 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSplat-Portrait: Generalizing Talking Heads with Gaussian Splatting
Jan 26, 2026Talking Head Generation aims at synthesizing natural-looking talking videos from speech and a single portrait image. Previous 3D talking head generation methods have relied on domain-specific heuristics such as warping-based facial motion representation priors to animate talking motions, yet still produce inaccurate 3D avatar reconstructions, thus undermining the realism of generated animations. We introduce Splat-Portrait, a Gaussian-splatting-based method that addresses the challenges of 3D head reconstruction and lip motion synthesis. Our approach automatically learns to disentangle a single portrait image into a static 3D reconstruction represented as static Gaussian Splatting, and a predicted whole-image 2D background. It then generates natural lip motion conditioned on input audio, without any motion driven priors. Training is driven purely by 2D reconstruction and score-distillation losses, without 3D supervision nor landmarks. Experimental results demonstrate that Splat-Portrait exhibits superior performance on talking head generation and novel view synthesis, achieving better visual quality compared to previous works. Our project code and supplementary documents are public available at https://github.com/stonewalking/Splat-portrait.
Pixel-to-4D: Camera-Controlled Image-to-Video Generation with Dynamic 3D Gaussians
Jan 02, 2026Humans excel at forecasting the future dynamics of a scene given just a single image. Video generation models that can mimic this ability are an essential component for intelligent systems. Recent approaches have improved temporal coherence and 3D consistency in single-image-conditioned video generation. However, these methods often lack robust user controllability, such as modifying the camera path, limiting their applicability in real-world applications. Most existing camera-controlled image-to-video models struggle with accurately modeling camera motion, maintaining temporal consistency, and preserving geometric integrity. Leveraging explicit intermediate 3D representations offers a promising solution by enabling coherent video generation aligned with a given camera trajectory. Although these methods often use 3D point clouds to render scenes and introduce object motion in a later stage, this two-step process still falls short in achieving full temporal consistency, despite allowing precise control over camera movement. We propose a novel framework that constructs a 3D Gaussian scene representation and samples plausible object motion, given a single image in a single forward pass. This enables fast, camera-guided video generation without the need for iterative denoising to inject object motion into render frames. Extensive experiments on the KITTI, Waymo, RealEstate10K and DL3DV-10K datasets demonstrate that our method achieves state-of-the-art video quality and inference efficiency. The project page is available at https://melonienimasha.github.io/Pixel-to-4D-Website.
Unsupervised Segmentation by Diffusing, Walking and Cutting
Dec 06, 2024We propose an unsupervised image segmentation method using features from pre-trained text-to-image diffusion models. Inspired by classic spectral clustering approaches, we construct adjacency matrices from self-attention layers between image patches and recursively partition using Normalised Cuts. A key insight is that self-attention probability distributions, which capture semantic relations between patches, can be interpreted as a transition matrix for random walks across the image. We leverage this by first using Random Walk Normalized Cuts directly on these self-attention activations to partition the image, minimizing transition probabilities between clusters while maximizing coherence within clusters. Applied recursively, this yields a hierarchical segmentation that reflects the rich semantics in the pre-trained attention layers, without any additional training. Next, we explore other ways to build the NCuts adjacency matrix from features, and how we can use the random walk interpretation of self-attention to capture long-range relationships. Finally, we propose an approach to automatically determine the NCut cost criterion, avoiding the need to tune this manually. We quantitatively analyse the effect incorporating different features, a constant versus dynamic NCut threshold, and incorporating multi-node paths when constructing the NCuts adjacency matrix. We show that our approach surpasses all existing methods for zero-shot unsupervised segmentation, achieving state-of-the-art results on COCO-Stuff-27 and Cityscapes.
ARTeFACT: Benchmarking Segmentation Models on Diverse Analogue Media Damage
Dec 05, 2024



Accurately detecting and classifying damage in analogue media such as paintings, photographs, textiles, mosaics, and frescoes is essential for cultural heritage preservation. While machine learning models excel in correcting degradation if the damage operator is known a priori, we show that they fail to robustly predict where the damage is even after supervised training; thus, reliable damage detection remains a challenge. Motivated by this, we introduce ARTeFACT, a dataset for damage detection in diverse types analogue media, with over 11,000 annotations covering 15 kinds of damage across various subjects, media, and historical provenance. Furthermore, we contribute human-verified text prompts describing the semantic contents of the images, and derive additional textual descriptions of the annotated damage. We evaluate CNN, Transformer, diffusion-based segmentation models, and foundation vision models in zero-shot, supervised, unsupervised and text-guided settings, revealing their limitations in generalising across media types. Our dataset is available at $\href{https://daniela997.github.io/ARTeFACT/}{https://daniela997.github.io/ARTeFACT/}$ as the first-of-its-kind benchmark for analogue media damage detection and restoration.
State-of-the-Art Fails in the Art of Damage Detection
Aug 23, 2024


