 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRare Disease Identification from Clinical Notes with Ontologies and Weak Supervision
Paper and Code
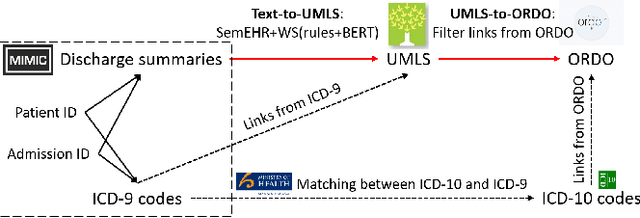
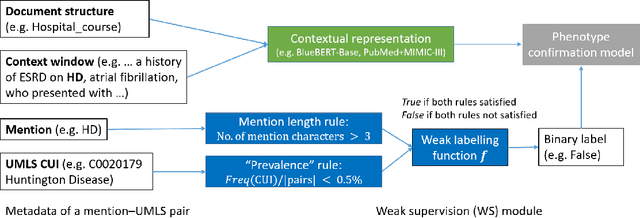


The identification of rare diseases from clinical notes with Natural Language Processing (NLP) is challenging due to the few cases available for machine learning and the need of data annotation from clinical experts. We propose a method using ontologies and weak supervision. The approach includes two steps: (i) Text-to-UMLS, linking text mentions to concepts in Unified Medical Language System (UMLS), with a named entity linking tool (e.g. SemEHR) and weak supervision based on customised rules and Bidirectional Encoder Representations from Transformers (BERT) based contextual representations, and (ii) UMLS-to-ORDO, matching UMLS concepts to rare diseases in Orphanet Rare Disease Ontology (ORDO). Using MIMIC-III discharge summaries as a case study, we show that the Text-to-UMLS process can be greatly improved with weak supervision, without any annotated data from domain experts. Our analysis shows that the overall pipeline processing discharge summaries can surface rare disease cases, which are mostly uncaptured in manual ICD codes of the hospital admissions.