 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangled Object-Centric Image Representation for Robotic Manipulation
Mar 14, 2025Learning robotic manipulation skills from vision is a promising approach for developing robotics applications that can generalize broadly to real-world scenarios. As such, many approaches to enable this vision have been explored with fruitful results. Particularly, object-centric representation methods have been shown to provide better inductive biases for skill learning, leading to improved performance and generalization. Nonetheless, we show that object-centric methods can struggle to learn simple manipulation skills in multi-object environments. Thus, we propose DOCIR, an object-centric framework that introduces a disentangled representation for objects of interest, obstacles, and robot embodiment. We show that this approach leads to state-of-the-art performance for learning pick and place skills from visual inputs in multi-object environments and generalizes at test time to changing objects of interest and distractors in the scene. Furthermore, we show its efficacy both in simulation and zero-shot transfer to the real world.
LARG, Language-based Automatic Reward and Goal Generation
Jun 19, 2023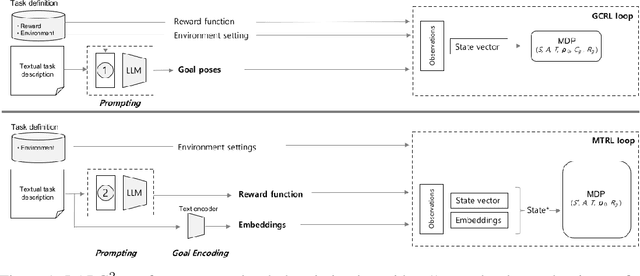


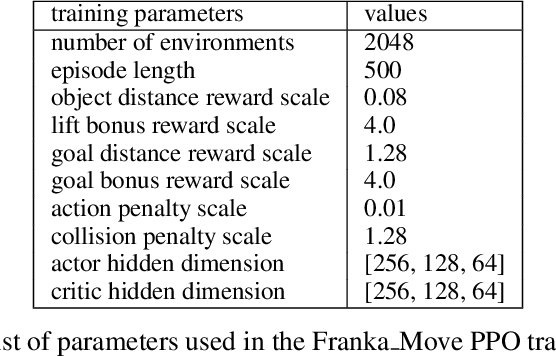
Goal-conditioned and Multi-Task Reinforcement Learning (GCRL and MTRL) address numerous problems related to robot learning, including locomotion, navigation, and manipulation scenarios. Recent works focusing on language-defined robotic manipulation tasks have led to the tedious production of massive human annotations to create dataset of textual descriptions associated with trajectories. To leverage reinforcement learning with text-based task descriptions, we need to produce reward functions associated with individual tasks in a scalable manner. In this paper, we leverage recent capabilities of Large Language Models (LLMs) and introduce \larg, Language-based Automatic Reward and Goal Generation, an approach that converts a text-based task description into its corresponding reward and goal-generation functions We evaluate our approach for robotic manipulation and demonstrate its ability to train and execute policies in a scalable manner, without the need for handcrafted reward functions.