 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Activation Steering in Language Models with Mean-Centring
Dec 06, 2023



Recent work in activation steering has demonstrated the potential to better control the outputs of Large Language Models (LLMs), but it involves finding steering vectors. This is difficult because engineers do not typically know how features are represented in these models. We seek to address this issue by applying the idea of mean-centring to steering vectors. We find that taking the average of activations associated with a target dataset, and then subtracting the mean of all training activations, results in effective steering vectors. We test this method on a variety of models on natural language tasks by steering away from generating toxic text, and steering the completion of a story towards a target genre. We also apply mean-centring to extract function vectors, more effectively triggering the execution of a range of natural language tasks by a significant margin (compared to previous baselines). This suggests that mean-centring can be used to easily improve the effectiveness of activation steering in a wide range of contexts.
Self-Consistency of Large Language Models under Ambiguity
Oct 20, 2023

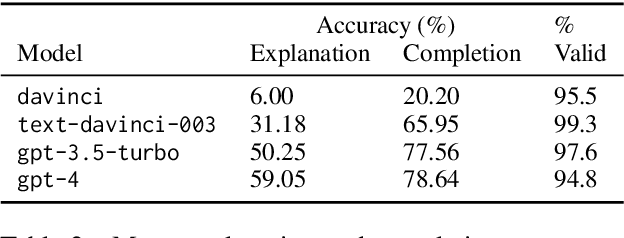

Large language models (LLMs) that do not give consistent answers across contexts are problematic when used for tasks with expectations of consistency, e.g., question-answering, explanations, etc. Our work presents an evaluation benchmark for self-consistency in cases of under-specification where two or more answers can be correct. We conduct a series of behavioral experiments on the OpenAI model suite using an ambiguous integer sequence completion task. We find that average consistency ranges from 67\% to 82\%, far higher than would be predicted if a model's consistency was random, and increases as model capability improves. Furthermore, we show that models tend to maintain self-consistency across a series of robustness checks, including prompting speaker changes and sequence length changes. These results suggest that self-consistency arises as an emergent capability without specifically training for it. Despite this, we find that models are uncalibrated when judging their own consistency, with models displaying both over- and under-confidence. We also propose a nonparametric test for determining from token output distribution whether a model assigns non-trivial probability to alternative answers. Using this test, we find that despite increases in self-consistency, models usually place significant weight on alternative, inconsistent answers. This distribution of probability mass provides evidence that even highly self-consistent models internally compute multiple possible responses.