 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Controller Generalization with Dimensionless Markov Decision Processes
Apr 14, 2025



Controllers trained with Reinforcement Learning tend to be very specialized and thus generalize poorly when their testing environment differs from their training one. We propose a Model-Based approach to increase generalization where both world model and policy are trained in a dimensionless state-action space. To do so, we introduce the Dimensionless Markov Decision Process ($\Pi$-MDP): an extension of Contextual-MDPs in which state and action spaces are non-dimensionalized with the Buckingham-$\Pi$ theorem. This procedure induces policies that are equivariant with respect to changes in the context of the underlying dynamics. We provide a generic framework for this approach and apply it to a model-based policy search algorithm using Gaussian Process models. We demonstrate the applicability of our method on simulated actuated pendulum and cartpole systems, where policies trained on a single environment are robust to shifts in the distribution of the context.
Actively Inferring Optimal Measurement Sequences
Feb 25, 2025



Measurement of a physical quantity such as light intensity is an integral part of many reconstruction and decision scenarios but can be costly in terms of acquisition time, invasion of or damage to the environment and storage. Data minimisation and compliance with data protection laws is also an important consideration. Where there are a range of measurements that can be made, some may be more informative and compliant with the overall measurement objective than others. We develop an active sequential inference algorithm that uses the low dimensional representational latent space from a variational autoencoder (VAE) to choose which measurement to make next. Our aim is to recover high dimensional data by making as few measurements as possible. We adapt the VAE encoder to map partial data measurements on to the latent space of the complete data. The algorithm draws samples from this latent space and uses the VAE decoder to generate data conditional on the partial measurements. Estimated measurements are made on the generated data and fed back through the partial VAE encoder to the latent space where they can be evaluated prior to making a measurement. Starting from no measurements and a normal prior on the latent space, we consider alternative strategies for choosing the next measurement and updating the predictive posterior prior for the next step. The algorithm is illustrated using the Fashion MNIST dataset and a novel convolutional Hadamard pattern measurement basis. We see that useful patterns are chosen within 10 steps, leading to the convergence of the guiding generative images. Compared with using stochastic variational inference to infer the parameters of the posterior distribution for each generated data point individually, the partial VAE framework can efficiently process batches of generated data and obtains superior results with minimal measurements.
IGAF: Incremental Guided Attention Fusion for Depth Super-Resolution
Jan 03, 2025Accurate depth estimation is crucial for many fields, including robotics, navigation, and medical imaging. However, conventional depth sensors often produce low-resolution (LR) depth maps, making detailed scene perception challenging. To address this, enhancing LR depth maps to high-resolution (HR) ones has become essential, guided by HR-structured inputs like RGB or grayscale images. We propose a novel sensor fusion methodology for guided depth super-resolution (GDSR), a technique that combines LR depth maps with HR images to estimate detailed HR depth maps. Our key contribution is the Incremental guided attention fusion (IGAF) module, which effectively learns to fuse features from RGB images and LR depth maps, producing accurate HR depth maps. Using IGAF, we build a robust super-resolution model and evaluate it on multiple benchmark datasets. Our model achieves state-of-the-art results compared to all baseline models on the NYU v2 dataset for $\times 4$, $\times 8$, and $\times 16$ upsampling. It also outperforms all baselines in a zero-shot setting on the Middlebury, Lu, and RGB-D-D datasets. Code, environments, and models are available on GitHub.
Active Inference and Human--Computer Interaction
Dec 19, 2024



Active Inference is a closed-loop computational theoretical basis for understanding behaviour, based on agents with internal probabilistic generative models that encode their beliefs about how hidden states in their environment cause their sensations. We review Active Inference and how it could be applied to model the human-computer interaction loop. Active Inference provides a coherent framework for managing generative models of humans, their environments, sensors and interface components. It informs off-line design and supports real-time, online adaptation. It provides model-based explanations for behaviours observed in HCI, and new tools to measure important concepts such as agency and engagement. We discuss how Active Inference offers a new basis for a theory of interaction in HCI, tools for design of modern, complex sensor-based systems, and integration of artificial intelligence technologies, enabling it to cope with diversity in human users and contexts. We discuss the practical challenges in implementing such Active Inference-based systems.
HpEIS: Learning Hand Pose Embeddings for Multimedia Interactive Systems
Oct 11, 2024



