 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrounding Chest X-Ray Visual Question Answering with Generated Radiology Reports
May 22, 2025We present a novel approach to Chest X-ray (CXR) Visual Question Answering (VQA), addressing both single-image image-difference questions. Single-image questions focus on abnormalities within a specific CXR ("What abnormalities are seen in image X?"), while image-difference questions compare two longitudinal CXRs acquired at different time points ("What are the differences between image X and Y?"). We further explore how the integration of radiology reports can enhance the performance of VQA models. While previous approaches have demonstrated the utility of radiology reports during the pre-training phase, we extend this idea by showing that the reports can also be leveraged as additional input to improve the VQA model's predicted answers. First, we propose a unified method that handles both types of questions and auto-regressively generates the answers. For single-image questions, the model is provided with a single CXR. For image-difference questions, the model is provided with two CXRs from the same patient, captured at different time points, enabling the model to detect and describe temporal changes. Taking inspiration from 'Chain-of-Thought reasoning', we demonstrate that performance on the CXR VQA task can be improved by grounding the answer generator module with a radiology report predicted for the same CXR. In our approach, the VQA model is divided into two steps: i) Report Generation (RG) and ii) Answer Generation (AG). Our results demonstrate that incorporating predicted radiology reports as evidence to the AG model enhances performance on both single-image and image-difference questions, achieving state-of-the-art results on the Medical-Diff-VQA dataset.
The role of noise in denoising models for anomaly detection in medical images
Jan 19, 2023



Pathological brain lesions exhibit diverse appearance in brain images, in terms of intensity, texture, shape, size, and location. Comprehensive sets of data and annotations are difficult to acquire. Therefore, unsupervised anomaly detection approaches have been proposed using only normal data for training, with the aim of detecting outlier anomalous voxels at test time. Denoising methods, for instance classical denoising autoencoders (DAEs) and more recently emerging diffusion models, are a promising approach, however naive application of pixelwise noise leads to poor anomaly detection performance. We show that optimization of the spatial resolution and magnitude of the noise improves the performance of different model training regimes, with similar noise parameter adjustments giving good performance for both DAEs and diffusion models. Visual inspection of the reconstructions suggests that the training noise influences the trade-off between the extent of the detail that is reconstructed and the extent of erasure of anomalies, both of which contribute to better anomaly detection performance. We validate our findings on two real-world datasets (tumor detection in brain MRI and hemorrhage/ischemia/tumor detection in brain CT), showing good detection on diverse anomaly appearances. Overall, we find that a DAE trained with coarse noise is a fast and simple method that gives state-of-the-art accuracy. Diffusion models applied to anomaly detection are as yet in their infancy and provide a promising avenue for further research.
Paying Per-label Attention for Multi-label Extraction from Radiology Reports
Aug 07, 2020Training medical image analysis models requires large amounts of expertly annotated data which is time-consuming and expensive to obtain. Images are often accompanied by free-text radiology reports which are a rich source of information. In this paper, we tackle the automated extraction of structured labels from head CT reports for imaging of suspected stroke patients, using deep learning. Firstly, we propose a set of 31 labels which correspond to radiographic findings (e.g. hyperdensity) and clinical impressions (e.g. haemorrhage) related to neurological abnormalities. Secondly, inspired by previous work, we extend existing state-of-the-art neural network models with a label-dependent attention mechanism. Using this mechanism and simple synthetic data augmentation, we are able to robustly extract many labels with a single model, classified according to the radiologist's reporting (positive, uncertain, negative). This approach can be used in further research to effectively extract many labels from medical text.
