 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSplat-Portrait: Generalizing Talking Heads with Gaussian Splatting
Jan 26, 2026Talking Head Generation aims at synthesizing natural-looking talking videos from speech and a single portrait image. Previous 3D talking head generation methods have relied on domain-specific heuristics such as warping-based facial motion representation priors to animate talking motions, yet still produce inaccurate 3D avatar reconstructions, thus undermining the realism of generated animations. We introduce Splat-Portrait, a Gaussian-splatting-based method that addresses the challenges of 3D head reconstruction and lip motion synthesis. Our approach automatically learns to disentangle a single portrait image into a static 3D reconstruction represented as static Gaussian Splatting, and a predicted whole-image 2D background. It then generates natural lip motion conditioned on input audio, without any motion driven priors. Training is driven purely by 2D reconstruction and score-distillation losses, without 3D supervision nor landmarks. Experimental results demonstrate that Splat-Portrait exhibits superior performance on talking head generation and novel view synthesis, achieving better visual quality compared to previous works. Our project code and supplementary documents are public available at https://github.com/stonewalking/Splat-portrait.
Pixel-to-4D: Camera-Controlled Image-to-Video Generation with Dynamic 3D Gaussians
Jan 02, 2026Humans excel at forecasting the future dynamics of a scene given just a single image. Video generation models that can mimic this ability are an essential component for intelligent systems. Recent approaches have improved temporal coherence and 3D consistency in single-image-conditioned video generation. However, these methods often lack robust user controllability, such as modifying the camera path, limiting their applicability in real-world applications. Most existing camera-controlled image-to-video models struggle with accurately modeling camera motion, maintaining temporal consistency, and preserving geometric integrity. Leveraging explicit intermediate 3D representations offers a promising solution by enabling coherent video generation aligned with a given camera trajectory. Although these methods often use 3D point clouds to render scenes and introduce object motion in a later stage, this two-step process still falls short in achieving full temporal consistency, despite allowing precise control over camera movement. We propose a novel framework that constructs a 3D Gaussian scene representation and samples plausible object motion, given a single image in a single forward pass. This enables fast, camera-guided video generation without the need for iterative denoising to inject object motion into render frames. Extensive experiments on the KITTI, Waymo, RealEstate10K and DL3DV-10K datasets demonstrate that our method achieves state-of-the-art video quality and inference efficiency. The project page is available at https://melonienimasha.github.io/Pixel-to-4D-Website.
Sampling 3D Gaussian Scenes in Seconds with Latent Diffusion Models
Jun 18, 2024

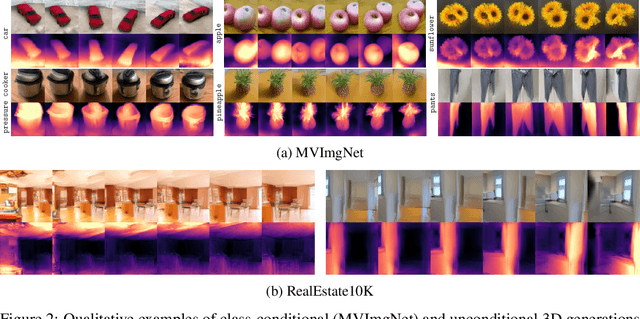
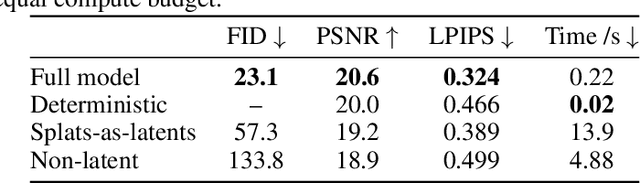
We present a latent diffusion model over 3D scenes, that can be trained using only 2D image data. To achieve this, we first design an autoencoder that maps multi-view images to 3D Gaussian splats, and simultaneously builds a compressed latent representation of these splats. Then, we train a multi-view diffusion model over the latent space to learn an efficient generative model. This pipeline does not require object masks nor depths, and is suitable for complex scenes with arbitrary camera positions. We conduct careful experiments on two large-scale datasets of complex real-world scenes -- MVImgNet and RealEstate10K. We show that our approach enables generating 3D scenes in as little as 0.2 seconds, either from scratch, from a single input view, or from sparse input views. It produces diverse and high-quality results while running an order of magnitude faster than non-latent diffusion models and earlier NeRF-based generative models