 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Latency for Online Video CaptioningUsing Audio-Visual Transformers
Paper and Code
Aug 04, 2021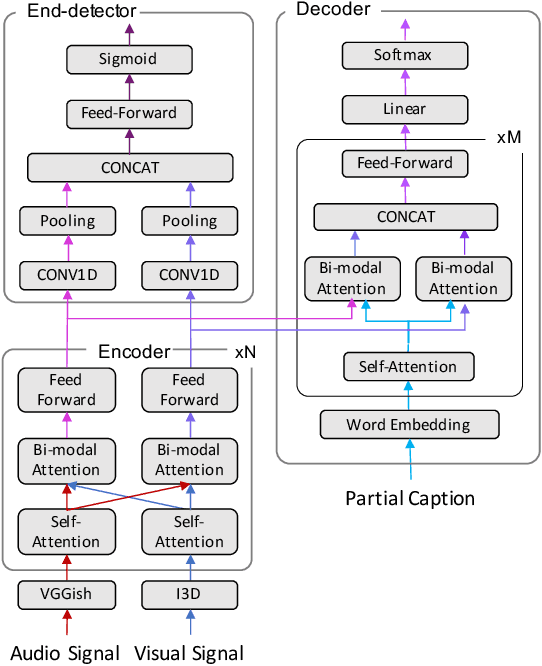
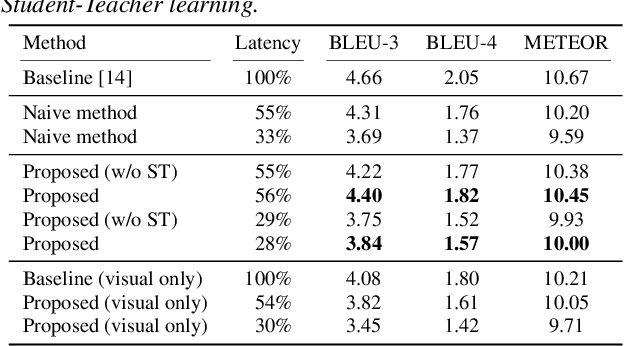
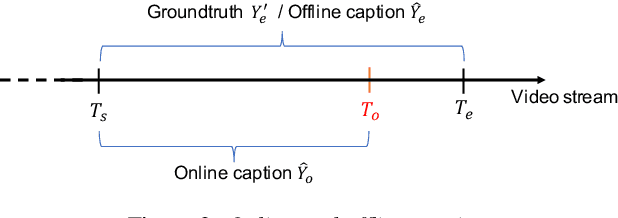
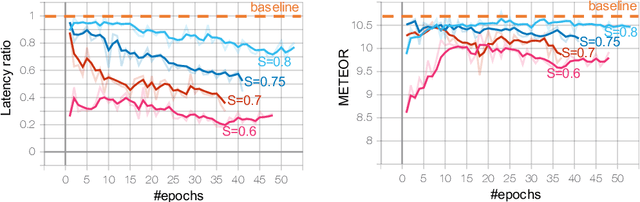
Video captioning is an essential technology to understand scenes and describe events in natural language. To apply it to real-time monitoring, a system needs not only to describe events accurately but also to produce the captions as soon as possible. Low-latency captioning is needed to realize such functionality, but this research area for online video captioning has not been pursued yet. This paper proposes a novel approach to optimize each caption's output timing based on a trade-off between latency and caption quality. An audio-visual Trans-former is trained to generate ground-truth captions using only a small portion of all video frames, and to mimic outputs of a pre-trained Transformer to which all the frames are given. A CNN-based timing detector is also trained to detect a proper output timing, where the captions generated by the two Trans-formers become sufficiently close to each other. With the jointly trained Transformer and timing detector, a caption can be generated in the early stages of an event-triggered video clip, as soon as an event happens or when it can be forecasted. Experiments with the ActivityNet Captions dataset show that our approach achieves 94% of the caption quality of the upper bound given by the pre-trained Transformer using the entire video clips, using only 28% of frames from the beginning.