 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAKD : Adversarial Knowledge Distillation For Large Language Models Alignment on Coding tasks
May 05, 2025
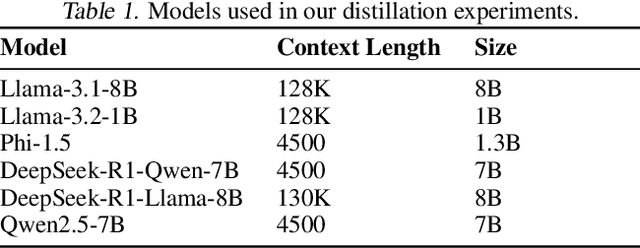
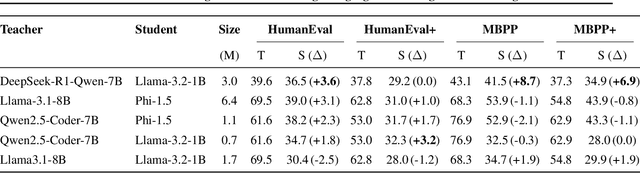

The widespread adoption of Large Language Models (LLMs) for code generation, exemplified by GitHub Copilot\footnote{A coding extension powered by a Code-LLM to assist in code completion tasks} surpassing a million users, highlights the transformative potential of these tools in improving developer productivity. However, this rapid growth also underscores critical concerns regarding the quality, safety, and reliability of the code they generate. As Code-LLMs evolve, they face significant challenges, including the diminishing returns of model scaling and the scarcity of new, high-quality training data. To address these issues, this paper introduces Adversarial Knowledge Distillation (AKD), a novel approach that leverages adversarially generated synthetic datasets to distill the capabilities of larger models into smaller, more efficient ones. By systematically stress-testing and refining the reasoning capabilities of Code-LLMs, AKD provides a framework for enhancing model robustness, reliability, and security while improving their parameter-efficiency. We believe this work represents a critical step toward ensuring dependable automated code generation within the constraints of existing data and the cost-efficiency of model execution.
Unsupervised Skill Discovery for Robotic Manipulation through Automatic Task Generation
Oct 07, 2024Learning skills that interact with objects is of major importance for robotic manipulation. These skills can indeed serve as an efficient prior for solving various manipulation tasks. We propose a novel Skill Learning approach that discovers composable behaviors by solving a large and diverse number of autonomously generated tasks. Our method learns skills allowing the robot to consistently and robustly interact with objects in its environment. The discovered behaviors are embedded in primitives which can be composed with Hierarchical Reinforcement Learning to solve unseen manipulation tasks. In particular, we leverage Asymmetric Self-Play to discover behaviors and Multiplicative Compositional Policies to embed them. We compare our method to Skill Learning baselines and find that our skills are more interactive. Furthermore, the learned skills can be used to solve a set of unseen manipulation tasks, in simulation as well as on a real robotic platform.
SLIM: Skill Learning with Multiple Critics
Feb 01, 2024Self-supervised skill learning aims to acquire useful behaviors that leverage the underlying dynamics of the environment. Latent variable models, based on mutual information maximization, have been particularly successful in this task but still struggle in the context of robotic manipulation. As it requires impacting a possibly large set of degrees of freedom composing the environment, mutual information maximization fails alone in producing useful manipulation behaviors. To address this limitation, we introduce SLIM, a multi-critic learning approach for skill discovery with a particular focus on robotic manipulation. Our main insight is that utilizing multiple critics in an actor-critic framework to gracefully combine multiple reward functions leads to a significant improvement in latent-variable skill discovery for robotic manipulation while overcoming possible interference occurring among rewards which hinders convergence to useful skills. Furthermore, in the context of tabletop manipulation, we demonstrate the applicability of our novel skill discovery approach to acquire safe and efficient motor primitives in a hierarchical reinforcement learning fashion and leverage them through planning, surpassing the state-of-the-art approaches for skill discovery by a large margin.
