 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring Uncertainty Calibration
Dec 15, 2025We make two contributions to the problem of estimating the $L_1$ calibration error of a binary classifier from a finite dataset. First, we provide an upper bound for any classifier where the calibration function has bounded variation. Second, we provide a method of modifying any classifier so that its calibration error can be upper bounded efficiently without significantly impacting classifier performance and without any restrictive assumptions. All our results are non-asymptotic and distribution-free. We conclude by providing advice on how to measure calibration error in practice. Our methods yield practical procedures that can be run on real-world datasets with modest overhead.
Rethinking Semi-supervised Learning with Language Models
May 22, 2023



Semi-supervised learning (SSL) is a popular setting aiming to effectively utilize unlabelled data to improve model performance in downstream natural language processing (NLP) tasks. Currently, there are two popular approaches to make use of unlabelled data: Self-training (ST) and Task-adaptive pre-training (TAPT). ST uses a teacher model to assign pseudo-labels to the unlabelled data, while TAPT continues pre-training on the unlabelled data before fine-tuning. To the best of our knowledge, the effectiveness of TAPT in SSL tasks has not been systematically studied, and no previous work has directly compared TAPT and ST in terms of their ability to utilize the pool of unlabelled data. In this paper, we provide an extensive empirical study comparing five state-of-the-art ST approaches and TAPT across various NLP tasks and data sizes, including in- and out-of-domain settings. Surprisingly, we find that TAPT is a strong and more robust SSL learner, even when using just a few hundred unlabelled samples or in the presence of domain shifts, compared to more sophisticated ST approaches, and tends to bring greater improvements in SSL than in fully-supervised settings. Our further analysis demonstrates the risks of using ST approaches when the size of labelled or unlabelled data is small or when domain shifts exist. We offer a fresh perspective for future SSL research, suggesting the use of unsupervised pre-training objectives over dependency on pseudo labels.
Forward and Inverse models in HCI:Physical simulation and deep learning for inferring 3D finger pose
Sep 07, 2021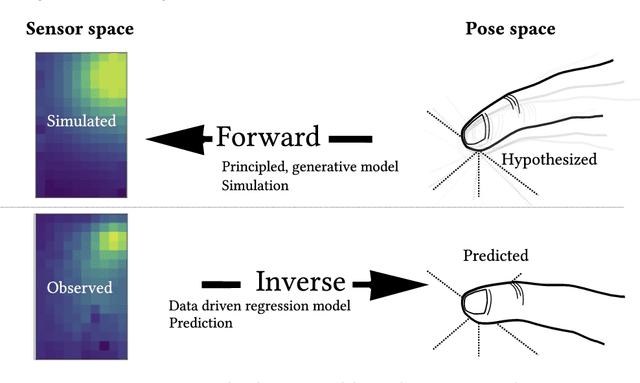


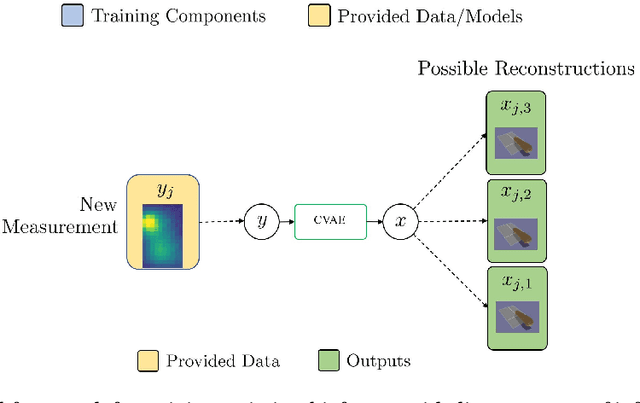
We outline the role of forward and inverse modelling approaches in the design of human--computer interaction systems. Causal, forward models tend to be easier to specify and simulate, but HCI requires solutions of the inverse problem. We infer finger 3D position $(x,y,z)$ and pose (pitch and yaw) on a mobile device using capacitive sensors which can sense the finger up to 5cm above the screen. We use machine learning to develop data-driven models to infer position, pose and sensor readings, based on training data from: 1. data generated by robots, 2. data from electrostatic simulators 3. human-generated data. Machine learned emulation is used to accelerate the electrostatic simulation performance by a factor of millions. We combine a Conditional Variational Autoencoder with domain expertise/models experimentally collected data. We compare forward and inverse model approaches to direct inference of finger pose. The combination gives the most accurate reported results on inferring 3D position and pose with a capacitive sensor on a mobile device.
