 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Effectiveness and Efficiency of Agentic Tool-calling and RL Training
May 28, 2026Tool-calling is a central component of modern large language model (LLM) agents, equipping them with skills beyond their parametric knowledge. This paper studies tool-calling along two complementary axes: effectiveness, i.e., how this capability is measured, and efficiency, i.e., how it is learned. On effectiveness, we systematically analyze tool-calling evaluation pipelines and show that results can be highly sensitive to seemingly minor, often undocumented implementation choices including the random seed, system prompt, multi-turn template construction, and how prior interaction/reasoning history is carried forward. These choices can lead to substantial differences in reported performance, especially in multi-turn settings where without rigorous standardization, leaderboard rankings are unreliable. On efficiency, we examine standard reinforcement learning (RL) for tool-calling and identify two sources of computational waste: (i) during rollouts, many prompts produce no learning signal, and (ii) during policy updates, optimization incurs high computational cost. Guided by these findings, we introduce two techniques that accelerate RL-based tool-calling training, achieving substantial wall-clock speedup without degrading performance.
Schema-Guided User Satisfaction Modeling for Task-Oriented Dialogues
May 26, 2023



User Satisfaction Modeling (USM) is one of the popular choices for task-oriented dialogue systems evaluation, where user satisfaction typically depends on whether the user's task goals were fulfilled by the system. Task-oriented dialogue systems use task schema, which is a set of task attributes, to encode the user's task goals. Existing studies on USM neglect explicitly modeling the user's task goals fulfillment using the task schema. In this paper, we propose SG-USM, a novel schema-guided user satisfaction modeling framework. It explicitly models the degree to which the user's preferences regarding the task attributes are fulfilled by the system for predicting the user's satisfaction level. SG-USM employs a pre-trained language model for encoding dialogue context and task attributes. Further, it employs a fulfillment representation layer for learning how many task attributes have been fulfilled in the dialogue, an importance predictor component for calculating the importance of task attributes. Finally, it predicts the user satisfaction based on task attribute fulfillment and task attribute importance. Experimental results on benchmark datasets (i.e. MWOZ, SGD, ReDial, and JDDC) show that SG-USM consistently outperforms competitive existing methods. Our extensive analysis demonstrates that SG-USM can improve the interpretability of user satisfaction modeling, has good scalability as it can effectively deal with unseen tasks and can also effectively work in low-resource settings by leveraging unlabeled data.
Rethinking Semi-supervised Learning with Language Models
May 22, 2023



Semi-supervised learning (SSL) is a popular setting aiming to effectively utilize unlabelled data to improve model performance in downstream natural language processing (NLP) tasks. Currently, there are two popular approaches to make use of unlabelled data: Self-training (ST) and Task-adaptive pre-training (TAPT). ST uses a teacher model to assign pseudo-labels to the unlabelled data, while TAPT continues pre-training on the unlabelled data before fine-tuning. To the best of our knowledge, the effectiveness of TAPT in SSL tasks has not been systematically studied, and no previous work has directly compared TAPT and ST in terms of their ability to utilize the pool of unlabelled data. In this paper, we provide an extensive empirical study comparing five state-of-the-art ST approaches and TAPT across various NLP tasks and data sizes, including in- and out-of-domain settings. Surprisingly, we find that TAPT is a strong and more robust SSL learner, even when using just a few hundred unlabelled samples or in the presence of domain shifts, compared to more sophisticated ST approaches, and tends to bring greater improvements in SSL than in fully-supervised settings. Our further analysis demonstrates the risks of using ST approaches when the size of labelled or unlabelled data is small or when domain shifts exist. We offer a fresh perspective for future SSL research, suggesting the use of unsupervised pre-training objectives over dependency on pseudo labels.
Less is Less: When Are Snippets Insufficient for Human vs Machine Relevance Estimation?
Jan 21, 2022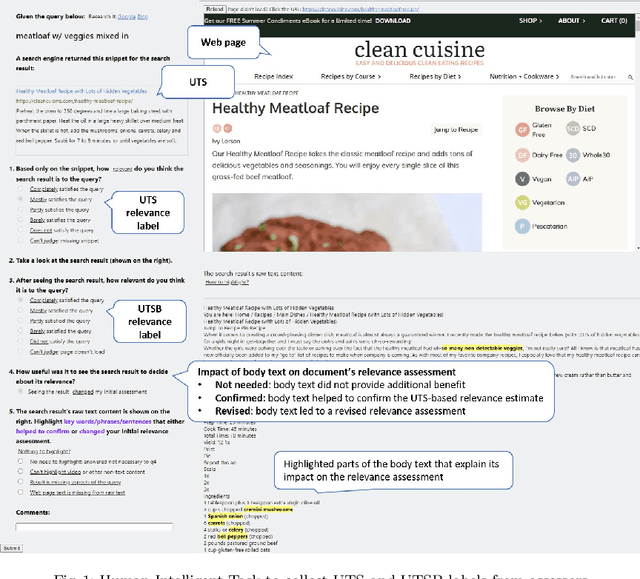

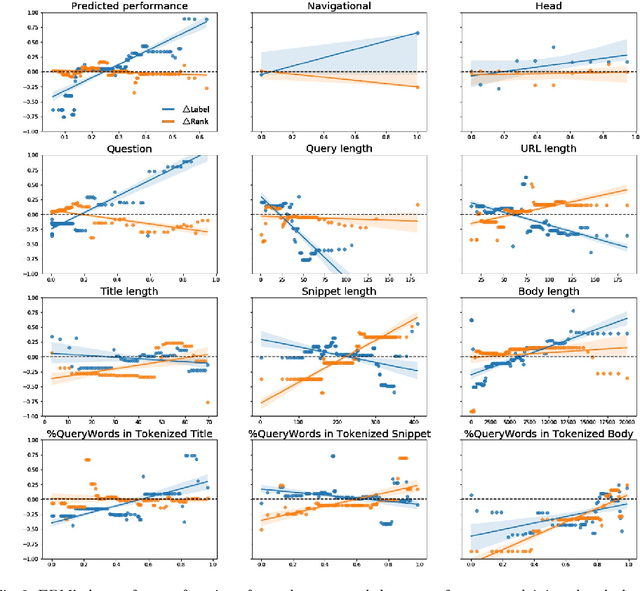

Traditional information retrieval (IR) ranking models process the full text of documents. Newer models based on Transformers, however, would incur a high computational cost when processing long texts, so typically use only snippets from the document instead. The model's input based on a document's URL, title, and snippet (UTS) is akin to the summaries that appear on a search engine results page (SERP) to help searchers decide which result to click. This raises questions about when such summaries are sufficient for relevance estimation by the ranking model or the human assessor, and whether humans and machines benefit from the document's full text in similar ways. To answer these questions, we study human and neural model based relevance assessments on 12k query-documents sampled from Bing's search logs. We compare changes in the relevance assessments when only the document summaries and when the full text is also exposed to assessors, studying a range of query and document properties, e.g., query type, snippet length. Our findings show that the full text is beneficial for humans and a BERT model for similar query and document types, e.g., tail, long queries. A closer look, however, reveals that humans and machines respond to the additional input in very different ways. Adding the full text can also hurt the ranker's performance, e.g., for navigational queries.