 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSchema-Guided User Satisfaction Modeling for Task-Oriented Dialogues
May 26, 2023



User Satisfaction Modeling (USM) is one of the popular choices for task-oriented dialogue systems evaluation, where user satisfaction typically depends on whether the user's task goals were fulfilled by the system. Task-oriented dialogue systems use task schema, which is a set of task attributes, to encode the user's task goals. Existing studies on USM neglect explicitly modeling the user's task goals fulfillment using the task schema. In this paper, we propose SG-USM, a novel schema-guided user satisfaction modeling framework. It explicitly models the degree to which the user's preferences regarding the task attributes are fulfilled by the system for predicting the user's satisfaction level. SG-USM employs a pre-trained language model for encoding dialogue context and task attributes. Further, it employs a fulfillment representation layer for learning how many task attributes have been fulfilled in the dialogue, an importance predictor component for calculating the importance of task attributes. Finally, it predicts the user satisfaction based on task attribute fulfillment and task attribute importance. Experimental results on benchmark datasets (i.e. MWOZ, SGD, ReDial, and JDDC) show that SG-USM consistently outperforms competitive existing methods. Our extensive analysis demonstrates that SG-USM can improve the interpretability of user satisfaction modeling, has good scalability as it can effectively deal with unseen tasks and can also effectively work in low-resource settings by leveraging unlabeled data.
Distribution augmentation for low-resource expressive text-to-speech
Feb 19, 2022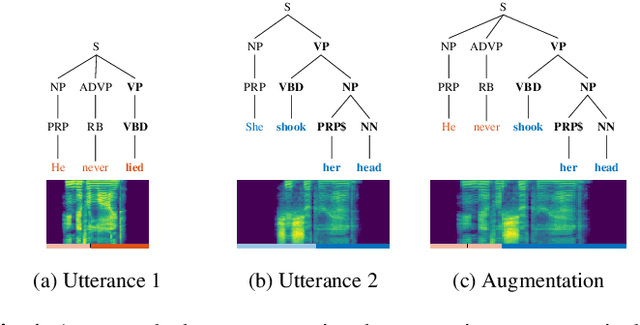
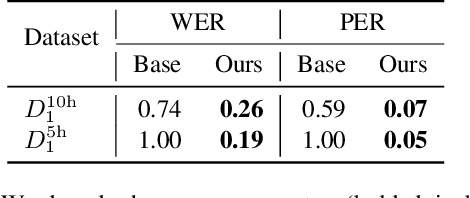
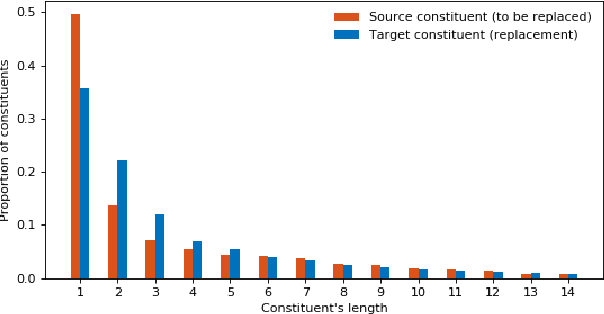
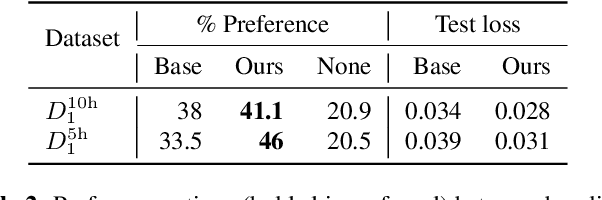
This paper presents a novel data augmentation technique for text-to-speech (TTS), that allows to generate new (text, audio) training examples without requiring any additional data. Our goal is to increase diversity of text conditionings available during training. This helps to reduce overfitting, especially in low-resource settings. Our method relies on substituting text and audio fragments in a way that preserves syntactical correctness. We take additional measures to ensure that synthesized speech does not contain artifacts caused by combining inconsistent audio samples. The perceptual evaluations show that our method improves speech quality over a number of datasets, speakers, and TTS architectures. We also demonstrate that it greatly improves robustness of attention-based TTS models.