Tomographic Auto-Encoder: Unsupervised Bayesian Recovery of Corrupted Data
Jun 30, 2020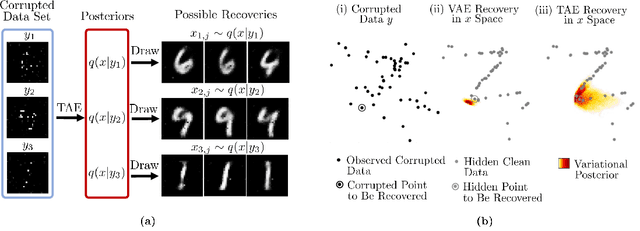

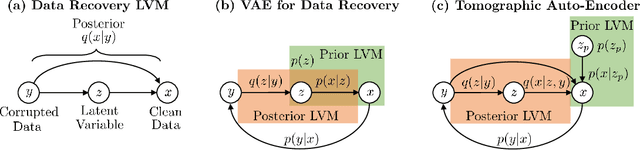
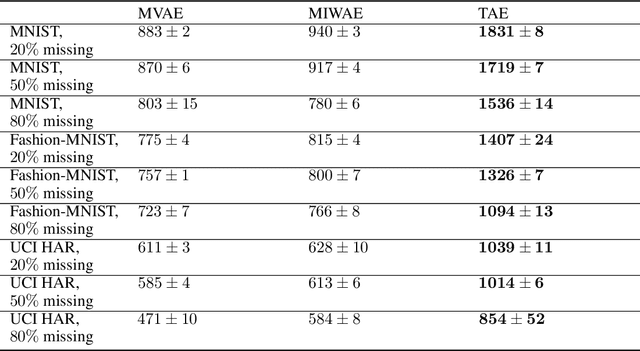
We propose a new probabilistic method for unsupervised recovery of corrupted data. Given a large ensemble of degraded samples, our method recovers accurate posteriors of clean values, allowing the exploration of the manifold of possible reconstructed data and hence characterising the underlying uncertainty. In this setting, direct application of classical variational methods often gives rise to collapsed densities that do not adequately explore the solution space. Instead, we derive our novel reduced entropy condition approximate inference method that results in rich posteriors. We test our model in a data recovery task under the common setting of missing values and noise, demonstrating superior performance to existing variational methods for imputation and de-noising with different real data sets. We further show higher classification accuracy after imputation, proving the advantage of propagating uncertainty to downstream tasks with our model.
Spatial images from temporal data
