 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVelocity Potential Neural Field for Efficient Ambisonics Impulse Response Modeling
Mar 23, 2026First-order Ambisonics (FOA) is a standard spatial audio format based on spherical harmonic decomposition. Its zeroth- and first-order components capture the sound pressure and particle velocity, respectively. Recently, physics-informed neural networks have been applied to the spatial interpolation of FOA signals, regularizing the network outputs based on soft penalty terms derived from physical principles, e.g., the linearized momentum equation. In this paper, we reformulate the task so that the predicted FOA signal automatically satisfies the linearized momentum equation. Our network approximates a scalar function called velocity potential, rather than the FOA signal itself. Then, the FOA signal can be readily recovered through the partial derivatives of the velocity potential with respect to the network inputs (i.e., time and microphone position) according to physics of sound propagation. By deriving the four channels of FOA from the single-channel velocity potential, the reconstructed signal follows the physical principle at any time and position by construction. Experimental results on room impulse response reconstruction confirm the effectiveness of the proposed framework.
Factorized RVQ-GAN For Disentangled Speech Tokenization
Jun 18, 2025We propose Hierarchical Audio Codec (HAC), a unified neural speech codec that factorizes its bottleneck into three linguistic levels-acoustic, phonetic, and lexical-within a single model. HAC leverages two knowledge distillation objectives: one from a pre-trained speech encoder (HuBERT) for phoneme-level structure, and another from a text-based encoder (LaBSE) for lexical cues. Experiments on English and multilingual data show that HAC's factorized bottleneck yields disentangled token sets: one aligns with phonemes, while another captures word-level semantics. Quantitative evaluations confirm that HAC tokens preserve naturalness and provide interpretable linguistic information, outperforming single-level baselines in both disentanglement and reconstruction quality. These findings underscore HAC's potential as a unified discrete speech representation, bridging acoustic detail and lexical meaning for downstream speech generation and understanding tasks.
NIIRF: Neural IIR Filter Field for HRTF Upsampling and Personalization
Feb 27, 2024



Head-related transfer functions (HRTFs) are important for immersive audio, and their spatial interpolation has been studied to upsample finite measurements. Recently, neural fields (NFs) which map from sound source direction to HRTF have gained attention. Existing NF-based methods focused on estimating the magnitude of the HRTF from a given sound source direction, and the magnitude is converted to a finite impulse response (FIR) filter. We propose the neural infinite impulse response filter field (NIIRF) method that instead estimates the coefficients of cascaded IIR filters. IIR filters mimic the modal nature of HRTFs, thus needing fewer coefficients to approximate them well compared to FIR filters. We find that our method can match the performance of existing NF-based methods on multiple datasets, even outperforming them when measurements are sparse. We also explore approaches to personalize the NF to a subject and experimentally find low-rank adaptation to be effective.
Interactive Planning Using Large Language Models for Partially Observable Robotics Tasks
Dec 11, 2023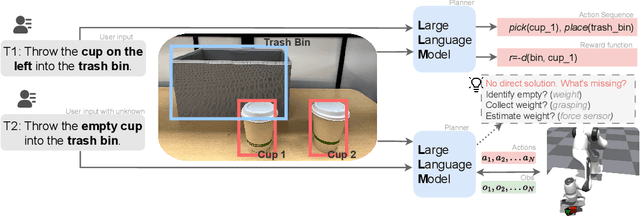



Designing robotic agents to perform open vocabulary tasks has been the long-standing goal in robotics and AI. Recently, Large Language Models (LLMs) have achieved impressive results in creating robotic agents for performing open vocabulary tasks. However, planning for these tasks in the presence of uncertainties is challenging as it requires \enquote{chain-of-thought} reasoning, aggregating information from the environment, updating state estimates, and generating actions based on the updated state estimates. In this paper, we present an interactive planning technique for partially observable tasks using LLMs. In the proposed method, an LLM is used to collect missing information from the environment using a robot and infer the state of the underlying problem from collected observations while guiding the robot to perform the required actions. We also use a fine-tuned Llama 2 model via self-instruct and compare its performance against a pre-trained LLM like GPT-4. Results are demonstrated on several tasks in simulation as well as real-world environments. A video describing our work along with some results could be found here.
