 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGIFT: Global stabilisation via Intrinsic Fine Tuning
Apr 25, 2026Deep reinforcement learning policies achieve strong performance in complex continuous control environments with nonlinear contact forces. However, these policies often produce chaotic state dynamics, with trivially small changes to the initial conditions significantly impacting the long-term behaviour of the control system. This high sensitivity to initial conditions limits the application of Deep RL to real-world control systems where performance and stability guarantees are often required. To address this issue, we propose Global stabilisation via Intrinsic Fine Tuning (GIFT), a general-purpose training framework which directly optimises the global stability of existing high-performing deep RL policies using a custom reward function. We demonstrate that GIFT increase the stability of the control interaction while maintaining comparable task performance, thereby improving the suitability of deep RL policies for real-world control systems.
Modeling 3D Pedestrian-Vehicle Interactions for Vehicle-Conditioned Pose Forecasting
Feb 09, 2026Accurately predicting pedestrian motion is crucial for safe and reliable autonomous driving in complex urban environments. In this work, we present a 3D vehicle-conditioned pedestrian pose forecasting framework that explicitly incorporates surrounding vehicle information. To support this, we enhance the Waymo-3DSkelMo dataset with aligned 3D vehicle bounding boxes, enabling realistic modeling of multi-agent pedestrian-vehicle interactions. We introduce a sampling scheme to categorize scenes by pedestrian and vehicle count, facilitating training across varying interaction complexities. Our proposed network adapts the TBIFormer architecture with a dedicated vehicle encoder and pedestrian-vehicle interaction cross-attention module to fuse pedestrian and vehicle features, allowing predictions to be conditioned on both historical pedestrian motion and surrounding vehicles. Extensive experiments demonstrate substantial improvements in forecasting accuracy and validate different approaches for modeling pedestrian-vehicle interactions, highlighting the importance of vehicle-aware 3D pose prediction for autonomous driving. Code is available at: https://github.com/GuangxunZhu/VehCondPose3D
Splat-Portrait: Generalizing Talking Heads with Gaussian Splatting
Jan 26, 2026Talking Head Generation aims at synthesizing natural-looking talking videos from speech and a single portrait image. Previous 3D talking head generation methods have relied on domain-specific heuristics such as warping-based facial motion representation priors to animate talking motions, yet still produce inaccurate 3D avatar reconstructions, thus undermining the realism of generated animations. We introduce Splat-Portrait, a Gaussian-splatting-based method that addresses the challenges of 3D head reconstruction and lip motion synthesis. Our approach automatically learns to disentangle a single portrait image into a static 3D reconstruction represented as static Gaussian Splatting, and a predicted whole-image 2D background. It then generates natural lip motion conditioned on input audio, without any motion driven priors. Training is driven purely by 2D reconstruction and score-distillation losses, without 3D supervision nor landmarks. Experimental results demonstrate that Splat-Portrait exhibits superior performance on talking head generation and novel view synthesis, achieving better visual quality compared to previous works. Our project code and supplementary documents are public available at https://github.com/stonewalking/Splat-portrait.
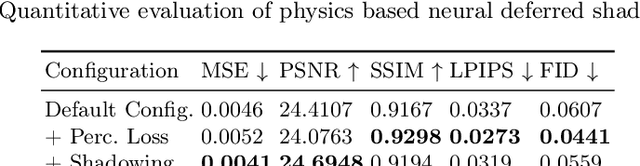
A Convolutional Neural Deferred Shader for Physics Based Rendering
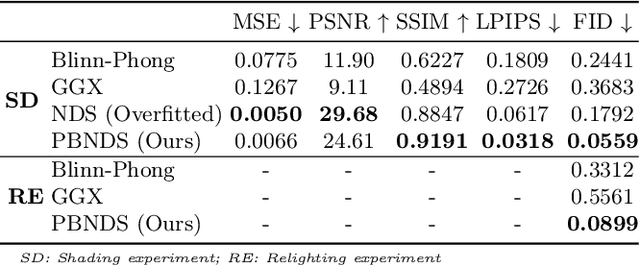
Dec 22, 2025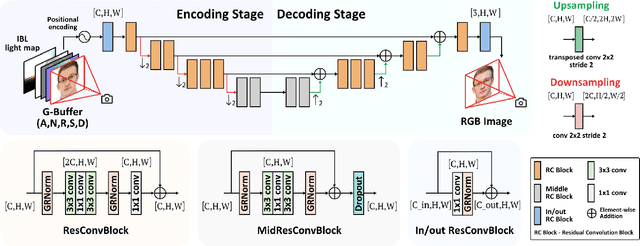
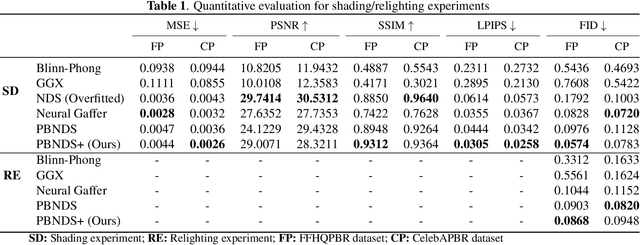


Recent advances in neural rendering have achieved impressive results on photorealistic shading and relighting, by using a multilayer perceptron (MLP) as a regression model to learn the rendering equation from a real-world dataset. Such methods show promise for photorealistically relighting real-world objects, which is difficult to classical rendering, as there is no easy-obtained material ground truth. However, significant challenges still remain the dense connections in MLPs result in a large number of parameters, which requires high computation resources, complicating the training, and reducing performance during rendering. Data driven approaches require large amounts of training data for generalization; unbalanced data might bias the model to ignore the unusual illumination conditions, e.g. dark scenes. This paper introduces pbnds+: a novel physics-based neural deferred shading pipeline utilizing convolution neural networks to decrease the parameters and improve the performance in shading and relighting tasks; Energy regularization is also proposed to restrict the model reflection during dark illumination. Extensive experiments demonstrate that our approach outperforms classical baselines, a state-of-the-art neural shading model, and a diffusion-based method.