Dec 02, 2019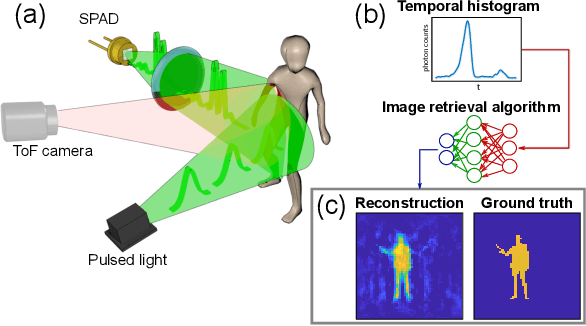
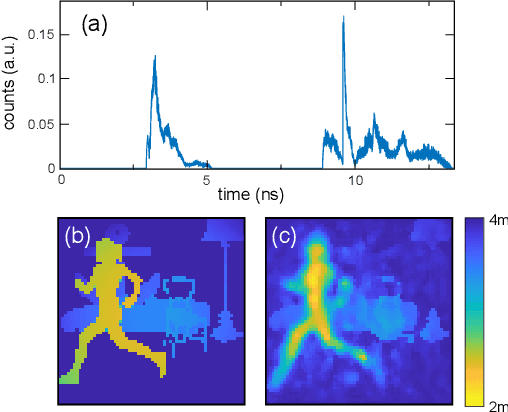
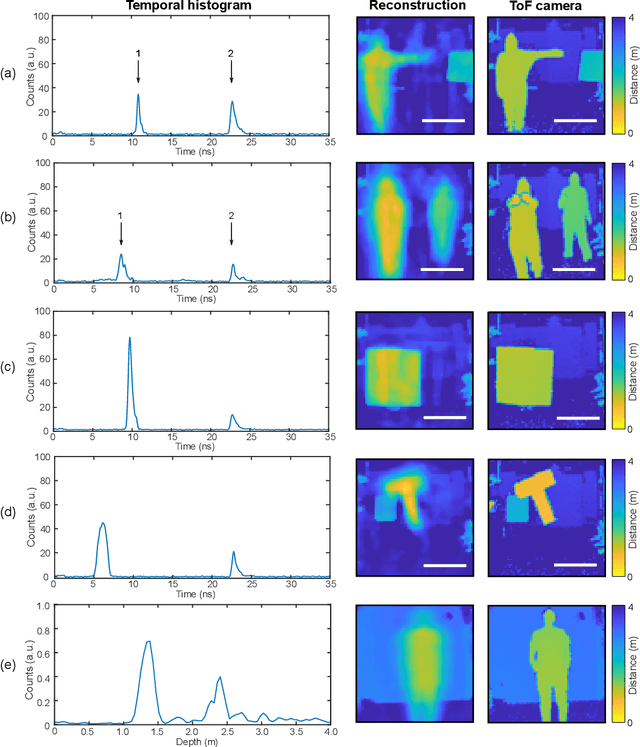
Traditional paradigms for imaging rely on the use of spatial structure either in the detector (pixels arrays) or in the illumination (patterned light). Removal of spatial structure in the detector or illumination, i.e. imaging with just a single-point sensor, would require solving a very strongly ill-posed inverse retrieval problem that to date has not been solved. Here we demonstrate a data-driven approach in which full 3D information is obtained with just a single-point, single-photon avalanche diode that records the arrival time of photons reflected from a scene that is illuminated with short pulses of light. Imaging with single-point time-of-flight (temporal) data opens new routes in terms of speed, size, and functionality. As an example, we show how the training based on an optical time-of-flight camera enables a compact radio-frequency impulse RADAR transceiver to provide 3D images.
Bayesian parameter estimation using conditional variational autoencoders for gravitational-wave astronomy
Sep 17, 2019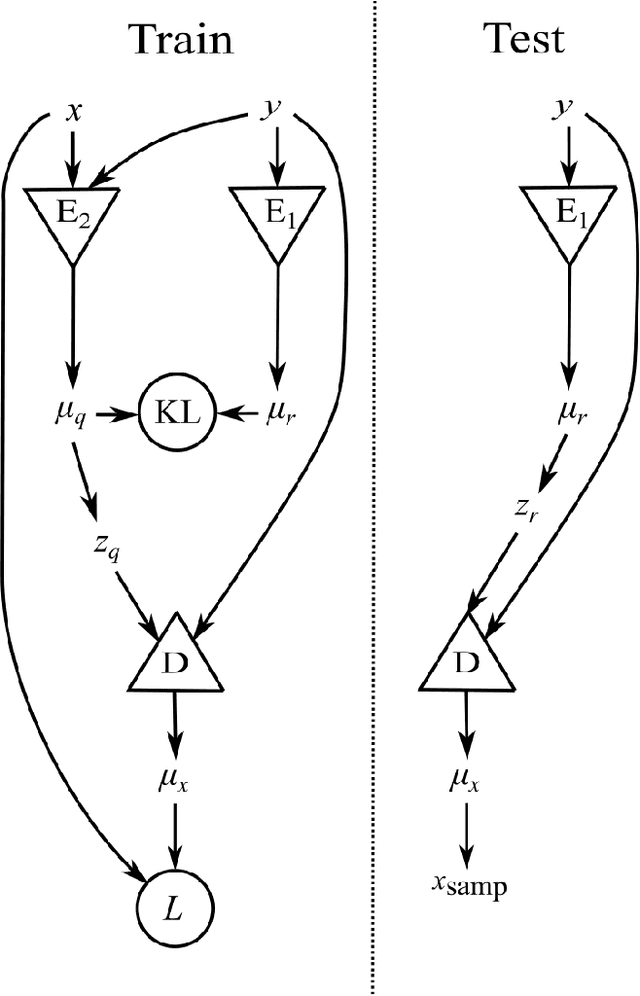
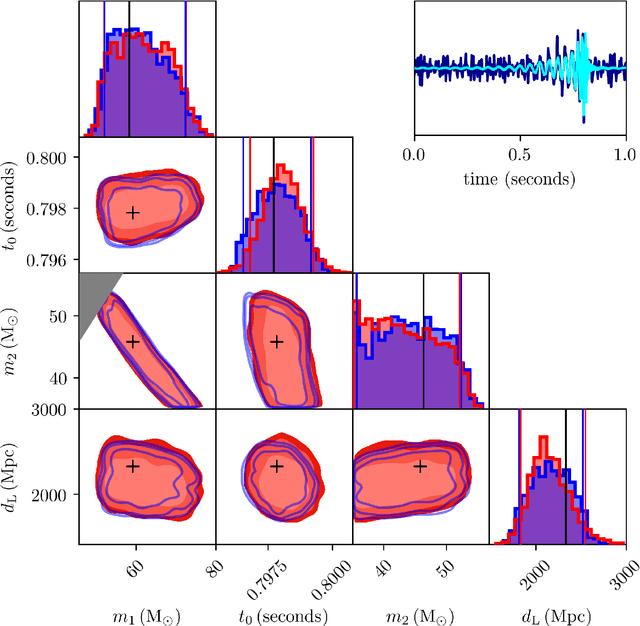