Scenario-Aware Audio-Visual TF-GridNet for Target Speech Extraction
Oct 30, 2023



Target speech extraction aims to extract, based on a given conditioning cue, a target speech signal that is corrupted by interfering sources, such as noise or competing speakers. Building upon the achievements of the state-of-the-art (SOTA) time-frequency speaker separation model TF-GridNet, we propose AV-GridNet, a visual-grounded variant that incorporates the face recording of a target speaker as a conditioning factor during the extraction process. Recognizing the inherent dissimilarities between speech and noise signals as interfering sources, we also propose SAV-GridNet, a scenario-aware model that identifies the type of interfering scenario first and then applies a dedicated expert model trained specifically for that scenario. Our proposed model achieves SOTA results on the second COG-MHEAR Audio-Visual Speech Enhancement Challenge, outperforming other models by a significant margin, objectively and in a listening test. We also perform an extensive analysis of the results under the two scenarios.
Generation or Replication: Auscultating Audio Latent Diffusion Models
Oct 16, 2023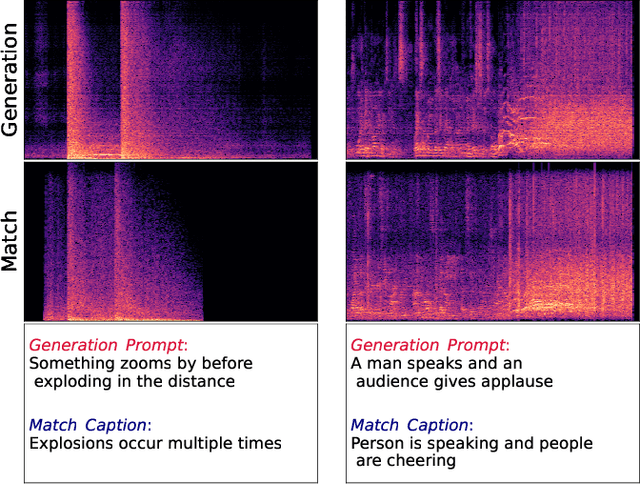
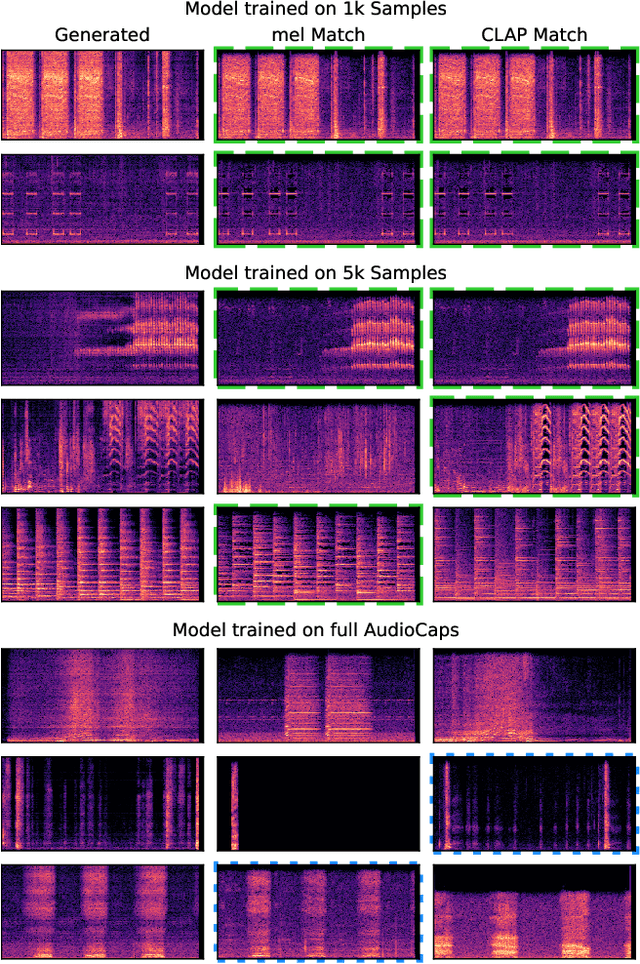
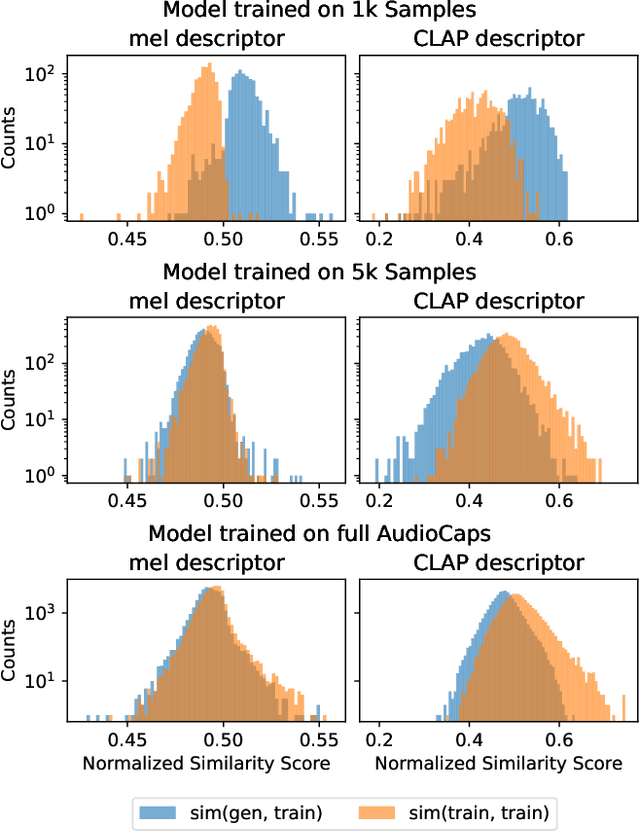
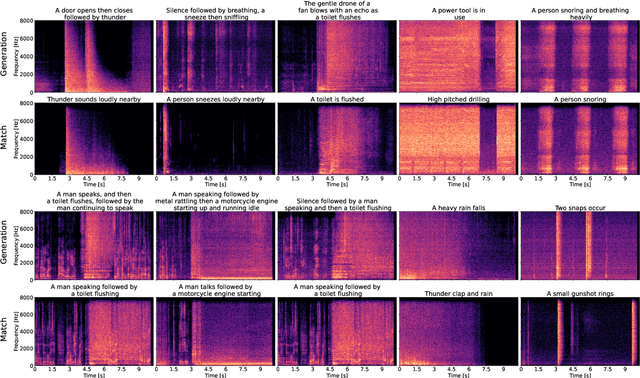
The introduction of audio latent diffusion models possessing the ability to generate realistic sound clips on demand from a text description has the potential to revolutionize how we work with audio. In this work, we make an initial attempt at understanding the inner workings of audio latent diffusion models by investigating how their audio outputs compare with the training data, similar to how a doctor auscultates a patient by listening to the sounds of their organs. Using text-to-audio latent diffusion models trained on the AudioCaps dataset, we systematically analyze memorization behavior