 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurvey: Leakage and Privacy at Inference Time
Paper and Code
Jul 04, 2021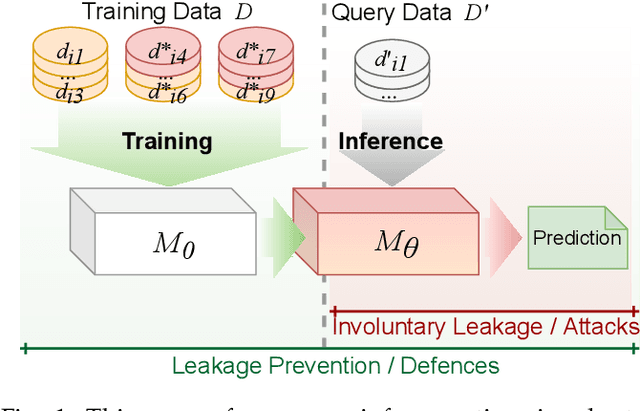
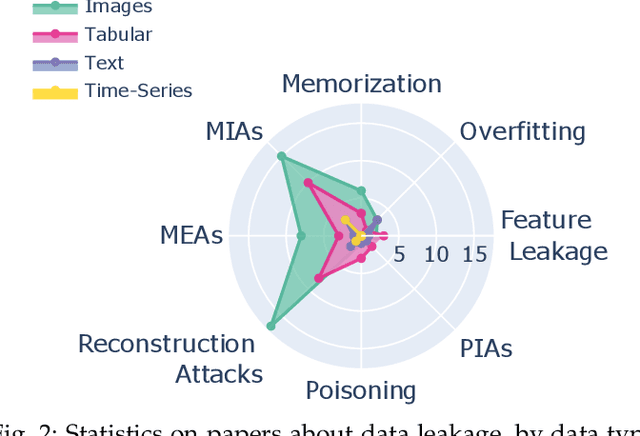
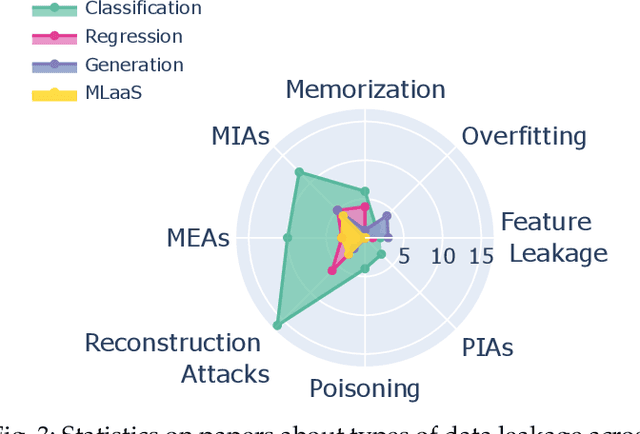
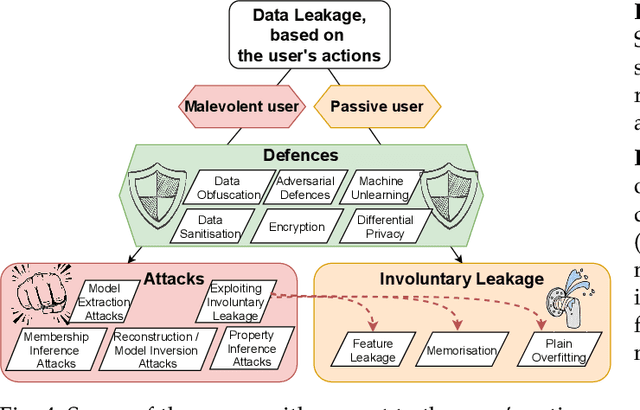
Leakage of data from publicly available Machine Learning (ML) models is an area of growing significance as commercial and government applications of ML can draw on multiple sources of data, potentially including users' and clients' sensitive data. We provide a comprehensive survey of contemporary advances on several fronts, covering involuntary data leakage which is natural to ML models, potential malevolent leakage which is caused by privacy attacks, and currently available defence mechanisms. We focus on inference-time leakage, as the most likely scenario for publicly available models. We first discuss what leakage is in the context of different data, tasks, and model architectures. We then propose a taxonomy across involuntary and malevolent leakage, available defences, followed by the currently available assessment metrics and applications. We conclude with outstanding challenges and open questions, outlining some promising directions for future research.