 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe role of noise in denoising models for anomaly detection in medical images
Jan 19, 2023



Pathological brain lesions exhibit diverse appearance in brain images, in terms of intensity, texture, shape, size, and location. Comprehensive sets of data and annotations are difficult to acquire. Therefore, unsupervised anomaly detection approaches have been proposed using only normal data for training, with the aim of detecting outlier anomalous voxels at test time. Denoising methods, for instance classical denoising autoencoders (DAEs) and more recently emerging diffusion models, are a promising approach, however naive application of pixelwise noise leads to poor anomaly detection performance. We show that optimization of the spatial resolution and magnitude of the noise improves the performance of different model training regimes, with similar noise parameter adjustments giving good performance for both DAEs and diffusion models. Visual inspection of the reconstructions suggests that the training noise influences the trade-off between the extent of the detail that is reconstructed and the extent of erasure of anomalies, both of which contribute to better anomaly detection performance. We validate our findings on two real-world datasets (tumor detection in brain MRI and hemorrhage/ischemia/tumor detection in brain CT), showing good detection on diverse anomaly appearances. Overall, we find that a DAE trained with coarse noise is a fast and simple method that gives state-of-the-art accuracy. Diffusion models applied to anomaly detection are as yet in their infancy and provide a promising avenue for further research.
Survey: Leakage and Privacy at Inference Time
Jul 04, 2021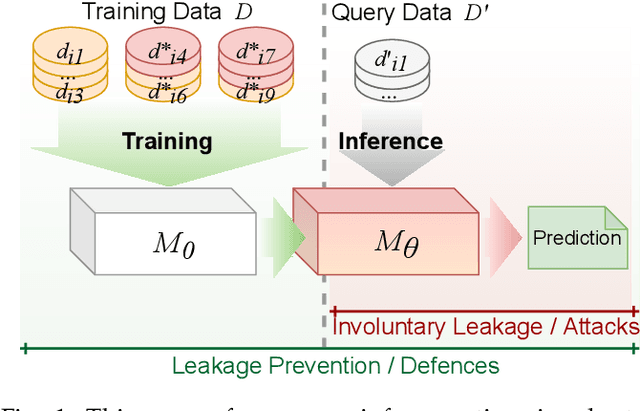
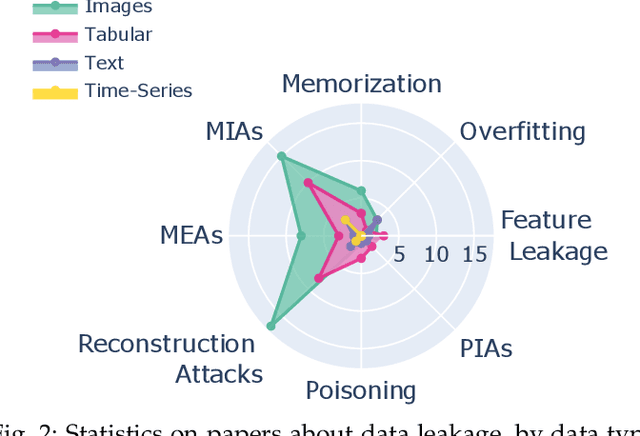
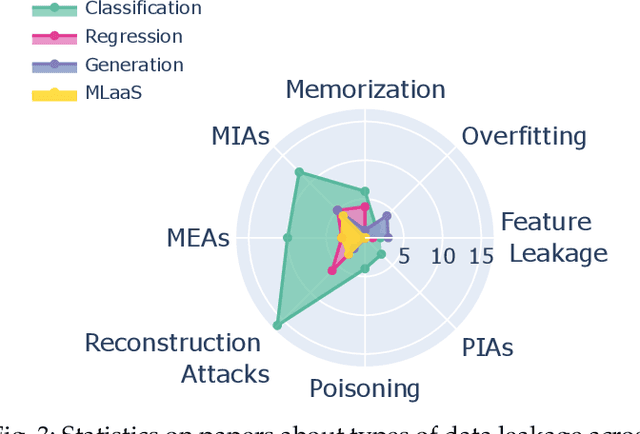
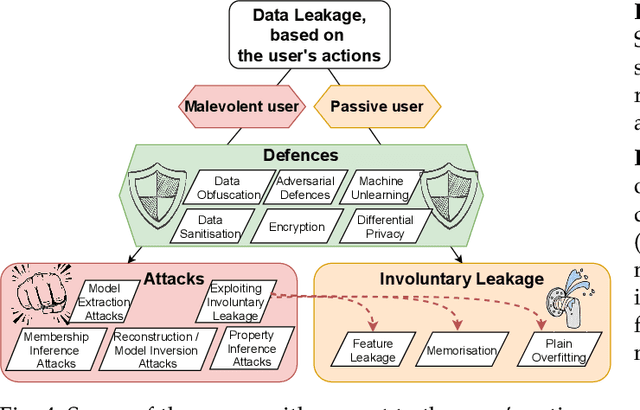
Leakage of data from publicly available Machine Learning (ML) models is an area of growing significance as commercial and government applications of ML can draw on multiple sources of data, potentially including users' and clients' sensitive data. We provide a comprehensive survey of contemporary advances on several fronts, covering involuntary data leakage which is natural to ML models, potential malevolent leakage which is caused by privacy attacks, and currently available defence mechanisms. We focus on inference-time leakage, as the most likely scenario for publicly available models. We first discuss what leakage is in the context of different data, tasks, and model architectures. We then propose a taxonomy across involuntary and malevolent leakage, available defences, followed by the currently available assessment metrics and applications. We conclude with outstanding challenges and open questions, outlining some promising directions for future research.