Neural Multi-Task Learning for Citation Function and Provenance
Nov 18, 2018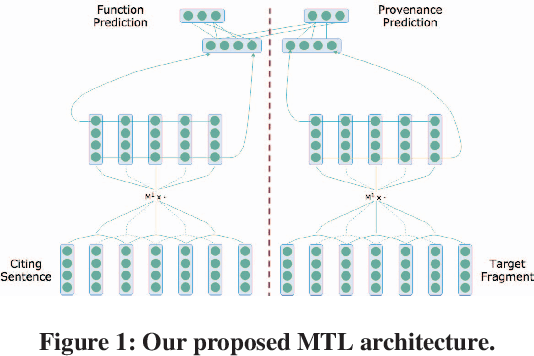
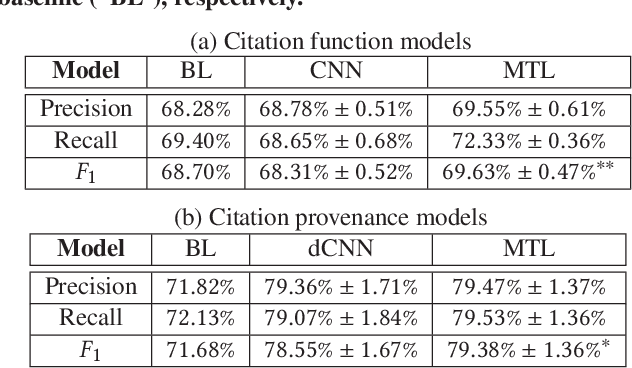
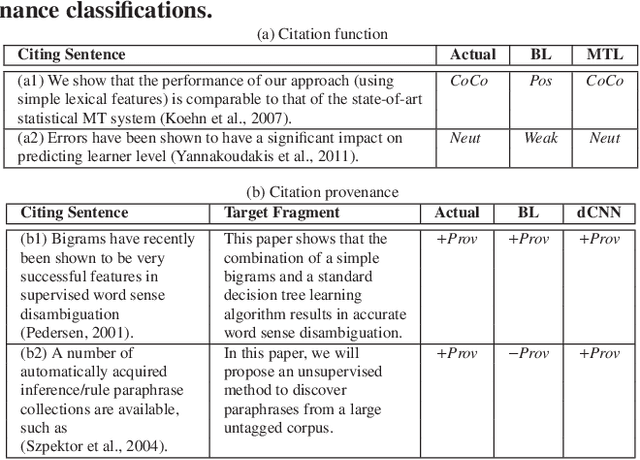
Citation function and provenance are two cornerstone tasks in citation analysis. Given a citation, the former task determines its rhetorical role, while the latter locates the text in the cited paper that contains the relevant cited information. We hypothesize that these two tasks are synergistically related, and build a model that validates this claim. For both tasks, we show that a single-layer convolutional neural network (CNN) is able to surpass the performance of existing state-of-the-art baselines. More importantly, we show that the two tasks are indeed synergistic: by training both tasks in one go using multi-task learning, we demonstrate additional performance gains in both tasks. Altogether, our contributions outperform the current state-of-the-arts by ~2% and ~7%, with statistical significance for citation function and citation provenance prediction tasks, respectively.
Bench-Marking Information Extraction in Semi-Structured Historical Handwritten Records
Jul 17, 2018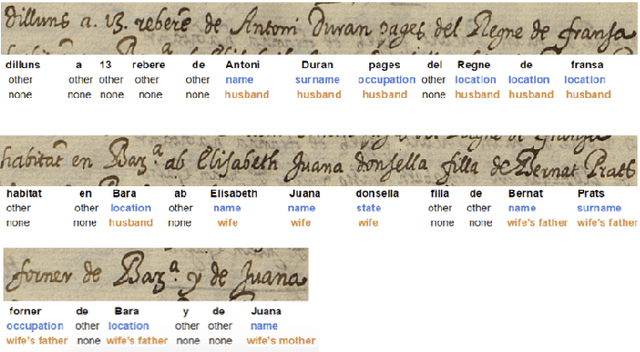
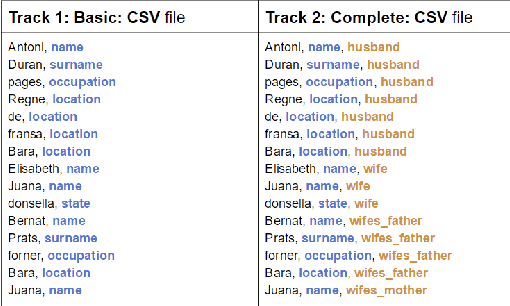
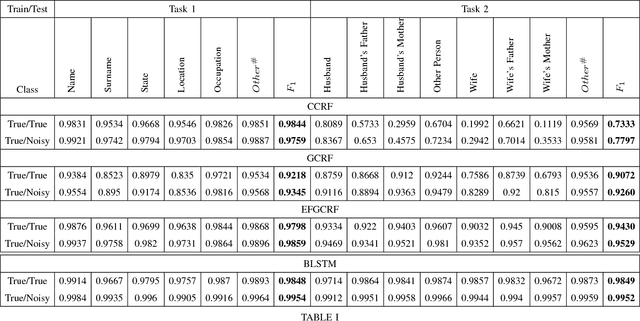
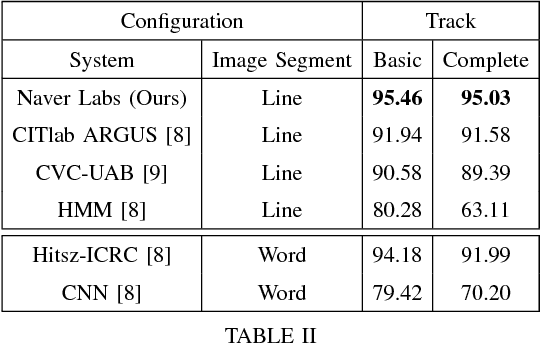
In this report, we present our findings from benchmarking experiments for information extraction on historical handwritten marriage records Esposalles from IEHHR - ICDAR 2017 robust reading competition. The information extraction is modeled as semantic labeling of the sequence across 2 set of labels. This can be achieved by sequentially or jointly applying handwritten text recognition (HTR) and named entity recognition (NER). We deploy a pipeline approach where first we use state-of-the-art HTR and use its output as input for NER. We show that given low resource setup and simple structure of the records, high performance of HTR ensures overall high performance. We explore the various configurations of conditional random fields and neural networks to benchmark NER on given certain noisy input. The best model on 10-fold cross-validation as well as blind test data uses n-gram features with bidirectional long short-term memory.