as a function of training set size. We also evaluate different retrieval metrics for evidence of training data memorization, finding the similarity between mel spectrograms to be more robust in detecting matches than learned embedding vectors. In the process of analyzing memorization in audio latent diffusion models, we also discover a large amount of duplicated audio clips within the AudioCaps database.
Style-transfer based Speech and Audio-visual Scene Understanding for Robot Action Sequence Acquisition from Videos
Jun 27, 2023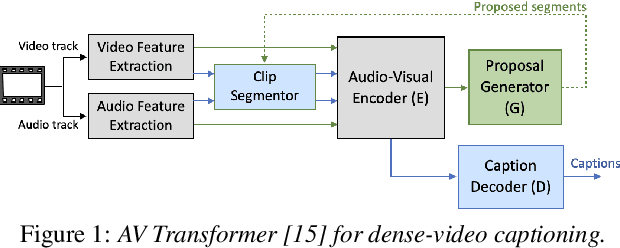

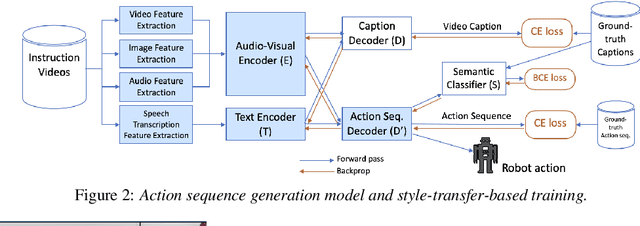
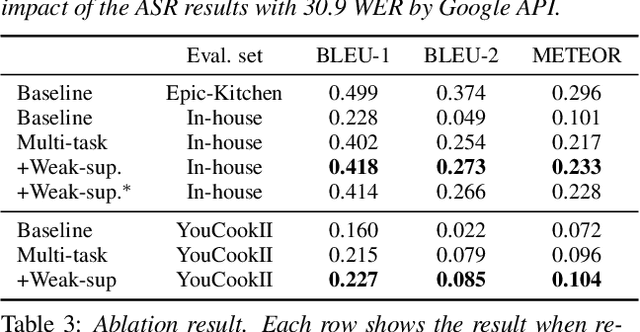
To realize human-robot collaboration, robots need to execute actions for new tasks according to human instructions given finite prior knowledge. Human experts can share their knowledge of how to perform a task with a robot through multi-modal instructions in their demonstrations, showing a sequence of short-horizon steps to achieve a long-horizon goal. This paper introduces a method for robot action sequence generation from instruction videos using (1) an audio-visual Transformer that converts audio-visual features and instruction speech to a sequence of robot actions called dynamic movement primitives (DMPs) and (2) style-transfer-based training that employs multi-task learning with video captioning and weakly-supervised learning with a semantic classifier to exploit unpaired video-action data. We built a system that accomplishes various cooking actions, where an arm robot executes a DMP sequence acquired from a cooking video using the audio-visual Transformer. Experiments with Epic-Kitchen-100, YouCookII, QuerYD, and in-house instruction video datasets show that the proposed method improves the quality of DMP sequences by 2.3 times the METEOR score obtained with a baseline video-to-action Transformer. The model achieved 32% of the task success rate with the task knowledge of the object.