We present a novel Hand-pose Embedding Interactive System (HpEIS) as a virtual sensor, which maps users' flexible hand poses to a two-dimensional visual space using a Variational Autoencoder (VAE) trained on a variety of hand poses. HpEIS enables visually interpretable and guidable support for user explorations in multimedia collections, using only a camera as an external hand pose acquisition device. We identify general usability issues associated with system stability and smoothing requirements through pilot experiments with expert and inexperienced users. We then design stability and smoothing improvements, including hand-pose data augmentation, an anti-jitter regularisation term added to loss function, stabilising post-processing for movement turning points and smoothing post-processing based on One Euro Filters. In target selection experiments (n=12), we evaluate HpEIS by measures of task completion time and the final distance to target points, with and without the gesture guidance window condition. Experimental responses indicate that HpEIS provides users with a learnable, flexible, stable and smooth mid-air hand movement interaction experience.
AI-Enabled sensor fusion of time of flight imaging and mmwave for concealed metal detection
Aug 01, 2024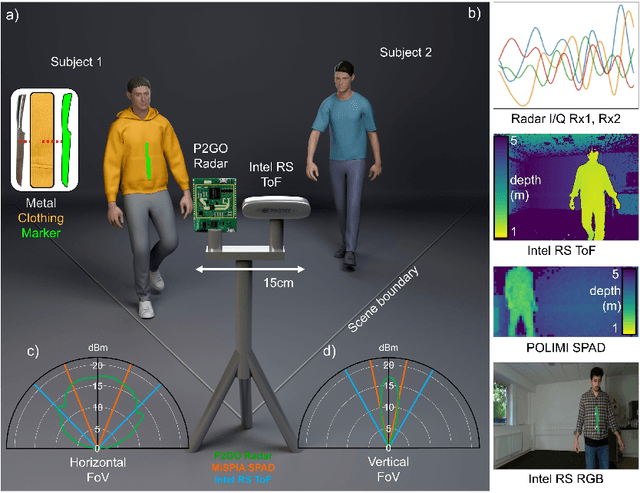
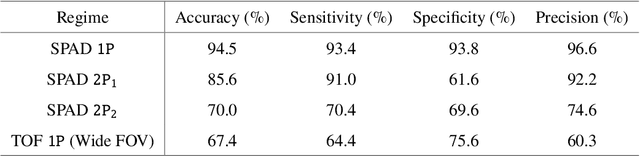
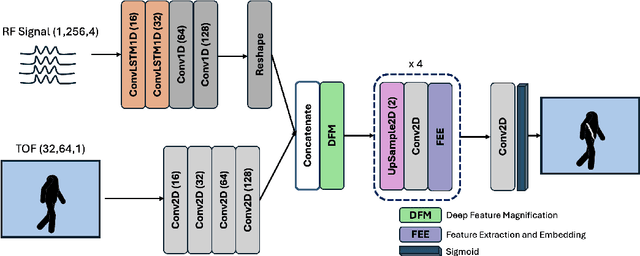

In the field of detection and ranging, multiple complementary sensing modalities may be used to enrich the information obtained from a dynamic scene. One application of this sensor fusion is in public security and surveillance, whose efficacy and privacy protection measures must be continually evaluated. We present a novel deployment of sensor fusion for the discrete detection of concealed metal objects on persons whilst preserving their privacy. This is achieved by coupling off-the-shelf mmWave radar and depth camera technology with a novel neural network architecture that processes the radar signals using convolutional Long Short-term Memory (LSTM) blocks and the depth signal, using convolutional operations. The combined latent features are then magnified using a deep feature magnification to learn cross-modality dependencies in the data. We further propose a decoder, based on the feature extraction and embedding block, to learn an efficient upsampling of the latent space to learn the location of the concealed object in the spatial domain through radar feature guidance. We demonstrate the detection of presence and inference of 3D location of concealed metal objects with an accuracy of up to 95%, using a technique that is robust to multiple persons. This work provides a demonstration of the potential for cost effective and portable sensor fusion, with strong opportunities for further development.
Is One GPU Enough? Pushing Image Generation at Higher-Resolutions with Foundation Models
Jun 12, 2024



