 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Agent Security Tax: Trading Off Security and Collaboration Capabilities in Multi-Agent Systems
Feb 26, 2025As AI agents are increasingly adopted to collaborate on complex objectives, ensuring the security of autonomous multi-agent systems becomes crucial. We develop simulations of agents collaborating on shared objectives to study these security risks and security trade-offs. We focus on scenarios where an attacker compromises one agent, using it to steer the entire system toward misaligned outcomes by corrupting other agents. In this context, we observe infectious malicious prompts - the multi-hop spreading of malicious instructions. To mitigate this risk, we evaluated several strategies: two "vaccination" approaches that insert false memories of safely handling malicious input into the agents' memory stream, and two versions of a generic safety instruction strategy. While these defenses reduce the spread and fulfillment of malicious instructions in our experiments, they tend to decrease collaboration capability in the agent network. Our findings illustrate potential trade-off between security and collaborative efficiency in multi-agent systems, providing insights for designing more secure yet effective AI collaborations.
Multi-Agent Risks from Advanced AI
Feb 19, 2025



The rapid development of advanced AI agents and the imminent deployment of many instances of these agents will give rise to multi-agent systems of unprecedented complexity. These systems pose novel and under-explored risks. In this report, we provide a structured taxonomy of these risks by identifying three key failure modes (miscoordination, conflict, and collusion) based on agents' incentives, as well as seven key risk factors (information asymmetries, network effects, selection pressures, destabilising dynamics, commitment problems, emergent agency, and multi-agent security) that can underpin them. We highlight several important instances of each risk, as well as promising directions to help mitigate them. By anchoring our analysis in a range of real-world examples and experimental evidence, we illustrate the distinct challenges posed by multi-agent systems and their implications for the safety, governance, and ethics of advanced AI.
Benchmarking and Analyzing In-context Learning, Fine-tuning and Supervised Learning for Biomedical Knowledge Curation: a focused study on chemical entities of biological interest
Dec 20, 2023Automated knowledge curation for biomedical ontologies is key to ensure that they remain comprehensive, high-quality and up-to-date. In the era of foundational language models, this study compares and analyzes three NLP paradigms for curation tasks: in-context learning (ICL), fine-tuning (FT), and supervised learning (ML). Using the Chemical Entities of Biological Interest (ChEBI) database as a model ontology, three curation tasks were devised. For ICL, three prompting strategies were employed with GPT-4, GPT-3.5, BioGPT. PubmedBERT was chosen for the FT paradigm. For ML, six embedding models were utilized for training Random Forest and Long-Short Term Memory models. Five setups were designed to assess ML and FT model performance across different data availability scenarios.Datasets for curation tasks included: task 1 (620,386), task 2 (611,430), and task 3 (617,381), maintaining a 50:50 positive versus negative ratio. For ICL models, GPT-4 achieved best accuracy scores of 0.916, 0.766 and 0.874 for tasks 1-3 respectively. In a direct comparison, ML (trained on ~260,000 triples) outperformed ICL in accuracy across all tasks. (accuracy differences: +.11, +.22 and +.17). Fine-tuned PubmedBERT performed similarly to leading ML models in tasks 1 & 2 (F1 differences: -.014 and +.002), but worse in task 3 (-.048). Simulations revealed performance declines in both ML and FT models with smaller and higher imbalanced training data. where ICL (particularly GPT-4) excelled in tasks 1 & 3. GPT-4 excelled in tasks 1 and 3 with less than 6,000 triples, surpassing ML/FT. ICL underperformed ML/FT in task 2.ICL-augmented foundation models can be good assistants for knowledge curation with correct prompting, however, not making ML and FT paradigms obsolete. The latter two require task-specific data to beat ICL. In such cases, ML relies on small pretrained embeddings, minimizing computational demands.
Self-Consistency of Large Language Models under Ambiguity
Oct 20, 2023

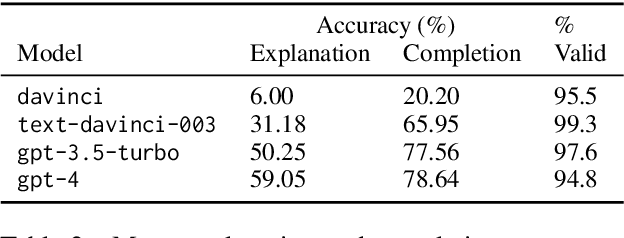

Large language models (LLMs) that do not give consistent answers across contexts are problematic when used for tasks with expectations of consistency, e.g., question-answering, explanations, etc. Our work presents an evaluation benchmark for self-consistency in cases of under-specification where two or more answers can be correct. We conduct a series of behavioral experiments on the OpenAI model suite using an ambiguous integer sequence completion task. We find that average consistency ranges from 67\% to 82\%, far higher than would be predicted if a model's consistency was random, and increases as model capability improves. Furthermore, we show that models tend to maintain self-consistency across a series of robustness checks, including prompting speaker changes and sequence length changes. These results suggest that self-consistency arises as an emergent capability without specifically training for it. Despite this, we find that models are uncalibrated when judging their own consistency, with models displaying both over- and under-confidence. We also propose a nonparametric test for determining from token output distribution whether a model assigns non-trivial probability to alternative answers. Using this test, we find that despite increases in self-consistency, models usually place significant weight on alternative, inconsistent answers. This distribution of probability mass provides evidence that even highly self-consistent models internally compute multiple possible responses.
Detecting Edit Failures In Large Language Models: An Improved Specificity Benchmark
Jun 03, 2023



Recent model editing techniques promise to mitigate the problem of memorizing false or outdated associations during LLM training. However, we show that these techniques can introduce large unwanted side effects which are not detected by existing specificity benchmarks. We extend the existing CounterFact benchmark to include a dynamic component and dub our benchmark CounterFact+. Additionally, we extend the metrics used for measuring specificity by a principled KL divergence-based metric. We use this improved benchmark to evaluate recent model editing techniques and find that they suffer from low specificity. Our findings highlight the need for improved specificity benchmarks that identify and prevent unwanted side effects.
Leveraging knowledge graphs to update scientific word embeddings using latent semantic imputation
Oct 27, 2022



The most interesting words in scientific texts will often be novel or rare. This presents a challenge for scientific word embedding models to determine quality embedding vectors for useful terms that are infrequent or newly emerging. We demonstrate how \gls{lsi} can address this problem by imputing embeddings for domain-specific words from up-to-date knowledge graphs while otherwise preserving the original word embedding model. We use the MeSH knowledge graph to impute embedding vectors for biomedical terminology without retraining and evaluate the resulting embedding model on a domain-specific word-pair similarity task. We show that LSI can produce reliable embedding vectors for rare and OOV terms in the biomedical domain.
Domain-adaptation of spherical embeddings
Nov 01, 2021
Domain adaptation of embedding models, updating a generic embedding to the language of a specific domain, is a proven technique for domains that have insufficient data to train an effective model from scratch. Chemistry publications is one such domain, where scientific jargon and overloaded terminology inhibit the performance of a general language model. The recent spherical embedding model (JoSE) proposed in arXiv:1911.01196 jointly learns word and document embeddings during training on the multi-dimensional unit sphere, which performs well for document classification and word correlation tasks. But, we show a non-convergence caused by global rotations during its training prevents it from domain adaptation. In this work, we develop methods to counter the global rotation of the embedding space and propose strategies to update words and documents during domain specific training. Two new document classification data-sets are collated from general and chemistry scientific journals to compare the proposed update training strategies with benchmark models. We show that our strategies are able to reduce the performance cost of domain adaptation to a level similar to Word2Vec.