LARG, Language-based Automatic Reward and Goal Generation
Jun 19, 2023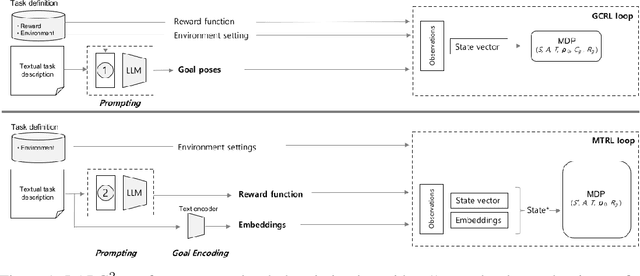


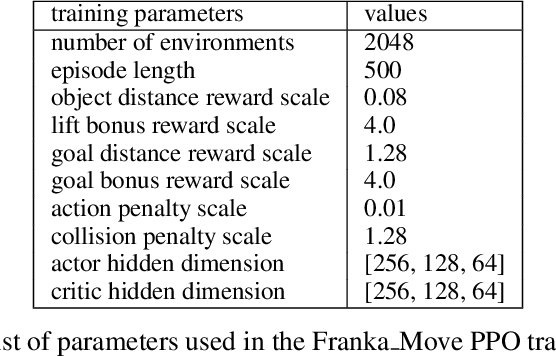
Goal-conditioned and Multi-Task Reinforcement Learning (GCRL and MTRL) address numerous problems related to robot learning, including locomotion, navigation, and manipulation scenarios. Recent works focusing on language-defined robotic manipulation tasks have led to the tedious production of massive human annotations to create dataset of textual descriptions associated with trajectories. To leverage reinforcement learning with text-based task descriptions, we need to produce reward functions associated with individual tasks in a scalable manner. In this paper, we leverage recent capabilities of Large Language Models (LLMs) and introduce \larg, Language-based Automatic Reward and Goal Generation, an approach that converts a text-based task description into its corresponding reward and goal-generation functions We evaluate our approach for robotic manipulation and demonstrate its ability to train and execute policies in a scalable manner, without the need for handcrafted reward functions.
Learning Visual Representations with Caption Annotations
Aug 04, 2020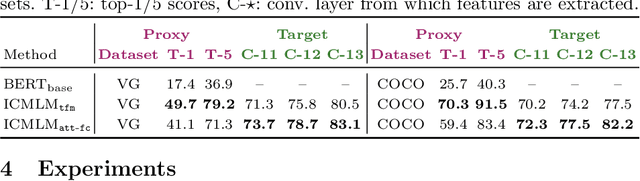

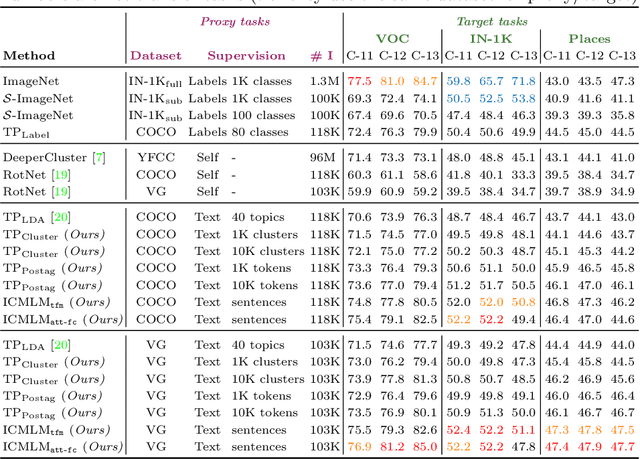

Pretraining general-purpose visual features has become a crucial part of tackling many computer vision tasks. While one can learn such features on the extensively-annotated ImageNet dataset, recent approaches have looked at ways to allow for noisy, fewer, or even no annotations to perform such pretraining. Starting from the observation that captioned images are easily crawlable, we argue that this overlooked source of information can be exploited to supervise the training of visual representations. To do so, motivated by the recent progresses in language models, we introduce {\em image-conditioned masked language modeling} (ICMLM) -- a proxy task to learn visual representations over image-caption pairs. ICMLM consists in predicting masked words in captions by relying on visual cues. To tackle this task, we propose hybrid models, with dedicated visual and textual encoders, and we show that the visual representations learned as a by-product of solving this task transfer well to a variety of target tasks. Our experiments confirm that image captions can be leveraged to inject global and localized semantic information into visual representations. Project website: https://europe.naverlabs.com/icmlm.
