 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Transfer for Early Warning of Epidemics from Social Media
Oct 10, 2019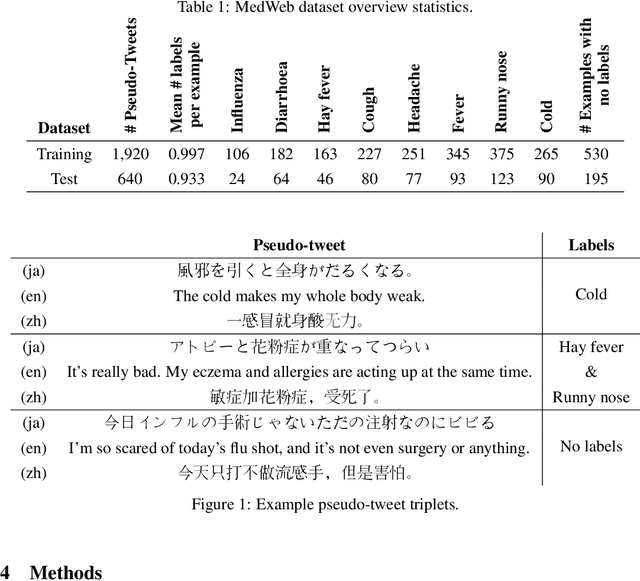
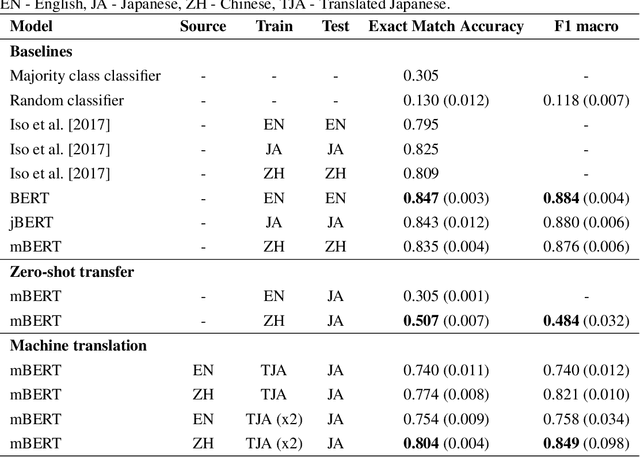
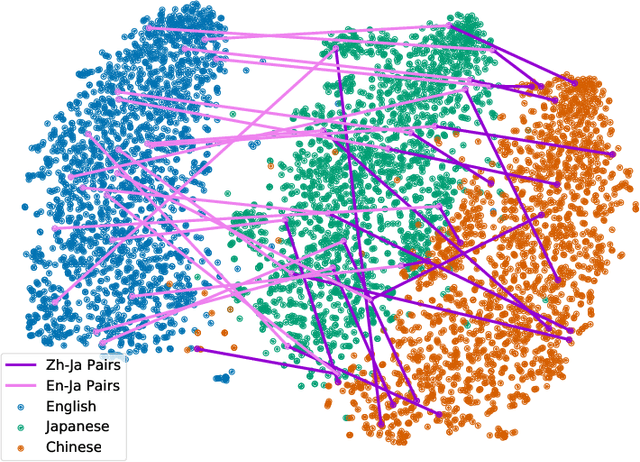
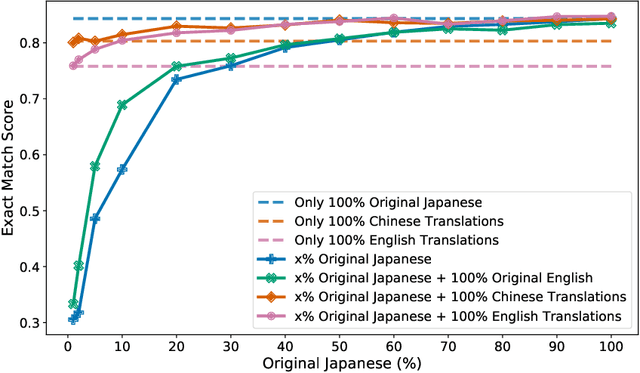
Statements on social media can be analysed to identify individuals who are experiencing red flag medical symptoms, allowing early detection of the spread of disease such as influenza. Since disease does not respect cultural borders and may spread between populations speaking different languages, we would like to build multilingual models. However, the data required to train models for every language may be difficult, expensive and time-consuming to obtain, particularly for low-resource languages. Taking Japanese as our target language, we explore methods by which data in one language might be used to build models for a different language. We evaluate strategies of training on machine translated data and of zero-shot transfer through the use of multilingual models. We find that the choice of source language impacts the performance, with Chinese-Japanese being a better language pair than English-Japanese. Training on machine translated data shows promise, especially when used in conjunction with a small amount of target language data.