 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Sequence-to-Sequence Models for Handwritten Text Recognition
Mar 18, 2019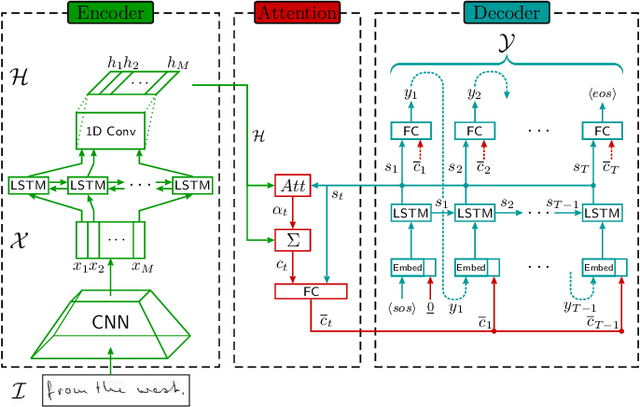

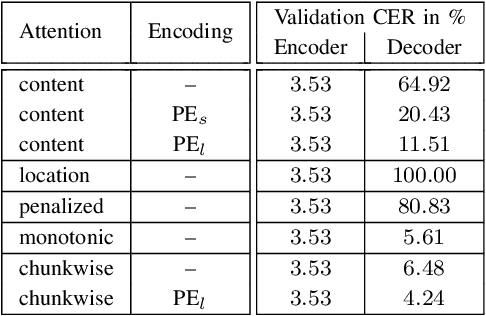
Encoder-decoder models have become an effective approach for sequence learning tasks like machine translation, image captioning and speech recognition, but have yet to show competitive results for handwritten text recognition. To this end, we propose an attention-based sequence-to-sequence model. It combines a convolutional neural network as a generic feature extractor with a recurrent neural network to encode both the visual information, as well as the temporal context between characters in the input image, and uses a separate recurrent neural network to decode the actual character sequence. We make experimental comparisons between various attention mechanisms and positional encodings, in order to find an appropriate alignment between the input and output sequence. The model can be trained end-to-end and the optional integration of a hybrid loss allows the encoder to retain an interpretable and usable output, e.g. for keyword spotting purposes without prior indexing, if desired. We achieve competitive results on the IAM and ICFHR2016 READ data sets compared to the state-of-the-art without the use of a language model, and we significantly improve over any recent sequence-to-sequence approaches.
Bench-Marking Information Extraction in Semi-Structured Historical Handwritten Records
Jul 17, 2018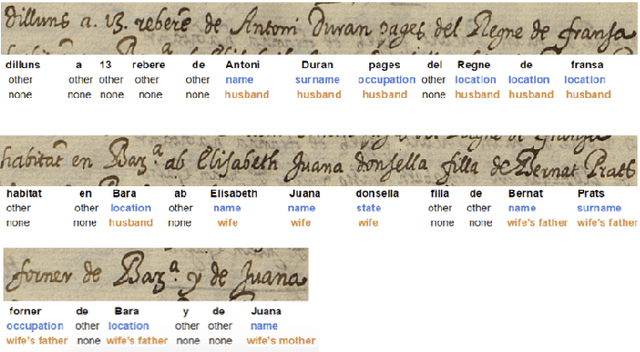
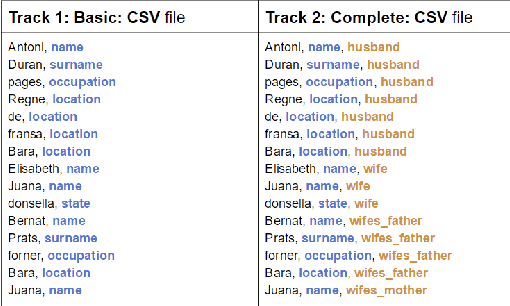
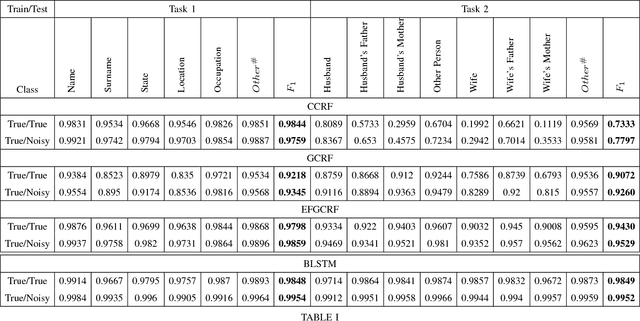
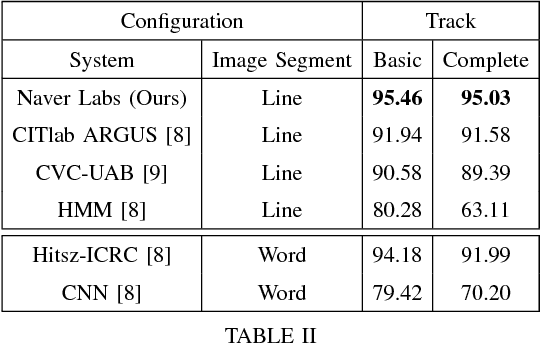
In this report, we present our findings from benchmarking experiments for information extraction on historical handwritten marriage records Esposalles from IEHHR - ICDAR 2017 robust reading competition. The information extraction is modeled as semantic labeling of the sequence across 2 set of labels. This can be achieved by sequentially or jointly applying handwritten text recognition (HTR) and named entity recognition (NER). We deploy a pipeline approach where first we use state-of-the-art HTR and use its output as input for NER. We show that given low resource setup and simple structure of the records, high performance of HTR ensures overall high performance. We explore the various configurations of conditional random fields and neural networks to benchmark NER on given certain noisy input. The best model on 10-fold cross-validation as well as blind test data uses n-gram features with bidirectional long short-term memory.