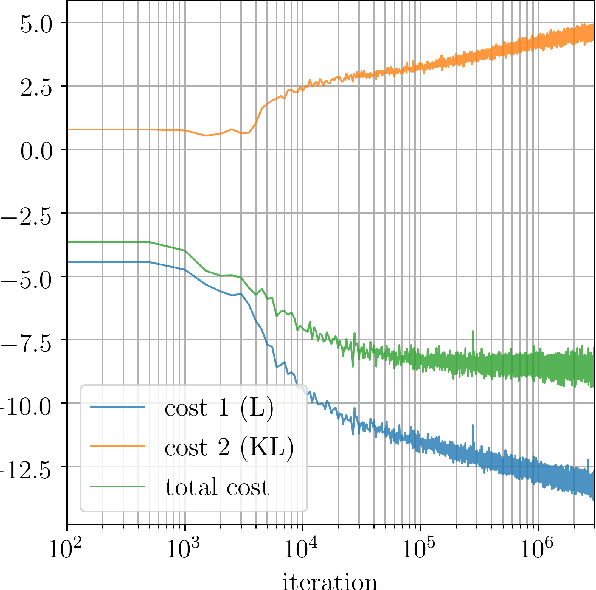
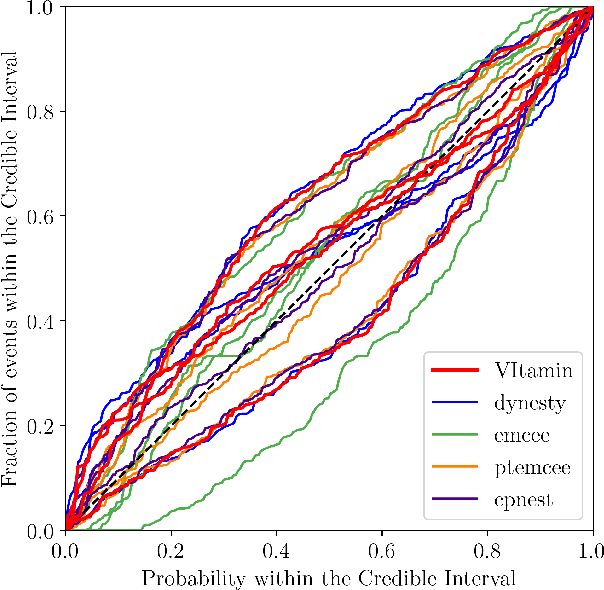
Gravitational wave (GW) detection is now commonplace and as the sensitivity of the global network of GW detectors improves, we will observe $\mathcal{O}(100)$s of transient GW events per year. The current methods used to estimate their source parameters employ optimally sensitive but computationally costly Bayesian inference approaches where typical analyses have taken between 6 hours and 5 days. For binary neutron star and neutron star black hole systems prompt counterpart electromagnetic (EM) signatures are expected on timescales of 1 second -- 1 minute and the current fastest method for alerting EM follow-up observers, can provide estimates in $\mathcal{O}(1)$ minute, on a limited range of key source parameters. Here we show that a conditional variational autoencoder pre-trained on binary black hole signals can return Bayesian posterior probability estimates. The training procedure need only be performed once for a given prior parameter space and the resulting trained machine can then generate samples describing the posterior distribution $\sim 6$ orders of magnitude faster than existing techniques.