Dialog System Technology Challenge 7
Jan 11, 2019

This paper introduces the Seventh Dialog System Technology Challenges (DSTC), which use shared datasets to explore the problem of building dialog systems. Recently, end-to-end dialog modeling approaches have been applied to various dialog tasks. The seventh DSTC (DSTC7) focuses on developing technologies related to end-to-end dialog systems for (1) sentence selection, (2) sentence generation and (3) audio visual scene aware dialog. This paper summarizes the overall setup and results of DSTC7, including detailed descriptions of the different tracks and provided datasets. We also describe overall trends in the submitted systems and the key results. Each track introduced new datasets and participants achieved impressive results using state-of-the-art end-to-end technologies.
ReviewQA: a relational aspect-based opinion reading dataset
Oct 29, 2018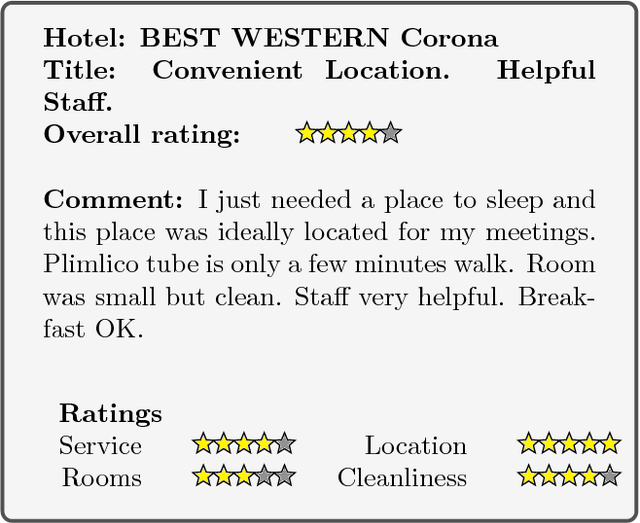
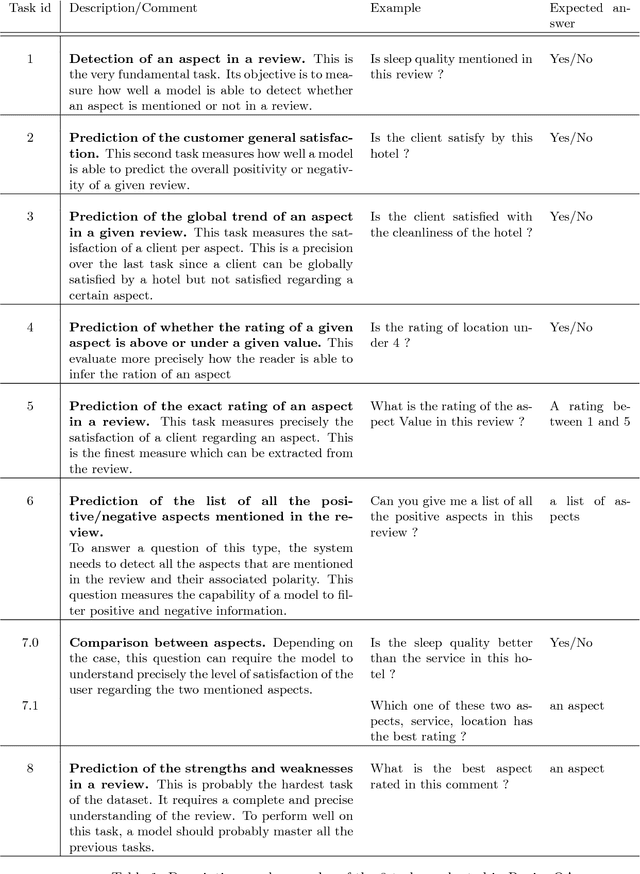
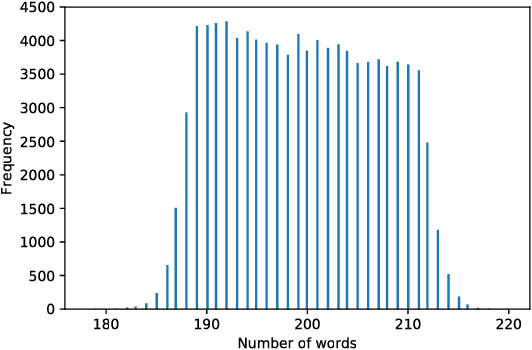
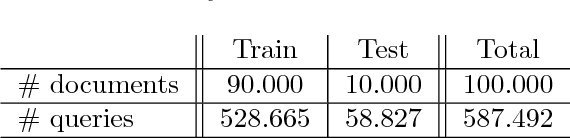
Deep reading models for question-answering have demonstrated promising performance over the last couple of years. However current systems tend to learn how to cleverly extract a span of the source document, based on its similarity with the question, instead of seeking for the appropriate answer. Indeed, a reading machine should be able to detect relevant passages in a document regarding a question, but more importantly, it should be able to reason over the important pieces of the document in order to produce an answer when it is required. To motivate this purpose, we present ReviewQA, a question-answering dataset based on hotel reviews. The questions of this dataset are linked to a set of relational understanding competencies that we expect a model to master. Indeed, each question comes with an associated type that characterizes the required competency. With this framework, it is possible to benchmark the main families of models