In this work, we introduce Pixelsmith, a zero-shot text-to-image generative framework to sample images at higher resolutions with a single GPU. We are the first to show that it is possible to scale the output of a pre-trained diffusion model by a factor of 1000, opening the road for gigapixel image generation at no additional cost. Our cascading method uses the image generated at the lowest resolution as a baseline to sample at higher resolutions. For the guidance, we introduce the Slider, a tunable mechanism that fuses the overall structure contained in the first-generated image with enhanced fine details. At each inference step, we denoise patches rather than the entire latent space, minimizing memory demands such that a single GPU can handle the process, regardless of the image's resolution. Our experimental results show that Pixelsmith not only achieves higher quality and diversity compared to existing techniques, but also reduces sampling time and artifacts. The code for our work is available at https://github.com/Thanos-DB/Pixelsmith.
GLFNET: Global-Local (frequency) Filter Networks for efficient medical image segmentation
Mar 01, 2024



We propose a novel transformer-style architecture called Global-Local Filter Network (GLFNet) for medical image segmentation and demonstrate its state-of-the-art performance. We replace the self-attention mechanism with a combination of global-local filter blocks to optimize model efficiency. The global filters extract features from the whole feature map whereas the local filters are being adaptively created as 4x4 patches of the same feature map and add restricted scale information. In particular, the feature extraction takes place in the frequency domain rather than the commonly used spatial (image) domain to facilitate faster computations. The fusion of information from both spatial and frequency spaces creates an efficient model with regards to complexity, required data and performance. We test GLFNet on three benchmark datasets achieving state-of-the-art performance on all of them while being almost twice as efficient in terms of GFLOP operations.
Generative Fractional Diffusion Models
Oct 26, 2023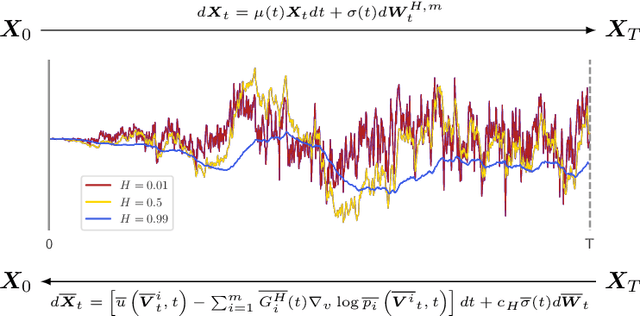

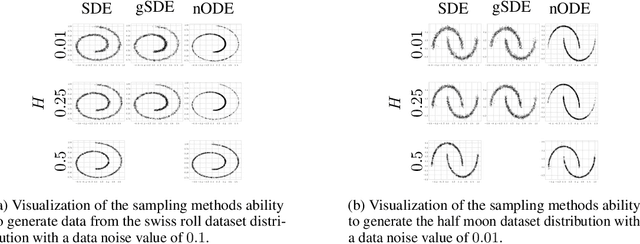

We generalize the continuous time framework for score-based generative models from an underlying Brownian motion (BM) to an approximation of fractional Brownian motion (FBM). We derive a continuous reparameterization trick and the reverse time model by representing FBM as a stochastic integral over a family of Ornstein-Uhlenbeck processes to define generative fractional diffusion models (GFDM) with driving noise converging to a non-Markovian process of infinite quadratic variation. The Hurst index $H\in(0,1)$ of FBM enables control of the roughness of the distribution transforming path. To the best of our knowledge, this is the first attempt to build a generative model upon a stochastic process with infinite quadratic variation.
DiffInfinite: Large Mask-Image Synthesis via Parallel Random Patch Diffusion in Histopathology
Jun 23, 2023



We present DiffInfinite, a hierarchical diffusion model that generates arbitrarily large histological images while preserving long-range correlation structural information. Our approach first generates synthetic segmentation masks, subsequently used as conditions for the high-fidelity generative diffusion process. The proposed sampling method can be scaled up to any desired image size while only requiring small patches for fast training. Moreover, it can be parallelized more efficiently than previous large-content generation methods while avoiding tiling artefacts. The training leverages classifier-free guidance to augment a small, sparsely annotated dataset with unlabelled data. Our method alleviates unique challenges in histopathological imaging practice: large-scale information, costly manual annotation, and protective data handling. The biological plausibility of DiffInfinite data is validated in a survey by ten experienced pathologists as well as a downstream segmentation task. Furthermore, the model scores strongly on anti-copying metrics which is beneficial for the protection of patient data.