Variational Inference for Computational Imaging Inverse Problems
Apr 12, 2019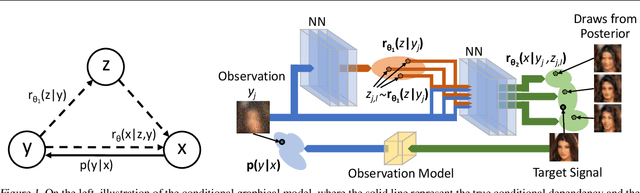
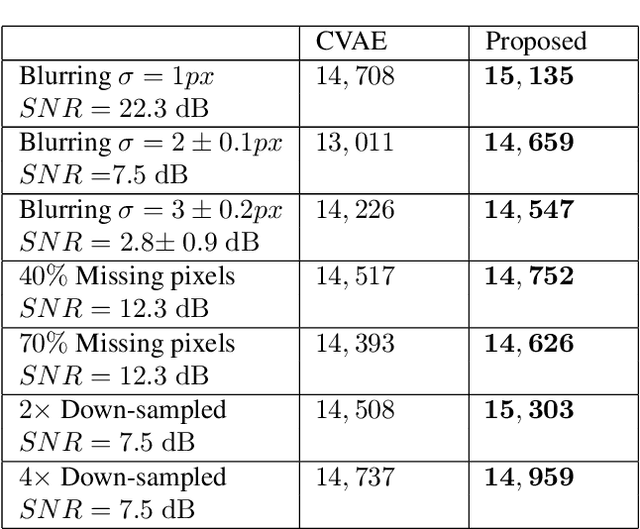
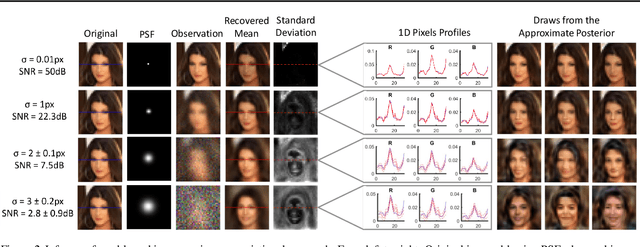
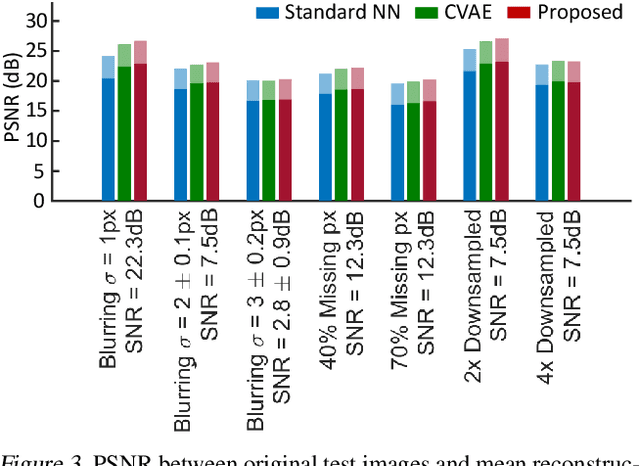
We introduce a method to infer a variational approximation to the posterior distribution of solutions in computational imaging inverse problems. Machine learning methods applied to computational imaging have proven very successful, but have so far largely focused on retrieving a single optimal solution for a given task. Such retrieval is arguably an incomplete description of the solution space, as in ill-posed inverse problems there may be many similarly likely reconstructions. We minimise an upper bound on the divergence between our approximate distribution and the true intractable posterior, thereby obtaining a probabilistic description of the solution space in imaging inverse problems with empirical prior. We demonstrate the advantage of our technique in quantitative simulations with the CelebA dataset and common image reconstruction tasks. We then apply our method to two of the currently most challenging problems in experimental optics: imaging through highly scattering media and imaging through multi-modal optical fibres. In both settings we report state of the art reconstructions, while providing new capabilities, such as estimation of error-bars and visualisation of multiple likely reconstructions.