Language Transfer for Early Warning of Epidemics from Social Media
Oct 10, 2019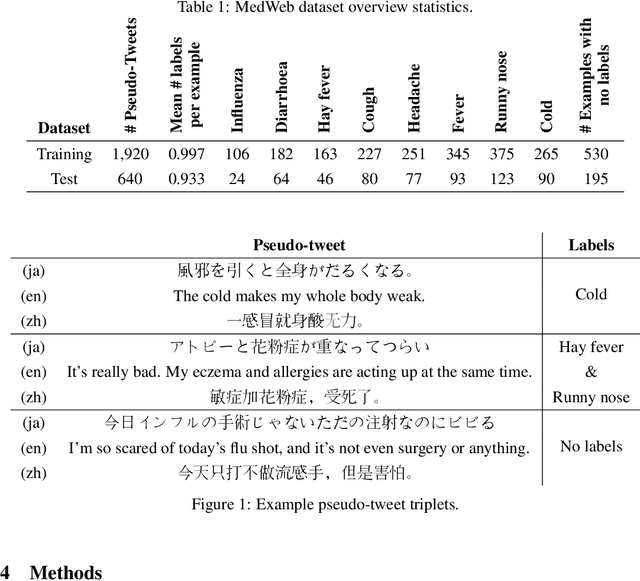
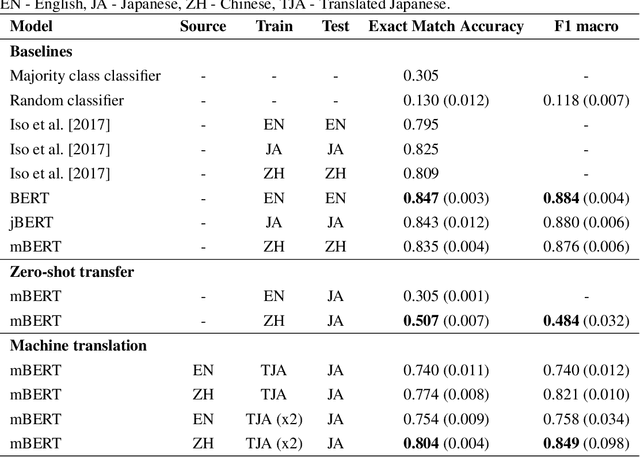
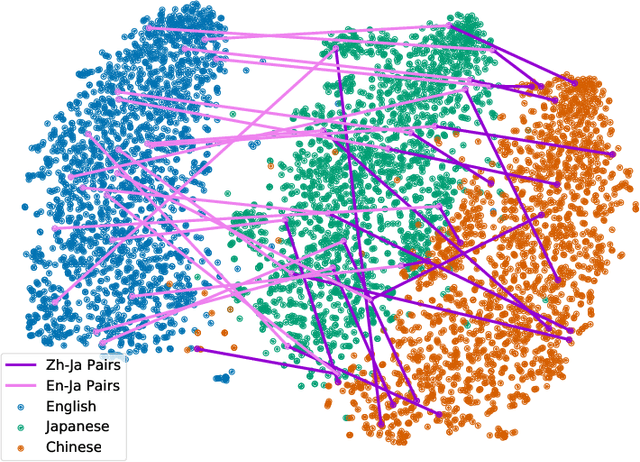
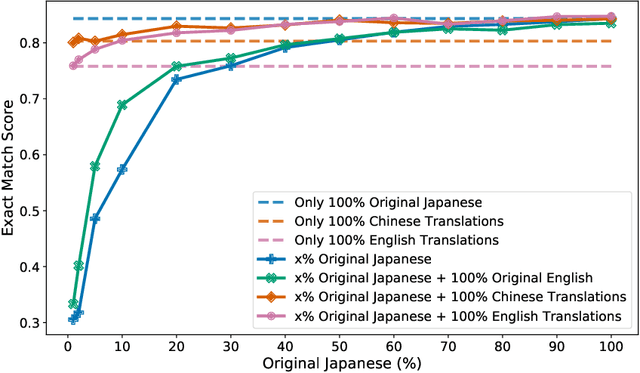
Statements on social media can be analysed to identify individuals who are experiencing red flag medical symptoms, allowing early detection of the spread of disease such as influenza. Since disease does not respect cultural borders and may spread between populations speaking different languages, we would like to build multilingual models. However, the data required to train models for every language may be difficult, expensive and time-consuming to obtain, particularly for low-resource languages. Taking Japanese as our target language, we explore methods by which data in one language might be used to build models for a different language. We evaluate strategies of training on machine translated data and of zero-shot transfer through the use of multilingual models. We find that the choice of source language impacts the performance, with Chinese-Japanese being a better language pair than English-Japanese. Training on machine translated data shows promise, especially when used in conjunction with a small amount of target language data.