and to get an overview of what are the strengths and the weaknesses of a given model on the set of tasks evaluated in this dataset. Our corpus contains more than 500.000 questions in natural language over 100.000 hotel reviews. Our setup is projective, the answer of a question does not need to be extracted from a document, like in most of the recent datasets, but selected among a set of candidates that contains all the possible answers to the questions of the dataset. Finally, we present several baselines over this dataset.
Non-Markovian Control with Gated End-to-End Memory Policy Networks
May 31, 2017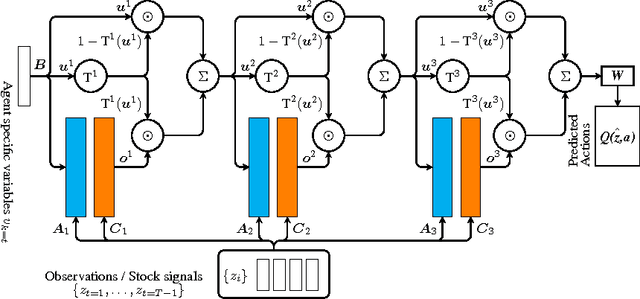
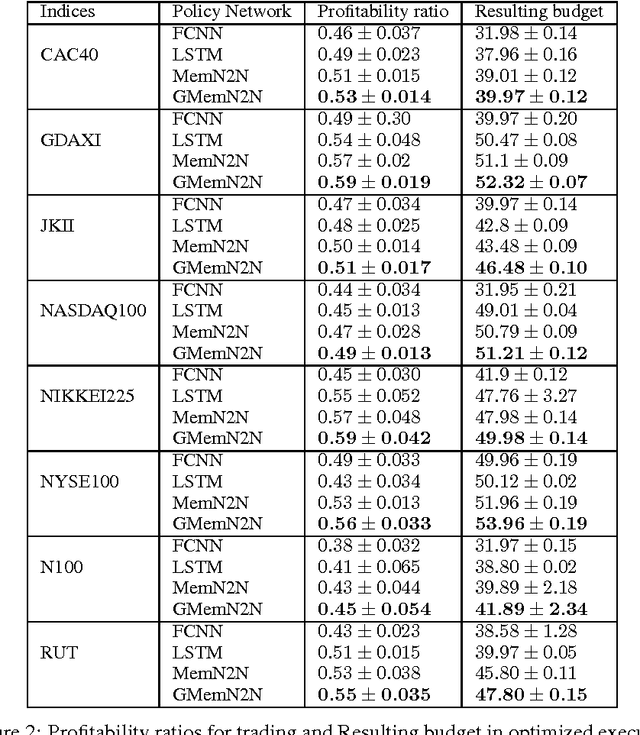
Partially observable environments present an important open challenge in the domain of sequential control learning with delayed rewards. Despite numerous attempts during the two last decades, the majority of reinforcement learning algorithms and associated approximate models, applied to this context, still assume Markovian state transitions. In this paper, we explore the use of a recently proposed attention-based model, the Gated End-to-End Memory Network, for sequential control. We call the resulting model the Gated End-to-End Memory Policy Network. More precisely, we use a model-free value-based algorithm to learn policies for partially observed domains using this memory-enhanced neural network. This model is end-to-end learnable and it features unbounded memory. Indeed, because of its attention mechanism and associated non-parametric memory, the proposed model allows us to define an attention mechanism over the observation stream unlike recurrent models. We show encouraging results that illustrate the capability of our attention-based model in the context of the continuous-state non-stationary control problem of stock trading. We also present an OpenAI Gym environment for simulated stock exchange and explain its relevance as a benchmark for the field of non-Markovian decision process learning.
