 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangled Object-Centric Image Representation for Robotic Manipulation
Mar 14, 2025Learning robotic manipulation skills from vision is a promising approach for developing robotics applications that can generalize broadly to real-world scenarios. As such, many approaches to enable this vision have been explored with fruitful results. Particularly, object-centric representation methods have been shown to provide better inductive biases for skill learning, leading to improved performance and generalization. Nonetheless, we show that object-centric methods can struggle to learn simple manipulation skills in multi-object environments. Thus, we propose DOCIR, an object-centric framework that introduces a disentangled representation for objects of interest, obstacles, and robot embodiment. We show that this approach leads to state-of-the-art performance for learning pick and place skills from visual inputs in multi-object environments and generalizes at test time to changing objects of interest and distractors in the scene. Furthermore, we show its efficacy both in simulation and zero-shot transfer to the real world.
Investigating the potential of Sparse Mixtures-of-Experts for multi-domain neural machine translation
Jul 01, 2024



We focus on multi-domain Neural Machine Translation, with the goal of developing efficient models which can handle data from various domains seen during training and are robust to domains unseen during training. We hypothesize that Sparse Mixture-of-Experts (SMoE) models are a good fit for this task, as they enable efficient model scaling, which helps to accommodate a variety of multi-domain data, and allow flexible sharing of parameters between domains, potentially enabling knowledge transfer between similar domains and limiting negative transfer. We conduct a series of experiments aimed at validating the utility of SMoE for the multi-domain scenario, and find that a straightforward width scaling of Transformer is a simpler and surprisingly more efficient approach in practice, and reaches the same performance level as SMoE. We also search for a better recipe for robustness of multi-domain systems, highlighting the importance of mixing-in a generic domain, i.e. Paracrawl, and introducing a simple technique, domain randomization.
Machine Translation of Restaurant Reviews: New Corpus for Domain Adaptation and Robustness
Oct 31, 2019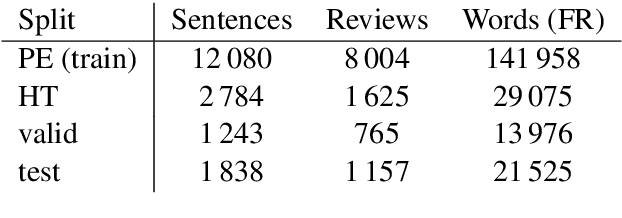


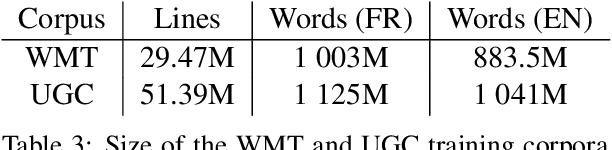
We share a French-English parallel corpus of Foursquare restaurant reviews (https://europe.naverlabs.com/research/natural-language-processing/machine-translation-of-restaurant-reviews), and define a new task to encourage research on Neural Machine Translation robustness and domain adaptation, in a real-world scenario where better-quality MT would be greatly beneficial. We discuss the challenges of such user-generated content, and train good baseline models that build upon the latest techniques for MT robustness. We also perform an extensive evaluation (automatic and human) that shows significant improvements over existing online systems. Finally, we propose task-specific metrics based on sentiment analysis or translation accuracy of domain-specific polysemous words.