D Spatio-Temporal Scene Graphs for Video Question Answering
Feb 18, 2022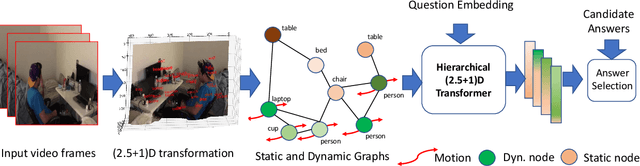
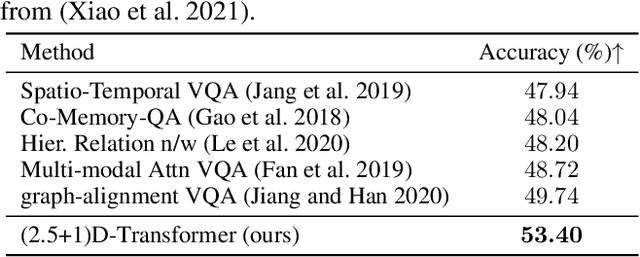
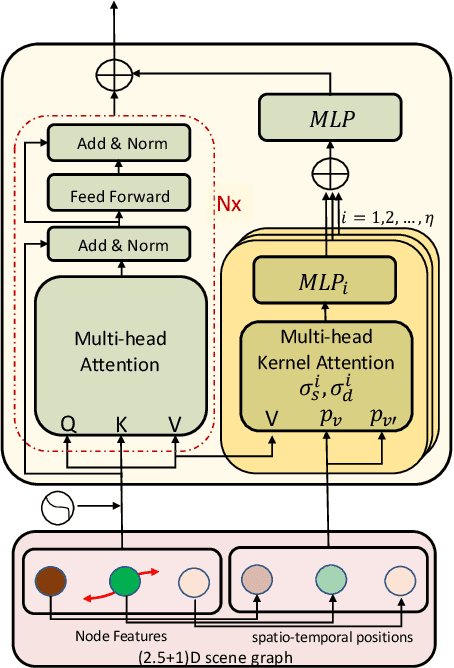
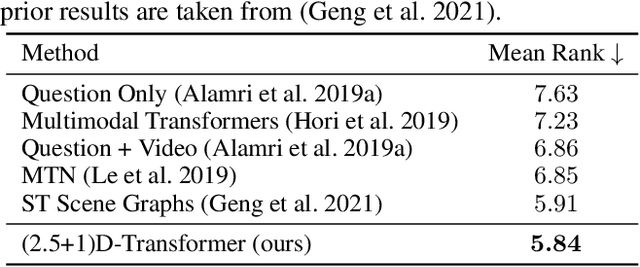
Spatio-temporal scene-graph approaches to video-based reasoning tasks such as video question-answering (QA) typically construct such graphs for every video frame. Such approaches often ignore the fact that videos are essentially sequences of 2D "views" of events happening in a 3D space, and that the semantics of the 3D scene can thus be carried over from frame to frame. Leveraging this insight, we propose a (2.5+1)D scene graph representation to better capture the spatio-temporal information flows inside the videos. Specifically, we first create a 2.5D (pseudo-3D) scene graph by transforming every 2D frame to have an inferred 3D structure using an off-the-shelf 2D-to-3D transformation module, following which we register the video frames into a shared (2.5+1)D spatio-temporal space and ground each 2D scene graph within it. Such a (2.5+1)D graph is then segregated into a static sub-graph and a dynamic sub-graph, corresponding to whether the objects within them usually move in the world. The nodes in the dynamic graph are enriched with motion features capturing their interactions with other graph nodes. Next, for the video QA task, we present a novel transformer-based reasoning pipeline that embeds the (2.5+1)D graph into a spatio-temporal hierarchical latent space, where the sub-graphs and their interactions are captured at varied granularity. To demonstrate the effectiveness of our approach, we present experiments on the NExT-QA and AVSD-QA datasets. Our results show that our proposed (2.5+1)D representation leads to faster training and inference, while our hierarchical model showcases superior performance on the video QA task versus the state of the art.
