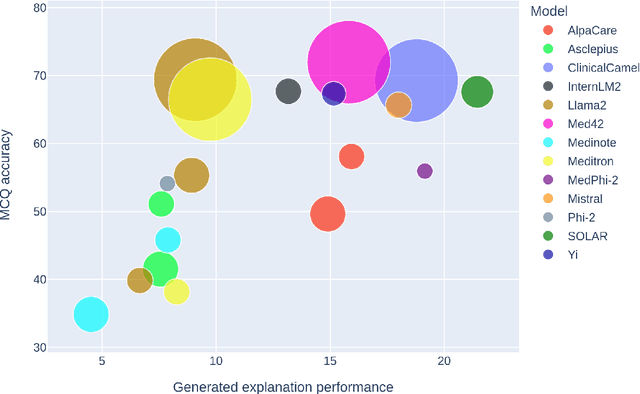
This paper introduces MedExQA, a novel benchmark in medical question-answering, to evaluate large language models' (LLMs) understanding of medical knowledge through explanations. By constructing datasets across five distinct medical specialties that are underrepresented in current datasets and further incorporating multiple explanations for each question-answer pair, we address a major gap in current medical QA benchmarks which is the absence of comprehensive assessments of LLMs' ability to generate nuanced medical explanations. Our work highlights the importance of explainability in medical LLMs, proposes an effective methodology for evaluating models beyond classification accuracy, and sheds light on one specific domain, speech language pathology, where current LLMs including GPT4 lack good understanding. Our results show generation evaluation with multiple explanations aligns better with human assessment, highlighting an opportunity for a more robust automated comprehension assessment for LLMs. To diversify open-source medical LLMs (currently mostly based on Llama2), this work also proposes a new medical model, MedPhi-2, based on Phi-2 (2.7B). The model outperformed medical LLMs based on Llama2-70B in generating explanations, showing its effectiveness in the resource-constrained medical domain. We will share our benchmark datasets and the trained model.
Enhancing Human-Computer Interaction in Chest X-ray Analysis using Vision and Language Model with Eye Gaze Patterns
Apr 03, 2024Recent advancements in Computer Assisted Diagnosis have shown promising performance in medical imaging tasks, particularly in chest X-ray analysis. However, the interaction between these models and radiologists has been primarily limited to input images. This work proposes a novel approach to enhance human-computer interaction in chest X-ray analysis using Vision-Language Models (VLMs) enhanced with radiologists' attention by incorporating eye gaze data alongside textual prompts. Our approach leverages heatmaps generated from eye gaze data, overlaying them onto medical images to highlight areas of intense radiologist's focus during chest X-ray evaluation. We evaluate this methodology in tasks such as visual question answering, chest X-ray report automation, error detection, and differential diagnosis. Our results demonstrate the inclusion of eye gaze information significantly enhances the accuracy of chest X-ray analysis. Also, the impact of eye gaze on fine-tuning was confirmed as it outperformed other medical VLMs in all tasks except visual question answering. This work marks the potential of leveraging both the VLM's capabilities and the radiologist's domain knowledge to improve the capabilities of AI models in medical imaging, paving a novel way for Computer Assisted Diagnosis with a human-centred AI.
Benchmarking and Analyzing In-context Learning, Fine-tuning and Supervised Learning for Biomedical Knowledge Curation: a focused study on chemical entities of biological interest
Dec 20, 2023Automated knowledge curation for biomedical ontologies is key to ensure that they remain comprehensive, high-quality and up-to-date. In the era of foundational language models, this study compares and analyzes three NLP paradigms for curation tasks: in-context learning (ICL), fine-tuning (FT), and supervised learning (ML). Using the Chemical Entities of Biological Interest (ChEBI) database as a model ontology, three curation tasks were devised. For ICL, three prompting strategies were employed with GPT-4, GPT-3.5, BioGPT. PubmedBERT was chosen for the FT paradigm. For ML, six embedding models were utilized for training Random Forest and Long-Short Term Memory models. Five setups were designed to assess ML and FT model performance across different data availability scenarios.Datasets for curation tasks included: task 1 (620,386), task 2 (611,430), and task 3 (617,381), maintaining a 50:50 positive versus negative ratio. For ICL models, GPT-4 achieved best accuracy scores of 0.916, 0.766 and 0.874 for tasks 1-3 respectively. In a direct comparison, ML (trained on ~260,000 triples) outperformed ICL in accuracy across all tasks. (accuracy differences: +.11, +.22 and +.17). Fine-tuned PubmedBERT performed similarly to leading ML models in tasks 1 & 2 (F1 differences: -.014 and +.002), but worse in task 3 (-.048). Simulations revealed performance declines in both ML and FT models with smaller and higher imbalanced training data. where ICL (particularly GPT-4) excelled in tasks 1 & 3. GPT-4 excelled in tasks 1 and 3 with less than 6,000 triples, surpassing ML/FT. ICL underperformed ML/FT in task 2.ICL-augmented foundation models can be good assistants for knowledge curation with correct prompting, however, not making ML and FT paradigms obsolete. The latter two require task-specific data to beat ICL. In such cases, ML relies on small pretrained embeddings, minimizing computational demands.