Comparing Machine Learning Approaches for Table Recognition in Historical Register Books
Jun 14, 2019

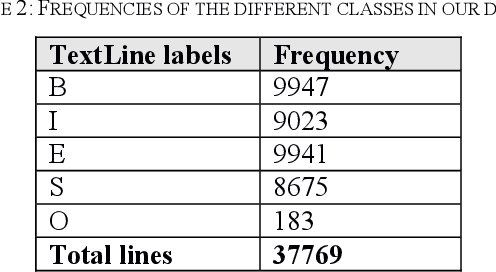
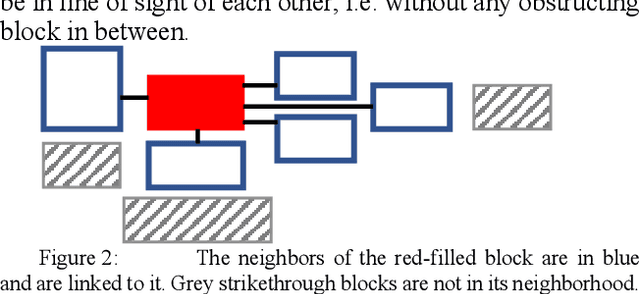
We present in this paper experiments on Table Recognition in hand-written registry books. We first explain how the problem of row and column detection is modeled, and then compare two Machine Learning approaches (Conditional Random Field and Graph Convolutional Network) for detecting these table elements. Evaluation was conducted on death records provided by the Archive of the Diocese of Passau. Both methods show similar results, a 89 F1 score, a quality which allows for Information Extraction. Software and dataset are open source/data.
Bench-Marking Information Extraction in Semi-Structured Historical Handwritten Records
Jul 17, 2018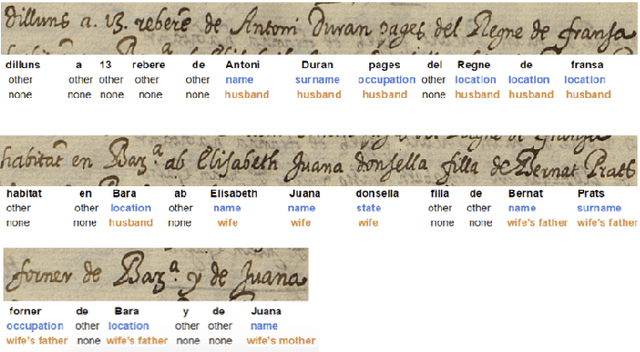
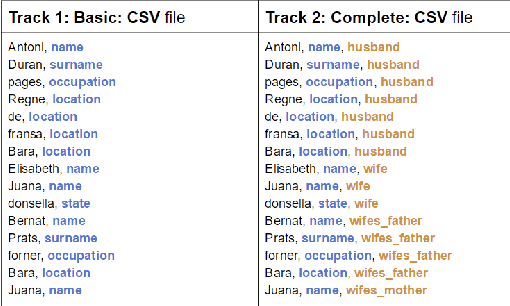
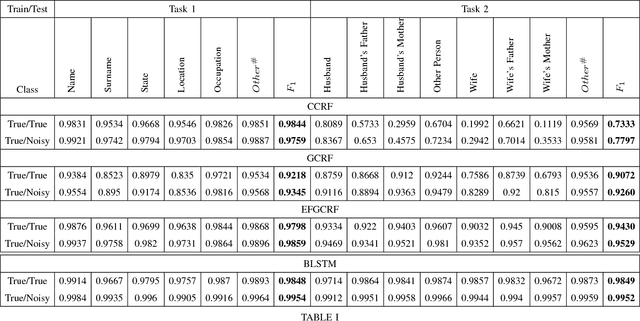
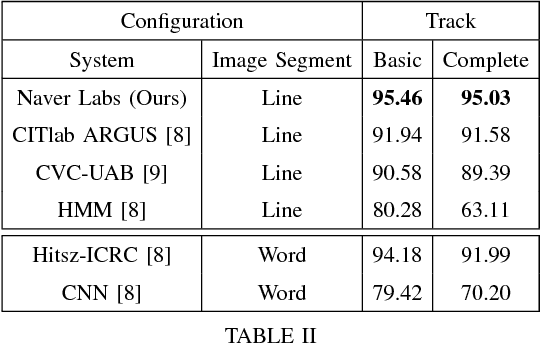
In this report, we present our findings from benchmarking experiments for information extraction on historical handwritten marriage records Esposalles from IEHHR - ICDAR 2017 robust reading competition. The information extraction is modeled as semantic labeling of the sequence across 2 set of labels. This can be achieved by sequentially or jointly applying handwritten text recognition (HTR) and named entity recognition (NER). We deploy a pipeline approach where first we use state-of-the-art HTR and use its output as input for NER. We show that given low resource setup and simple structure of the records, high performance of HTR ensures overall high performance. We explore the various configurations of conditional random fields and neural networks to benchmark NER on given certain noisy input. The best model on 10-fold cross-validation as well as blind test data uses n-gram features with bidirectional long short-term memory.