Dialog state tracking, a machine reading approach using Memory Network
Mar 02, 2017


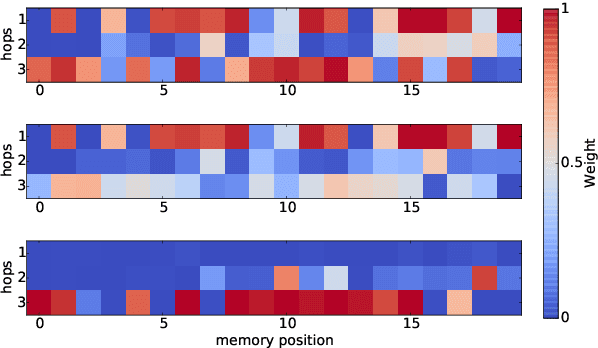
In an end-to-end dialog system, the aim of dialog state tracking is to accurately estimate a compact representation of the current dialog status from a sequence of noisy observations produced by the speech recognition and the natural language understanding modules. This paper introduces a novel method of dialog state tracking based on the general paradigm of machine reading and proposes to solve it using an End-to-End Memory Network, MemN2N, a memory-enhanced neural network architecture. We evaluate the proposed approach on the second Dialog State Tracking Challenge (DSTC-2) dataset. The corpus has been converted for the occasion in order to frame the hidden state variable inference as a question-answering task based on a sequence of utterances extracted from a dialog. We show that the proposed tracker gives encouraging results. Then, we propose to extend the DSTC-2 dataset with specific reasoning capabilities requirement like counting, list maintenance, yes-no question answering and indefinite knowledge management. Finally, we present encouraging results using our proposed MemN2N based tracking model.
Gated End-to-End Memory Networks
Nov 17, 2016


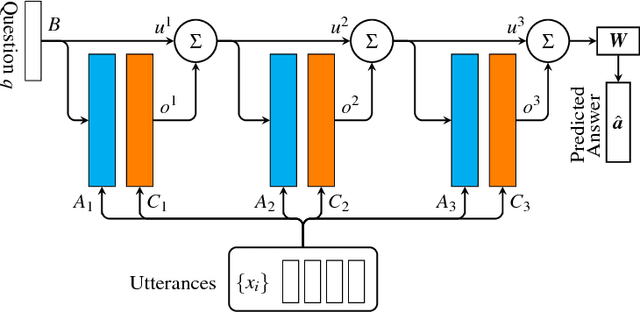
Machine reading using differentiable reasoning models has recently shown remarkable progress. In this context, End-to-End trainable Memory Networks, MemN2N, have demonstrated promising performance on simple natural language based reasoning tasks such as factual reasoning and basic deduction. However, other tasks, namely multi-fact question-answering, positional reasoning or dialog related tasks, remain challenging particularly due to the necessity of more complex interactions between the memory and controller modules composing this family of models. In this paper, we introduce a novel end-to-end memory access regulation mechanism inspired by the current progress on the connection short-cutting principle in the field of computer vision. Concretely, we develop a Gated End-to-End trainable Memory Network architecture, GMemN2N. From the machine learning perspective, this new capability is learned in an end-to-end fashion without the use of any additional supervision signal which is, as far as our knowledge goes, the first of its kind. Our experiments show significant improvements on the most challenging tasks in the 20 bAbI dataset, without the use of any domain knowledge. Then, we show improvements on the dialog bAbI tasks including the real human-bot conversion-based Dialog State Tracking Challenge (DSTC-2) dataset. On these two datasets, our model sets the new state of the art.