 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePixel-to-4D: Camera-Controlled Image-to-Video Generation with Dynamic 3D Gaussians
Jan 02, 2026Humans excel at forecasting the future dynamics of a scene given just a single image. Video generation models that can mimic this ability are an essential component for intelligent systems. Recent approaches have improved temporal coherence and 3D consistency in single-image-conditioned video generation. However, these methods often lack robust user controllability, such as modifying the camera path, limiting their applicability in real-world applications. Most existing camera-controlled image-to-video models struggle with accurately modeling camera motion, maintaining temporal consistency, and preserving geometric integrity. Leveraging explicit intermediate 3D representations offers a promising solution by enabling coherent video generation aligned with a given camera trajectory. Although these methods often use 3D point clouds to render scenes and introduce object motion in a later stage, this two-step process still falls short in achieving full temporal consistency, despite allowing precise control over camera movement. We propose a novel framework that constructs a 3D Gaussian scene representation and samples plausible object motion, given a single image in a single forward pass. This enables fast, camera-guided video generation without the need for iterative denoising to inject object motion into render frames. Extensive experiments on the KITTI, Waymo, RealEstate10K and DL3DV-10K datasets demonstrate that our method achieves state-of-the-art video quality and inference efficiency. The project page is available at https://melonienimasha.github.io/Pixel-to-4D-Website.
Active Inference and Human--Computer Interaction
Dec 19, 2024



Active Inference is a closed-loop computational theoretical basis for understanding behaviour, based on agents with internal probabilistic generative models that encode their beliefs about how hidden states in their environment cause their sensations. We review Active Inference and how it could be applied to model the human-computer interaction loop. Active Inference provides a coherent framework for managing generative models of humans, their environments, sensors and interface components. It informs off-line design and supports real-time, online adaptation. It provides model-based explanations for behaviours observed in HCI, and new tools to measure important concepts such as agency and engagement. We discuss how Active Inference offers a new basis for a theory of interaction in HCI, tools for design of modern, complex sensor-based systems, and integration of artificial intelligence technologies, enabling it to cope with diversity in human users and contexts. We discuss the practical challenges in implementing such Active Inference-based systems.
Evaluating Bayesian Model Visualisations
Jan 10, 2022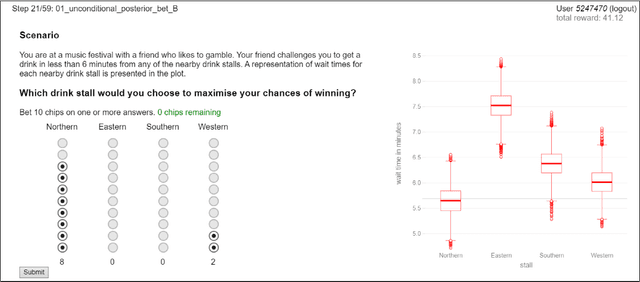


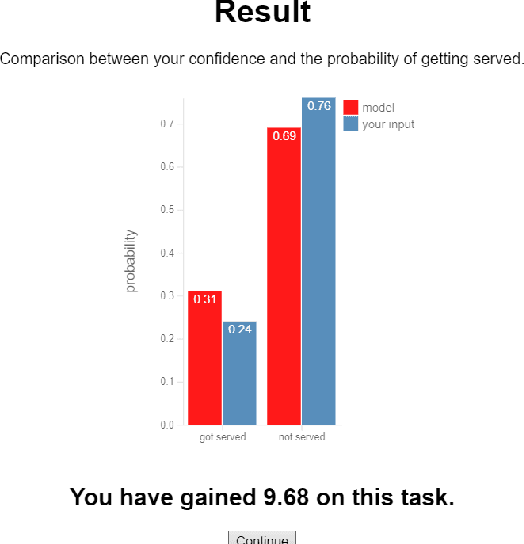
Probabilistic models inform an increasingly broad range of business and policy decisions ultimately made by people. Recent algorithmic, computational, and software framework development progress facilitate the proliferation of Bayesian probabilistic models, which characterise unobserved parameters by their joint distribution instead of point estimates. While they can empower decision makers to explore complex queries and to perform what-if-style conditioning in theory, suitable visualisations and interactive tools are needed to maximise users' comprehension and rational decision making under uncertainty. In this paper, propose a protocol for quantitative evaluation of Bayesian model visualisations and introduce a software framework implementing this protocol to support standardisation in evaluation practice and facilitate reproducibility. We illustrate the evaluation and analysis workflow on a user study that explores whether making Boxplots and Hypothetical Outcome Plots interactive can increase comprehension or rationality and conclude with design guidelines for researchers looking to conduct similar studies in the future.
Forward and Inverse models in HCI:Physical simulation and deep learning for inferring 3D finger pose
Sep 07, 2021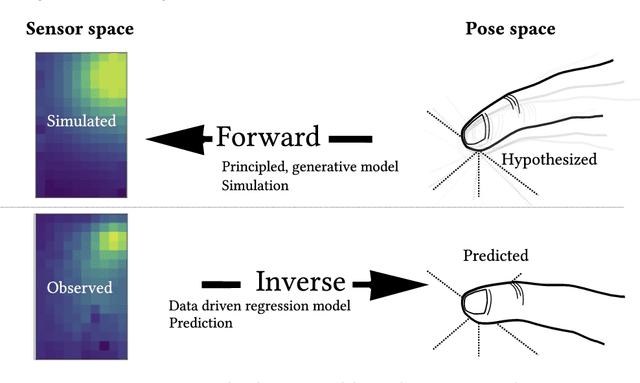


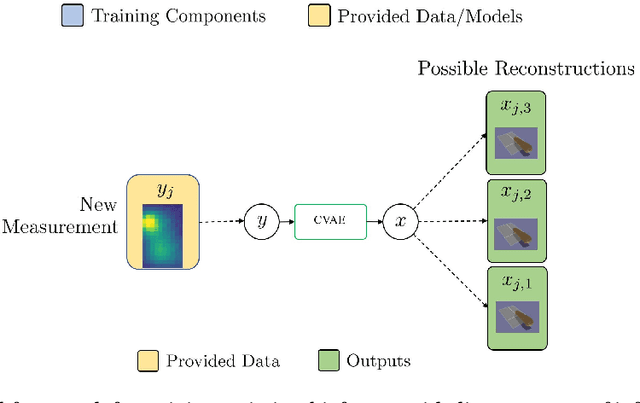
We outline the role of forward and inverse modelling approaches in the design of human--computer interaction systems. Causal, forward models tend to be easier to specify and simulate, but HCI requires solutions of the inverse problem. We infer finger 3D position $(x,y,z)$ and pose (pitch and yaw) on a mobile device using capacitive sensors which can sense the finger up to 5cm above the screen. We use machine learning to develop data-driven models to infer position, pose and sensor readings, based on training data from: 1. data generated by robots, 2. data from electrostatic simulators 3. human-generated data. Machine learned emulation is used to accelerate the electrostatic simulation performance by a factor of millions. We combine a Conditional Variational Autoencoder with domain expertise/models experimentally collected data. We compare forward and inverse model approaches to direct inference of finger pose. The combination gives the most accurate reported results on inferring 3D position and pose with a capacitive sensor on a mobile device.