Joint Structured Learning and Predictions under Logical Constraints in Conditional Random Fields
Aug 25, 2017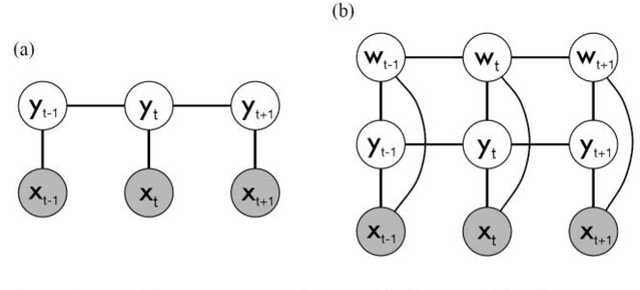

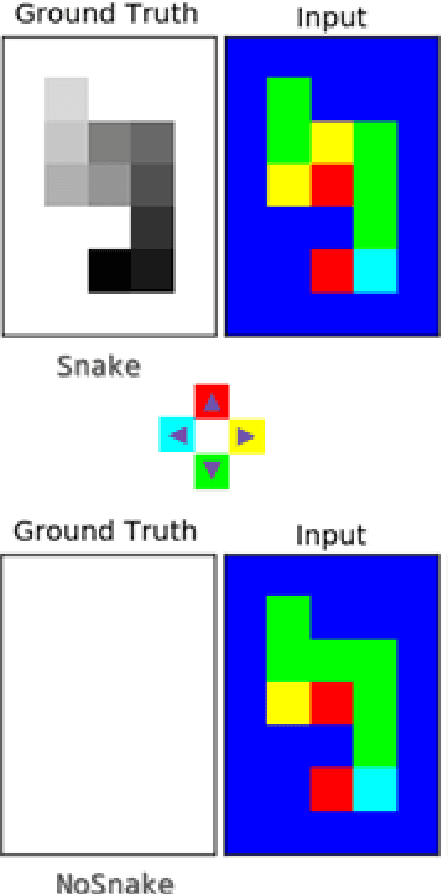
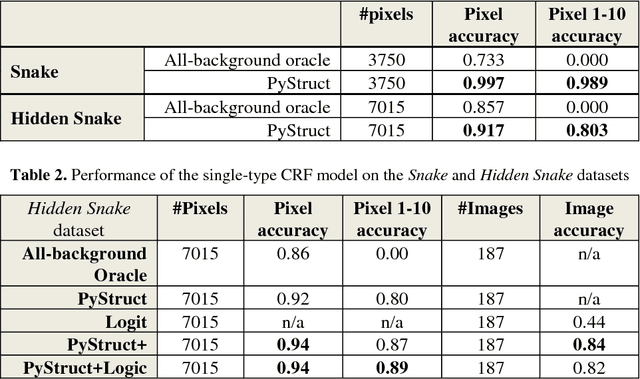
This paper is concerned with structured machine learning, in a supervised machine learning context. It discusses how to make joint structured learning on interdependent objects of different nature, as well as how to enforce logical con-straints when predicting labels. We explain how this need arose in a Document Understanding task. We then discuss a general extension to Conditional Random Field (CRF) for this purpose and present the contributed open source implementation on top of the open source PyStruct library. We evaluate its performance on a publicly available dataset.