FedQuad: Federated Stochastic Quadruplet Learning to Mitigate Data Heterogeneity
Sep 04, 2025Federated Learning (FL) provides decentralised model training, which effectively tackles problems such as distributed data and privacy preservation. However, the generalisation of global models frequently faces challenges from data heterogeneity among clients. This challenge becomes even more pronounced when datasets are limited in size and class imbalance. To address data heterogeneity, we propose a novel method, \textit{FedQuad}, that explicitly optimises smaller intra-class variance and larger inter-class variance across clients, thereby decreasing the negative impact of model aggregation on the global model over client representations. Our approach minimises the distance between similar pairs while maximising the distance between negative pairs, effectively disentangling client data in the shared feature space. We evaluate our method on the CIFAR-10 and CIFAR-100 datasets under various data distributions and with many clients, demonstrating superior performance compared to existing approaches. Furthermore, we provide a detailed analysis of metric learning-based strategies within both supervised and federated learning paradigms, highlighting their efficacy in addressing representational learning challenges in federated settings.
Generative Fields: Uncovering Hierarchical Feature Control for StyleGAN via Inverted Receptive Fields
Apr 24, 2025StyleGAN has demonstrated the ability of GANs to synthesize highly-realistic faces of imaginary people from random noise. One limitation of GAN-based image generation is the difficulty of controlling the features of the generated image, due to the strong entanglement of the low-dimensional latent space. Previous work that aimed to control StyleGAN with image or text prompts modulated sampling in W latent space, which is more expressive than Z latent space. However, W space still has restricted expressivity since it does not control the feature synthesis directly; also the feature embedding in W space requires a pre-training process to reconstruct the style signal, limiting its application. This paper introduces the concept of "generative fields" to explain the hierarchical feature synthesis in StyleGAN, inspired by the receptive fields of convolution neural networks (CNNs). Additionally, we propose a new image editing pipeline for StyleGAN using generative field theory and the channel-wise style latent space S, utilizing the intrinsic structural feature of CNNs to achieve disentangled control of feature synthesis at synthesis time.
Beyond Reconstruction: A Physics Based Neural Deferred Shader for Photo-realistic Rendering
Apr 16, 2025
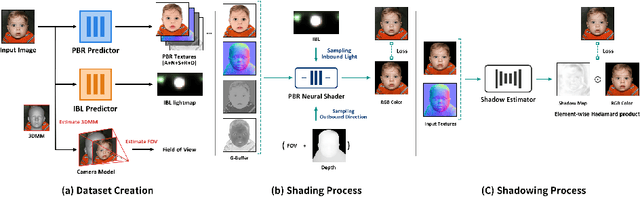
Deep learning based rendering has demonstrated major improvements for photo-realistic image synthesis, applicable to various applications including visual effects in movies and photo-realistic scene building in video games. However, a significant limitation is the difficulty of decomposing the illumination and material parameters, which limits such methods to reconstruct an input scene, without any possibility to control these parameters. This paper introduces a novel physics based neural deferred shading pipeline to decompose the data-driven rendering process, learn a generalizable shading function to produce photo-realistic results for shading and relighting tasks, we also provide a shadow estimator to efficiently mimic shadowing effect. Our model achieves improved performance compared to classical models and a state-of-art neural shading model, and enables generalizable photo-realistic shading from arbitrary illumination input.