Audio-Visual Scene-Aware Dialog and Reasoning using Audio-Visual Transformers with Joint Student-Teacher Learning
Oct 13, 2021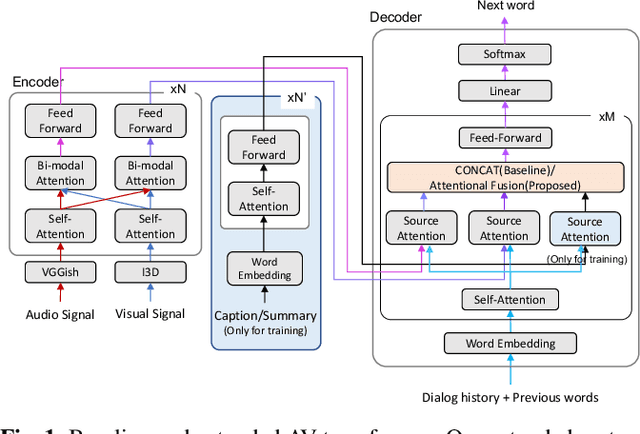
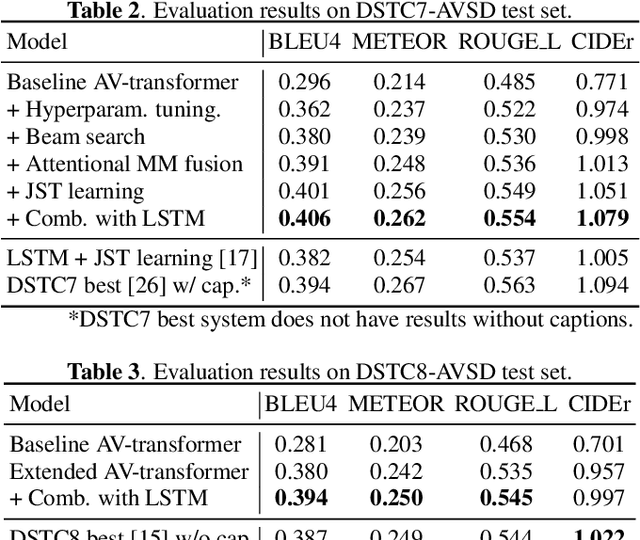
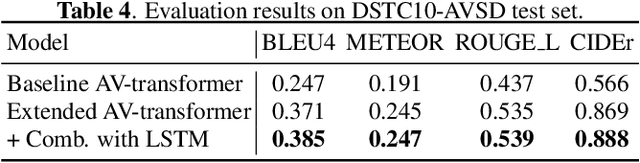
In previous work, we have proposed the Audio-Visual Scene-Aware Dialog (AVSD) task, collected an AVSD dataset, developed AVSD technologies, and hosted an AVSD challenge track at both the 7th and 8th Dialog System Technology Challenges (DSTC7, DSTC8). In these challenges, the best-performing systems relied heavily on human-generated descriptions of the video content, which were available in the datasets but would be unavailable in real-world applications. To promote further advancements for real-world applications, we proposed a third AVSD challenge, at DSTC10, with two modifications: 1) the human-created description is unavailable at inference time, and 2) systems must demonstrate temporal reasoning by finding evidence from the video to support each answer. This paper introduces the new task that includes temporal reasoning and our new extension of the AVSD dataset for DSTC10, for which we collected human-generated temporal reasoning data. We also introduce a baseline system built using an AV-transformer, which we released along with the new dataset. Finally, this paper introduces a new system that extends our baseline system with attentional multimodal fusion, joint student-teacher learning (JSTL), and model combination techniques, achieving state-of-the-art performances on the AVSD datasets for DSTC7, DSTC8, and DSTC10. We also propose two temporal reasoning methods for AVSD: one attention-based, and one based on a time-domain region proposal network.