Accurately detecting and classifying damage in analogue media such as paintings, photographs, textiles, mosaics, and frescoes is essential for cultural heritage preservation. While machine learning models excel in correcting global degradation if the damage operator is known a priori, we show that they fail to predict where the damage is even after supervised training; thus, reliable damage detection remains a challenge. We introduce DamBench, a dataset for damage detection in diverse analogue media, with over 11,000 annotations covering 15 damage types across various subjects and media. We evaluate CNN, Transformer, and text-guided diffusion segmentation models, revealing their limitations in generalising across media types.
Sampling 3D Gaussian Scenes in Seconds with Latent Diffusion Models
Jun 18, 2024

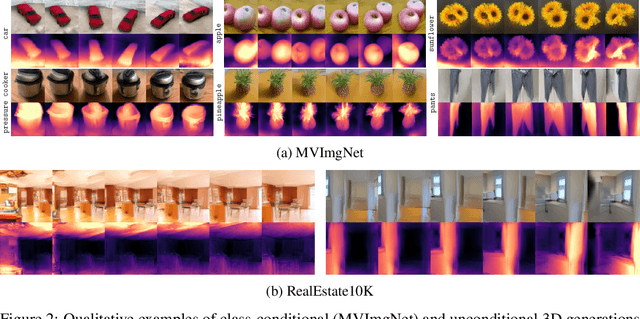
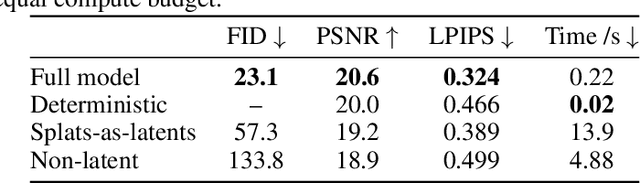
We present a latent diffusion model over 3D scenes, that can be trained using only 2D image data. To achieve this, we first design an autoencoder that maps multi-view images to 3D Gaussian splats, and simultaneously builds a compressed latent representation of these splats. Then, we train a multi-view diffusion model over the latent space to learn an efficient generative model. This pipeline does not require object masks nor depths, and is suitable for complex scenes with arbitrary camera positions. We conduct careful experiments on two large-scale datasets of complex real-world scenes -- MVImgNet and RealEstate10K. We show that our approach enables generating 3D scenes in as little as 0.2 seconds, either from scratch, from a single input view, or from sparse input views. It produces diverse and high-quality results while running an order of magnitude faster than non-latent diffusion models and earlier NeRF-based generative models
DiffInfinite: Large Mask-Image Synthesis via Parallel Random Patch Diffusion in Histopathology
Jun 23, 2023



We present DiffInfinite, a hierarchical diffusion model that generates arbitrarily large histological images while preserving long-range correlation structural information. Our approach first generates synthetic segmentation masks, subsequently used as conditions for the high-fidelity generative diffusion process. The proposed sampling method can be scaled up to any desired image size while only requiring small patches for fast training. Moreover, it can be parallelized more efficiently than previous large-content generation methods while avoiding tiling artefacts. The training leverages classifier-free guidance to augment a small, sparsely annotated dataset with unlabelled data. Our method alleviates unique challenges in histopathological imaging practice: large-scale information, costly manual annotation, and protective data handling. The biological plausibility of DiffInfinite data is validated in a survey by ten experienced pathologists as well as a downstream segmentation task. Furthermore, the model scores strongly on anti-copying metrics which is beneficial for the protection of patient data.
Simulating analogue film damage to analyse and improve artefact restoration on high-resolution scans
Feb 20, 2023Digital scans of analogue photographic film typically contain artefacts such as dust and scratches. Automated removal of these is an important part of preservation and dissemination of photographs of historical and cultural importance. While state-of-the-art deep learning models have shown impressive results in general image inpainting and denoising, film artefact removal is an understudied problem. It has particularly challenging requirements, due to the complex nature of analogue damage, the high resolution of film scans, and potential ambiguities in the restoration. There are no publicly available high-quality datasets of real-world analogue film damage for training and evaluation, making quantitative studies impossible. We address the lack of ground-truth data for evaluation by collecting a dataset of 4K damaged analogue film scans paired with manually-restored versions produced by a human expert, allowing quantitative evaluation of restoration performance. We construct a larger synthetic dataset of damaged images with paired clean versions using a statistical model of artefact shape and occurrence learnt from real, heavily-damaged images. We carefully validate the realism of the simulated damage via a human perceptual study, showing that even expert users find our synthetic damage indistinguishable from real. In addition, we demonstrate that training with our synthetically damaged dataset leads to improved artefact segmentation performance when compared to previously proposed synthetic analogue damage. Finally, we use these datasets to train and analyse the performance of eight state-of-the-art image restoration methods on high-resolution scans. We compare both methods which directly perform the restoration task on scans with artefacts, and methods which require a damage mask to be provided for the inpainting of artefacts.