On the Benefits of Instance Decomposition in Video Prediction Models
Jan 17, 2025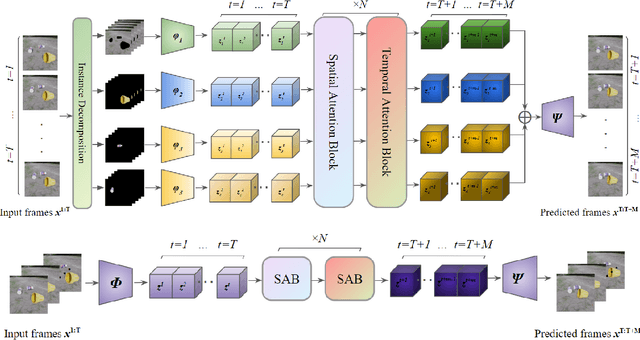
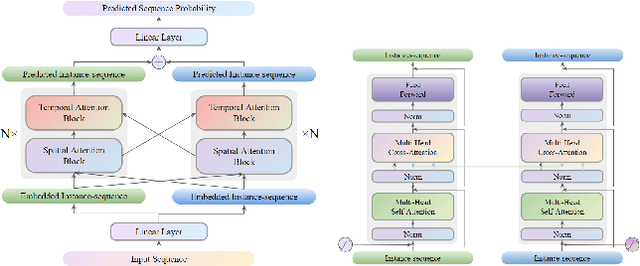
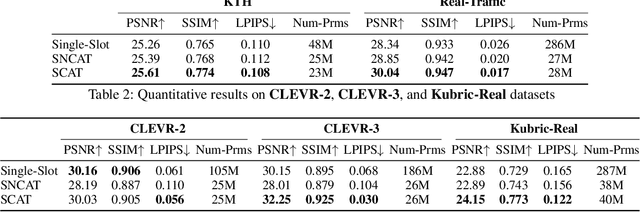

Video prediction is a crucial task for intelligent agents such as robots and autonomous vehicles, since it enables them to anticipate and act early on time-critical incidents. State-of-the-art video prediction methods typically model the dynamics of a scene jointly and implicitly, without any explicit decomposition into separate objects. This is challenging and potentially sub-optimal, as every object in a dynamic scene has their own pattern of movement, typically somewhat independent of others. In this paper, we investigate the benefit of explicitly modeling the objects in a dynamic scene separately within the context of latent-transformer video prediction models. We conduct detailed and carefully-controlled experiments on both synthetic and real-world datasets; our results show that decomposing a dynamic scene leads to higher quality predictions compared with models of a similar capacity that lack such decomposition.
Robust Federated Learning in the Face of Covariate Shift: A Magnitude Pruning with Hybrid Regularization Framework for Enhanced Model Aggregation
Dec 19, 2024



The development of highly sophisticated neural networks has allowed for fast progress in every field of computer vision, however, applications where annotated data is prohibited due to privacy or security concerns remain challenging. Federated Learning (FL) offers a promising framework for individuals aiming to collaboratively develop a shared model while preserving data privacy. Nevertheless, our findings reveal that variations in data distribution among clients can profoundly affect FL methodologies, primarily due to instabilities in the aggregation process. We also propose a novel FL framework to mitigate the adverse effects of covariate shifts among federated clients by combining individual parameter pruning and regularization techniques to improve the robustness of individual clients' models to aggregate. Each client's model is optimized through magnitude-based pruning and the addition of dropout and noise injection layers to build more resilient decision pathways in the networks and improve the robustness of the model's parameter aggregation step. The proposed framework is capable of extracting robust representations even in the presence of very large covariate shifts among client data distributions and in the federation of a small number of clients. Empirical findings substantiate the effectiveness of our proposed methodology across common benchmark datasets, including CIFAR10, MNIST, SVHN, and Fashion MNIST. Furthermore, we introduce the CelebA-Gender dataset, specifically designed to evaluate performance on a more realistic domain. The proposed method is capable of extracting robust representations even in the presence of both high and low covariate shifts among client data distributions.
Enhancing Robustness in Deep Reinforcement Learning: A Lyapunov Exponent Approach
Oct 14, 2024Deep reinforcement learning agents achieve state-of-the-art performance in a wide range of simulated control tasks. However, successful applications to real-world problems remain limited. One reason for this dichotomy is because the learned policies are not robust to observation noise or adversarial attacks. In this paper, we investigate the robustness of deep RL policies to a single small state perturbation in deterministic continuous control tasks. We demonstrate that RL policies can be deterministically chaotic as small perturbations to the system state have a large impact on subsequent state and reward trajectories. This unstable non-linear behaviour has two consequences: First, inaccuracies in sensor readings, or adversarial attacks, can cause significant performance degradation; Second, even policies that show robust performance in terms of rewards may have unpredictable behaviour in practice. These two facets of chaos in RL policies drastically restrict the application of deep RL to real-world problems. To address this issue, we propose an improvement on the successful Dreamer V3 architecture, implementing a Maximal Lyapunov Exponent regularisation. This new approach reduces the chaotic state dynamics, rendering the learnt policies more resilient to sensor noise or adversarial attacks and thereby improving the suitability of Deep Reinforcement Learning for real-world applications.