Optimizing Latency for Online Video CaptioningUsing Audio-Visual Transformers
Aug 04, 2021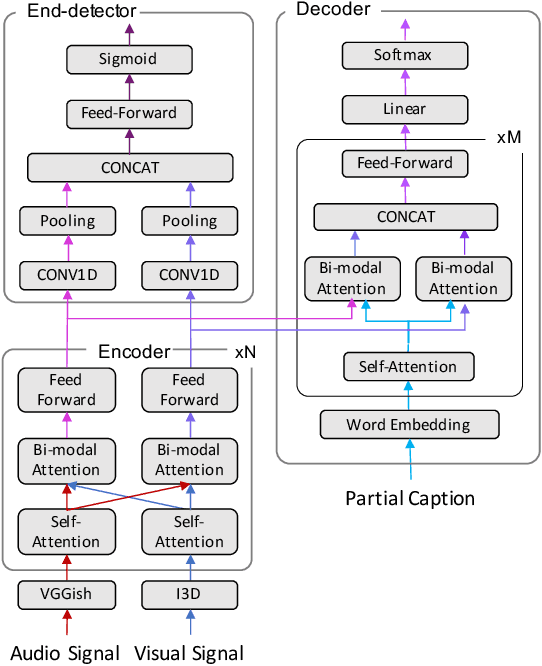
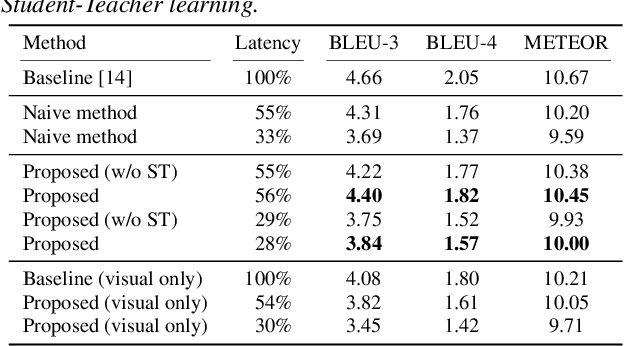
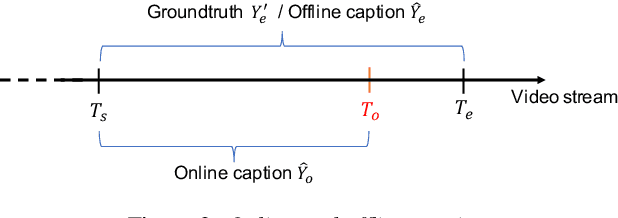
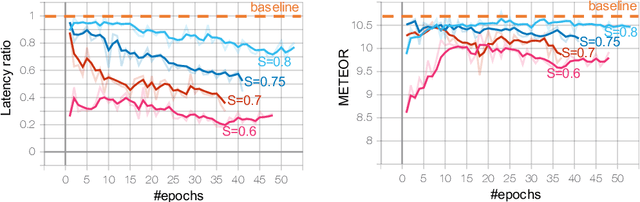
Video captioning is an essential technology to understand scenes and describe events in natural language. To apply it to real-time monitoring, a system needs not only to describe events accurately but also to produce the captions as soon as possible. Low-latency captioning is needed to realize such functionality, but this research area for online video captioning has not been pursued yet. This paper proposes a novel approach to optimize each caption's output timing based on a trade-off between latency and caption quality. An audio-visual Trans-former is trained to generate ground-truth captions using only a small portion of all video frames, and to mimic outputs of a pre-trained Transformer to which all the frames are given. A CNN-based timing detector is also trained to detect a proper output timing, where the captions generated by the two Trans-formers become sufficiently close to each other. With the jointly trained Transformer and timing detector, a caption can be generated in the early stages of an event-triggered video clip, as soon as an event happens or when it can be forecasted. Experiments with the ActivityNet Captions dataset show that our approach achieves 94% of the caption quality of the upper bound given by the pre-trained Transformer using the entire video clips, using only 28% of frames from the beginning.